Hello KNIME Community,
I am encountering a significant discrepancy in the performance of an XGBoost model when trained using KNIME versus Python. Despite using identical parameters, seed values, and the same data, the model’s accuracy in KNIME is 78%, whereas in Python, it is only 52%.
Here are the specific details:
- Algorithm: XGBoost
- Parameters:
Python’s parameters
eta= 0.3 ,
reg_lambda= 1,
reg_alpha= 1,
gamma= 0,
max_delta_step=0,
booster=‘gbtree’,
max_depth= 6,
min_child_weight= 1,
tree_method=‘auto’,
sketch_eps= 0.03,
scale_pos_weight=1,
grow_policy=‘depthwise’,
max_leaves=0,
max_bin=256,
subsample= 1,
colsample_bytree=1,
colsample_bylevel=1,
colsample_bynode=1,
objective= “multi:softmax”,
enable_categorical=True,
n_estimators= 250,
base_score=0.5,
random_state=100,
eval_metric= ‘logloss’,
KNIME’s:
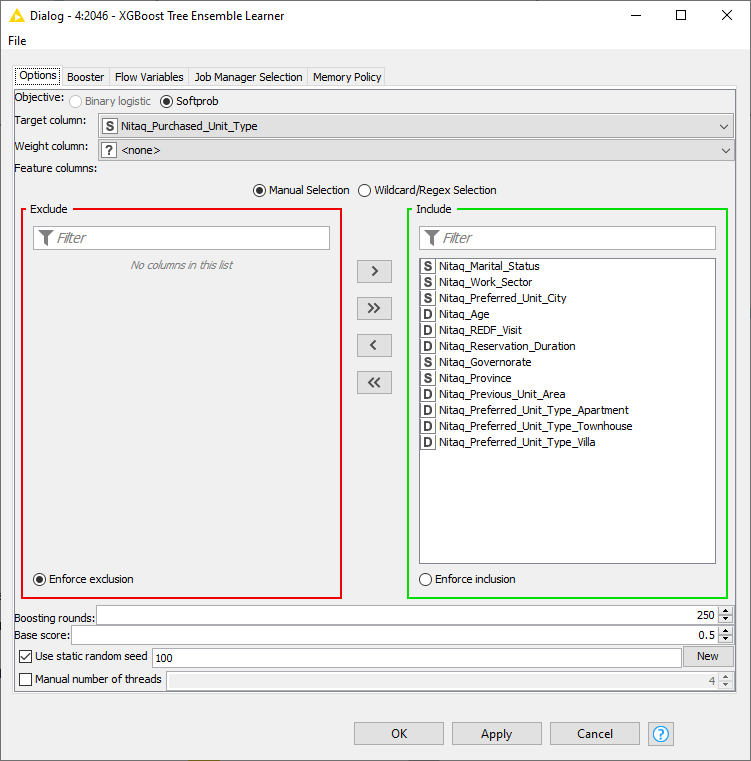
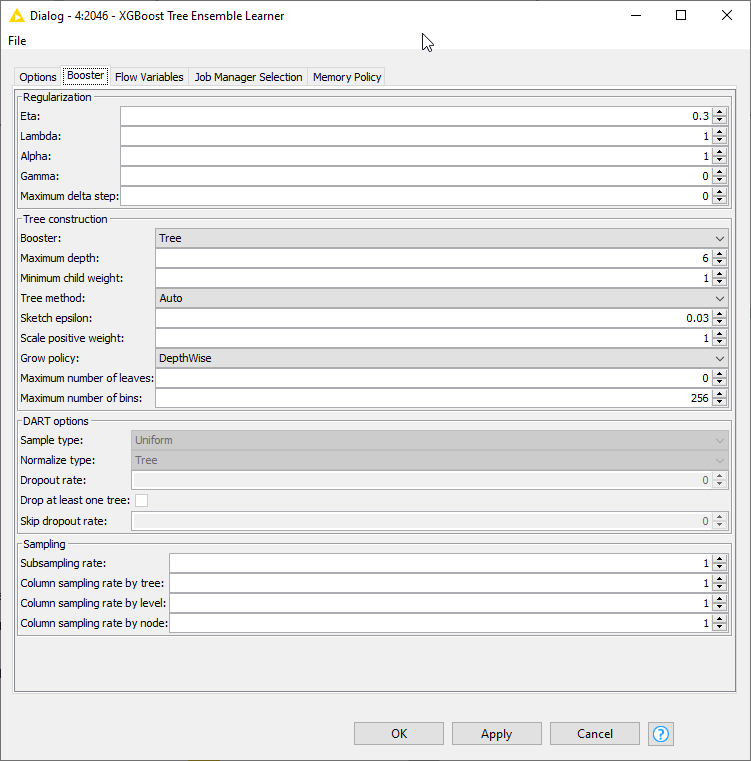
I am curious if anyone else has experienced similar differences in results and if there might be any underlying reasons for this disparity. Any insights or suggestions for troubleshooting would be greatly appreciated.
Thank you!