Hello fellow Knime users,
I have the following question:
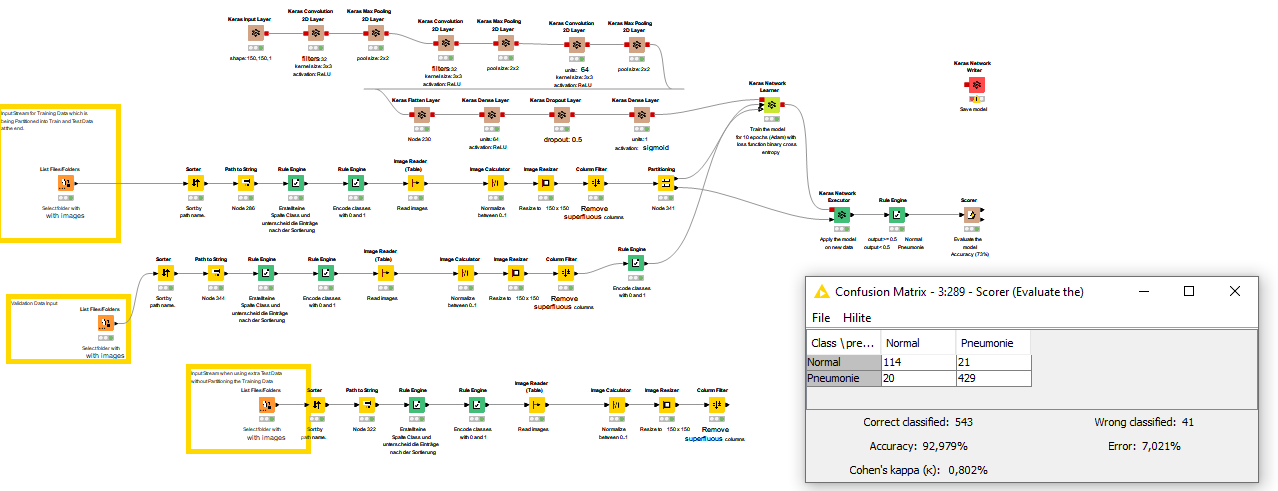
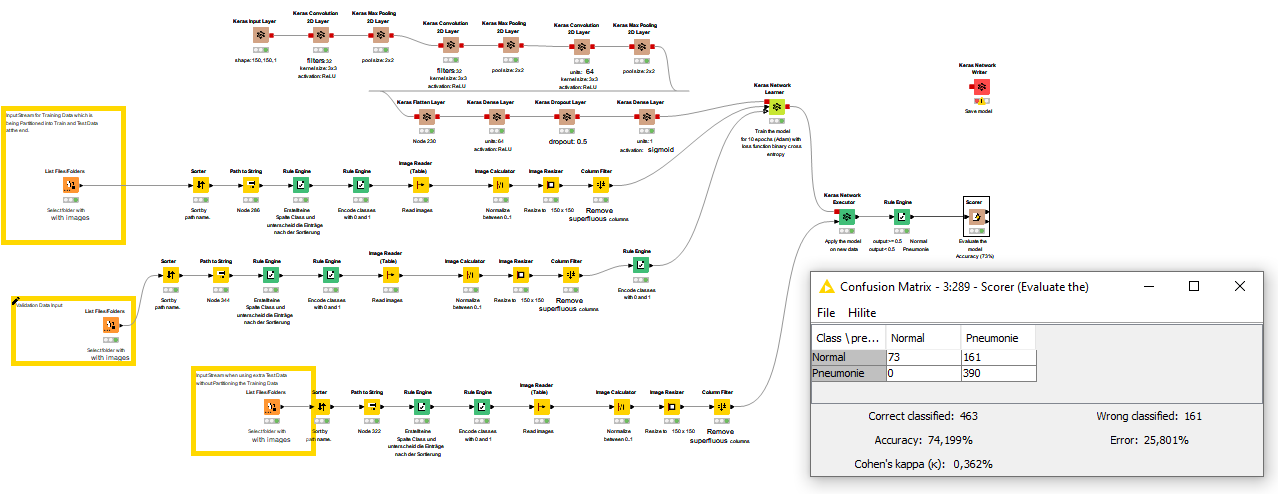
I am using a flow for image classification (I will post a picture of the flows) and have found that I get different results depending on how the test data is added.
Using a large dataset and splitting it into test and training data I get very precise results.
However, when I use a new test data set I get 25% worse results.
Can anyone here explain to me why?
I tried training the models for longer time but it didn’t really help.