Hi @Luca_Italy.
I can see why your rule didn’t find the zeroes. You were “pattern matching” against “0”. Pattern matching performs comparisons between strings rather than numbers, and so to perform the request, it will have executed a java “toString()” method against the Double, which would result in it creating a string “0.0”. This is java’s string representation of zero when held as a Double.
As this is numeric data, you really needed to use the “range checking” in the Row Filter, and test with a lower and upper bound of 0. Then it would have worked with 0. I agree that this isn’t immediately obvious, and is what I would perhaps term a “gotcha” as it can catch people out, but hopefully explains the behaviour.
Re your notes on whether there is a bug in Math Formula, I agree that there are potentially issues with the implementation, but it doesn’t surprise me greatly though that the Math Formula node should create a Double by default, as ultimately this gives it the greatest range of values (64 bit) and flexibility to cope with mathematical formulas, without having to provide additional logic that determined every function, mathematical expression and datatype that has been used, and then decide whether an Integer or Floating point data type could have handled it. That would be very difficult to write, and prone to other errors. (Also, it has to work consistently across all the rows. It cannot be returning an Int for one row, and then a Double for another, so ultimately only you can know what data type you are really wanting from the result across your entire data set)
Instead, a pragmatic solution I think was to provide the “Convert to Int” option, so possibly if you are expecting the result to be an integer, and it is important that it is, then ticking the box ought to be the answer.
However, there is one big problem I see with the implementation. It’s that if you tick “Convert to Int”, it does exactly what it says, and converts to the Int datatype (32 bit), and not just an integer version of a double (64 bit) data type (which would actually be a Long. So if the result of your calculation is outside of the range
-2,147,483,648 to 2,147,483,647
it will result in an unknown (missing) value, and you don’t get any errors or warnings flagged that there has been an “arithmetic overflow” situation. I hadn’t realised that until I experimented as a result of your question. [Edit: although now I’ve gone looking at the help for Math Formula I can see this is mentioned in passing in the body text but not against the “Convert to Int” check box]
I would have preferred that it gave the option of Convert to Long too, rather than reducing the available “bit width” of the result.
So, if you are expecting the result to be an Integer and it is within the above range, then I would say you should tick the Convert to Int box.
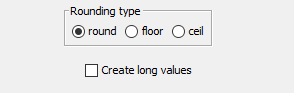
However, if it should be an integer but is outside of the range (i.e. it should be a Long), then I think you should let this return a Double and then immediately follow it with a Double to Int node which not only allows you to create Long values, but also gives you control over the mechanism used for rounding.
I hope that helps.