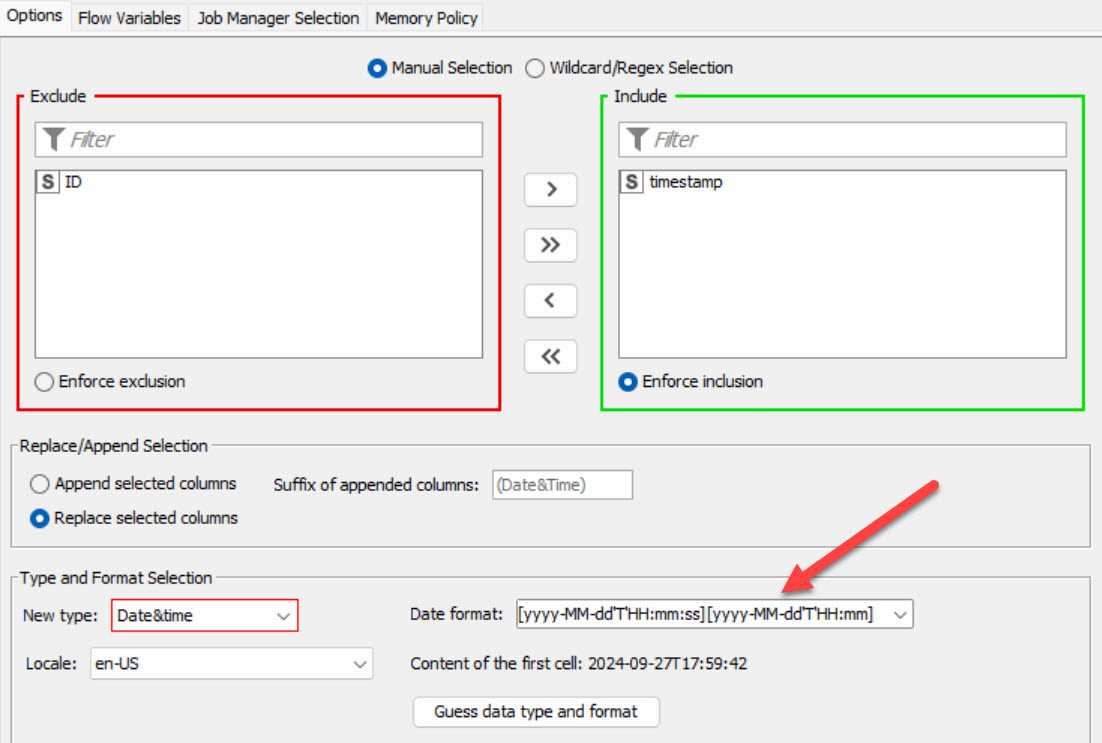
→ My goal is to identify the time difference from the same object No. which need to be added as a seperate column and connected with the rest of the columns.
(Not possible when I have more timestamps in between)
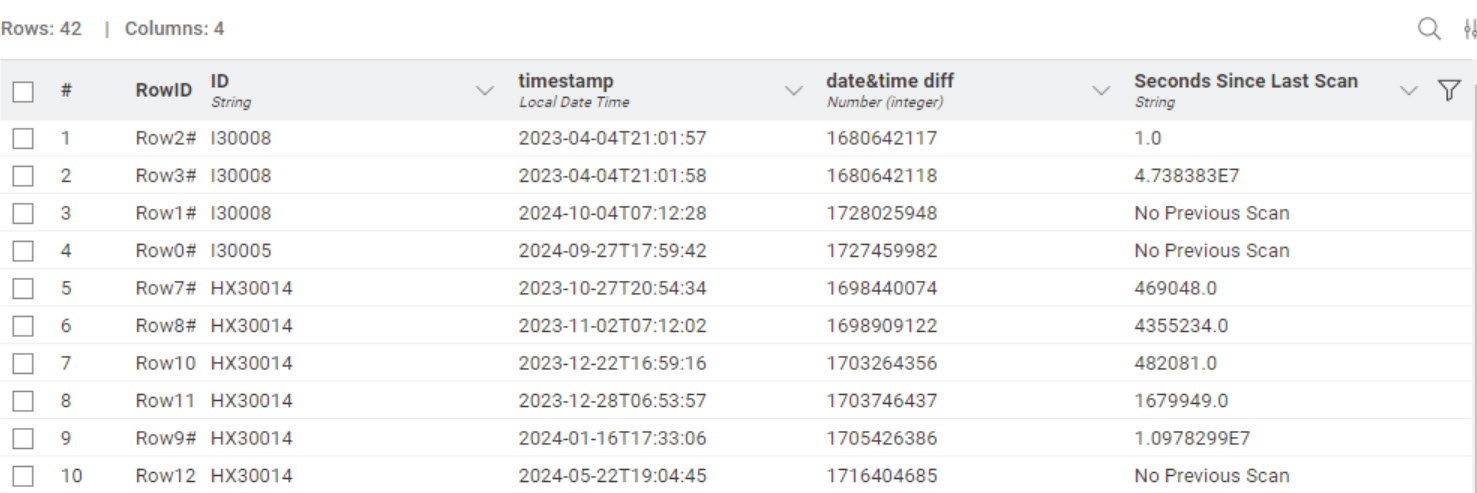
I’m not entirely clear about what you want. Take a look at this. It flags a scan when there was no previous one. The only tricky thing was your timestamps weren’t all the same. One was missing seconds so the String to DateTime node had to be adjusted accordingly. Also the timestamps aren’t sorted. I used UNIX timestamps to calculate the difference in seconds between scans. Time distance same column different ID.knwf (118.0 KB)
I think this is indeed the way forward, but with 20.000 unique ID’s it takes quite some time to be processed via the Group loop, do I need to split the data in multiple Group loops? & I want to change the ‘No previous scan’ with the difference between timestamp VS current day&time.
Could it be simplified in column expressions without the group loop start?
Thought:
Sort ID + Sort date&time
Generate Time difference between previous ROW & ID
IF ID = same as ID (previous row) => time difference between row
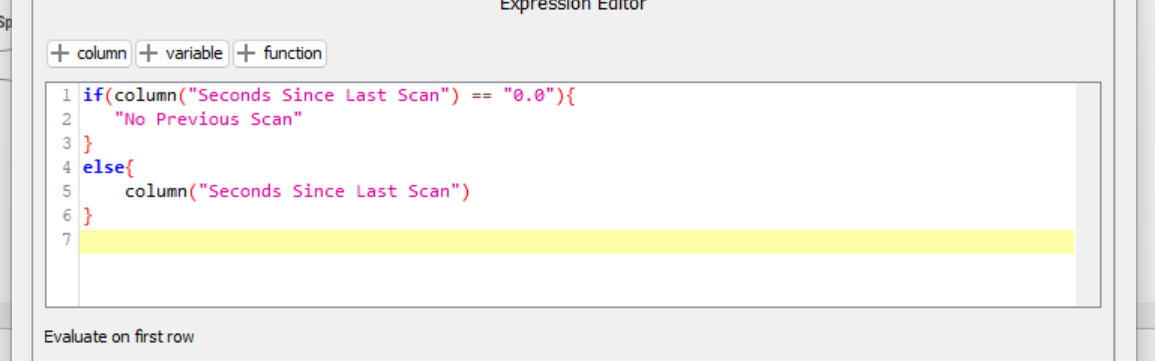
AND IF ID = not same as ID (previous or next) row => “No previous scan”
Extra question: Can we define “no previous scan” as the time difference as of today. That would give me the estimation that it is not changed for a long time.
I’m sorry but I have no clue about what you’re doing. If you want to share the entire workflow, I’ll take a look. In the meantime, try this. I think it does what you want but still uses a loop. I’ll give some thought about eliminating the loop although I don’t think its straightforward. Time distance same column different ID rev 1.knwf (153.1 KB)
Here’s a workflow without the loop. Time distance same column different ID rev 2.knwf (141.1 KB)