I’m trying to convert some pivot tables (Excel) into Knime using Groupby nodes. The problem is that when I use Unique count (Knime), I get a lower number per category than using distinct count in Excel.
Anyone knows - is there a different logic between the two?
Could it be, that if a string value was already assigned to some other category (in Knime) - it doesn’t count it, if it appears in another (lower) one? In a sense, it goes from top to bottom and only counts it once and assigns it to the first category?
Any help is much appreciated! Wish everyone a nice day!
Without any details about your data it will be quite difficult to give you some qualified answer answer.
So maybe you can share the data sample (both the source data and the expected result) with us. If required you may of course anonymise the dataset.
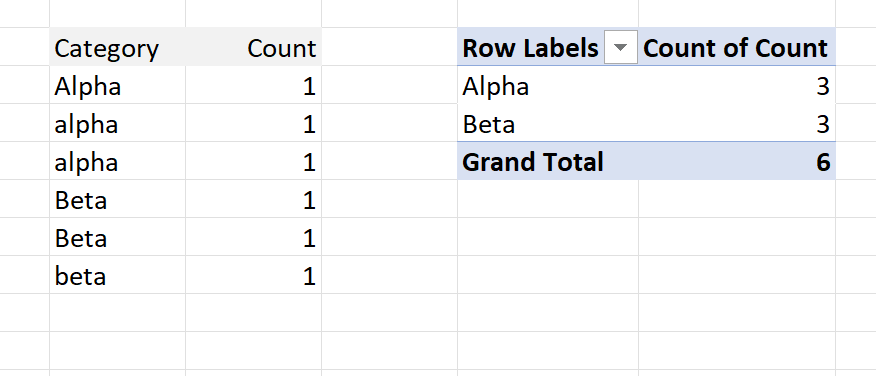
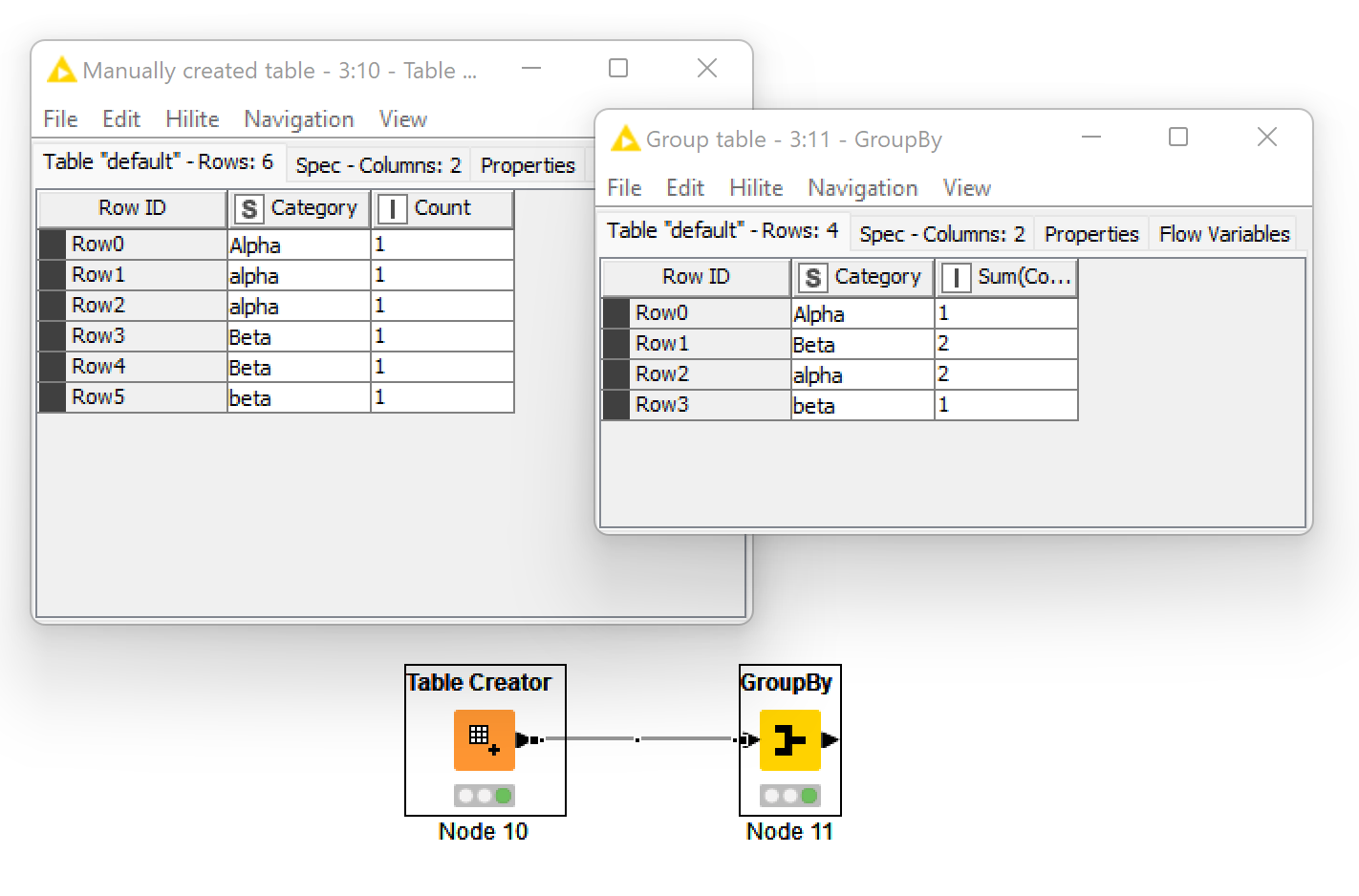
Microsoft products are typically case insensitive when collating categories, therefore, Alpha is the same as alpha. There is usually a way to over-ride this but it varies from product to product and most people are unaware of the base assumption being made. That is until the workflow is moved to another platform which is case-sensitive (such as KNIME and many non-Microsoft products). In this case Alpha is not the same as alpha. Data problems do occur when switching from Microsoft to non-Microsoft products and vice-versa. It is not just Excel, it can affect switching between different database platforms (e.g PostgreSQL and SQL Server) if you don’t check whether comparisons should be case sensitive or insensitive.
The following examples demonstrate the difference between a pivot-table in Microsoft Excel and a GroupBy node in KNIME. You may want to check your data to see whether there are differences in case. Other potential causes, though less common, are different handling of non-printing white spaces and handling of leading/trailing white space.