Hi @MapperKnime,
ahh, a mathematical problem. I love crunching numbers …
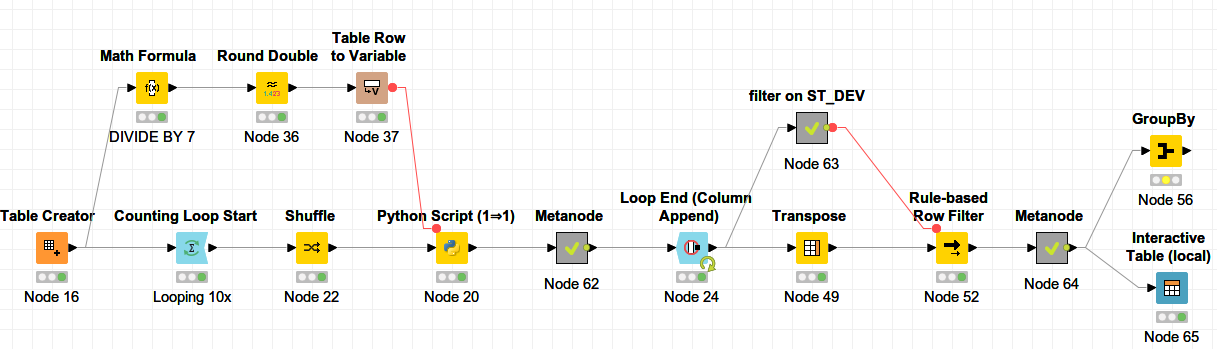
I’ve done a quick test and must say it is a very interesting challenge. I try to formulate it first as abstract as possible and a possible workflow.
Challenge
You’d like to equally distribute something but not have equal amounts of everything. So it is an approximation challenge.
Optimal scenario
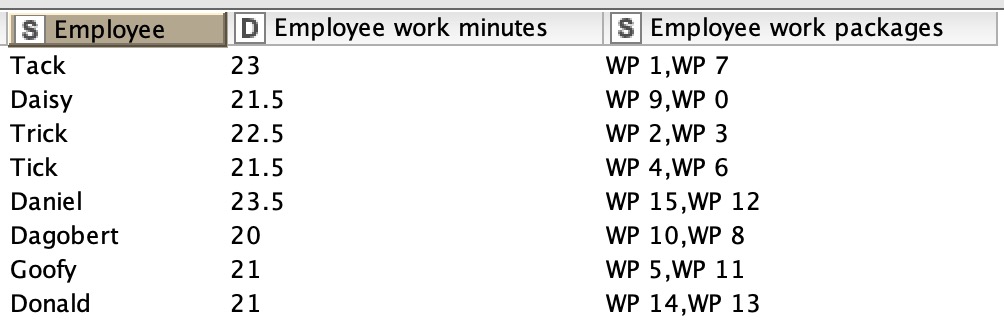
Though, we first assume, the best scenario: Sum of minutes and count of work items can be perfectly divided by number of employees. Then doing simple math helps as you might imagine.
Real live
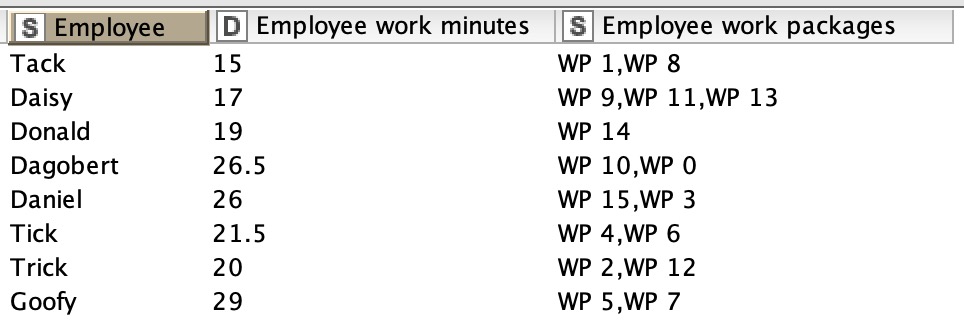
Now let’s assume a more real world scenario. Which it is actually. We build the sum of all minutes and divide it by the amount of employees. That gives us the best possible distribution, the point of approximation.
Now that we have a threshold to get as close to as possible we want to try to distribute each work item only once. We should start with the big ones first, that enables us to better match to the approximation point. So a recursive loop is required or some fancy row loop with reading & writing table as a cache.
Here comes the next challenge. Assuming you have three employees but only one work item of seven minutes, then you’d like to assign more work packages to the other two until they too have seven minutes. So the list of work packages, sorted descending by minutes required, is assigned to each to an employee until the sum of assigned minutes is equal or greater the amount currently in distribution based on the first assignment.
Here again, a new challenge emerged. You’ve got three employees, one work page of, the next of five and three minutes and a few more. The first gets seven minutes assigned, the second would get eighth. So after each assignment round the list of employees has to been resorted descending by the sum of assigned minutes and the difference to the maximum must been resolved first.
In theory this should evenly distribute the minutes until all work packages have been assigned. Though, it’s very complex, but approximation / or optimizations problems aren’t easy in the first place.
Would be keen to know if others have a better idea.
Cheers
Mike