Tengo un base datos con 50 registros asignados a 2 personas (total 100 registros), quiero realizar un distinguir o eliminar duplicados pero que el resultado sean 50 registros entre las 2 personas, al usar el nodo DUPLICATE ROW FILTER le pone los 50 solo a una persona, asi no me sirve.
Hi @cagi7989 , it could be that you either configure the node wrongly or your workflow needs to be revised.
Hard to help without any screenshots. But it’d be better if you upload your workflow in this case.
1 Like
Adjunto el Work Flow para su ayuda.
Distinguir.knwf (21.5 KB)
Okay, here’s how you have set up the node’s configuration:
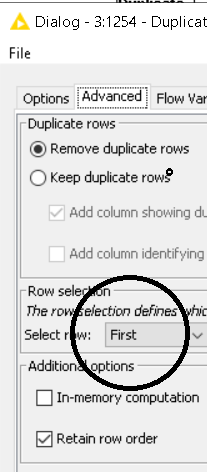
Because you have selected the first row, and your target is the ID column, what the node does is that it keeps only the first row where a specific ID exists. The other rows containing the same ID (duplicates) are removed.
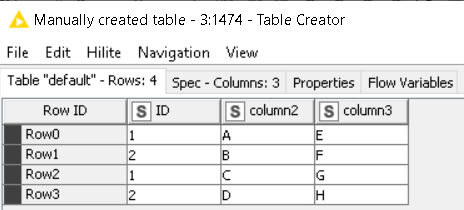
To illustrate the effects of your configuration:
INPUT
OUTPUT
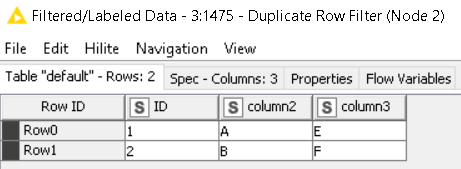
To be clear, I’m not proposing a solution (yet). I merely illustrated to you what’s going on.
Can you use the same table I showed here to illustrate what outcome you want? If you explain it in words, I’m afraid some things will be lost in translation.
Thank you.
1 Like
En la opcion avanzado del nodo DUPLICATE ROW FILTER, solo puedo elegir primera o ultima, no tengo otra opción. Segun la tabla que ud me muestra como podría ser el resultado asi:
ID - Column2 - Colum3
1 - A - E
2 - D - H
Thanks your your reply @cagi7989 .
Based on the info you shared here and looking at your table in the workflow, I can deduce that this isn’t a job for the Duplicate Row Filter node. I would go for a different workaround for your case.
Let’s take a step back and relook at your raw data, where you have a table of 200 rows and can be divided into 4 groups of column ID’s, where every 50 rows going from the top of the Column ID belong to one group. Let’s name them in this order: Group 0, Group 1, Group 2 and Group 3.
Looking at the ID numbers, it looks like Group 0 is the counterpart for Group 1, and Group 2 is the counterpart for Group 3. When you used the Duplicate Row Filter, it removed Group 1 since its column IDs are the duplicates for Group 0, and it also removed Group 3 since its column IDs are the duplicates for Group 2. You were left with only Group 0 and Group 2.
If I understand you right, what you want is Group 0 and Group 3 instead. For this, you can simply use the simple Row Filter Node to remove specific rows within the range that you specified. You can’t use the Duplicate Row Filter for your purpose.
Other than simply using the simple Row Filter by itself, a more elegant approach is also possible by integrating Loops in the workflow:

What this does is it assigns rows to groups, and uses the Iteration Numbers as your Group Names. Then the Row Filter simply removes which group you want to be removed without the need to manually specify the row range. This gives you a better control of removing rows in any way you want, as long as each group of rows is fixed to 50.
Here’s the workflow:
Distinguir.knwf (27.9 KB)
1 Like
Asi no es como lo necesito, en el flujo de trabajo que me enviaste. El flujo asigna 50 registro a un mismo usuario y otros 50 a otro usuario. Lo que necesito es lo siguiente: El archivo tiene 2 zonas (502, 508) cada zona tiene dos usuario, cada zona tiene 50 ID que están asignados a los 2 Usuarios, por lo cual se repiten los 50 entre los 2 usuario, la idea es que al quitar los duplicados me queden registros asignador entre los 2 usuarios de la misma zona, no que todos queden en un solo usuario. Adjunto archivo como necesito el resultado.
Resultado.xlsx (10.1 KB)
Hi @cagi7989 , I’ll pass this on to users who can speak your language. Maybe @aworker can help continue the discussion?
Wish you all the best & hope you found the correct solution!
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.