Hi Everyone, I am very new to knime and still learning and I am having trouble figuring out how to subtract a set of columns from another set of columns in a simple fashion. For my workflow, I generate a z score for all the columns in my csv and I would like to divide the z score columns from their corresponding value. The z-score columns have the exact same name as the actual value columns except they have .z-score added to the end. I was just wondering if there was a simple way to do this, as I would not like to use any type of java snippet. Any help or advice would be greatly appreciated.
Hi,
Have you tried to filter the columns using wildcard in “Column Filter” node?
In your case you can use a pattern like this to include the z score columns:
*z-score
Best,
Armin
1 Like
While I could do this, I am sort of confused as to how this helps with my issue. Could you elaborate more on why I want to filter the columns? My main issue is dividing the actual value columns by the z-score columns. I think I could use the math formula multi-column node, however, I would need to manually input the division for every column.
Assuming everything (values and z-scores) are now in one table:
- Unpivot to put all columns in one column
- Row Splitter to separate z-scores from rest
- String Manipulation or String Replacer to remove “.z-score” extension from strings in ColumnNames column
- Joiner to put z-scores and values side-by side
- Math Formula to divide values by z-scores
- Column Filter to remove z-scores
- Pivot to move everything into separate columns again
1 Like
Ok I did this, but I am stuck on the math formula part. I want to divide all the columns by their respective z score columns, but I am not sure how to plug that in the math formula node. The only way I could do this is by plugging in every column by hand in the math formula node which is not really possible with how big my file is. Is there a way to divide columns 1-50 for example by columns 51-100 so that column 1/51, 2/52…
I thought you want to filter the columns and keep the z-score ones. Sorry for my misunderstanding.
Here I have attached an example workflow in which I have a few columns and then I loop over the actual columns (the columns without “z-score” in the name) by using this regex pattern in the configuration window of the column list loop start node:
((?!z-score$).)*
Then in a math formula I divide each column to its corresponding z-score column using a formula produced in the first string manipulation (variable) node and the result column name is produced in the 2nd one (you can replace the actual column by checking the option in node configuration and using the current column name in flow variables tab). Finally I have filtered the other columns using a wildcard pattern produced in 3rd string manipulation (variable) node.
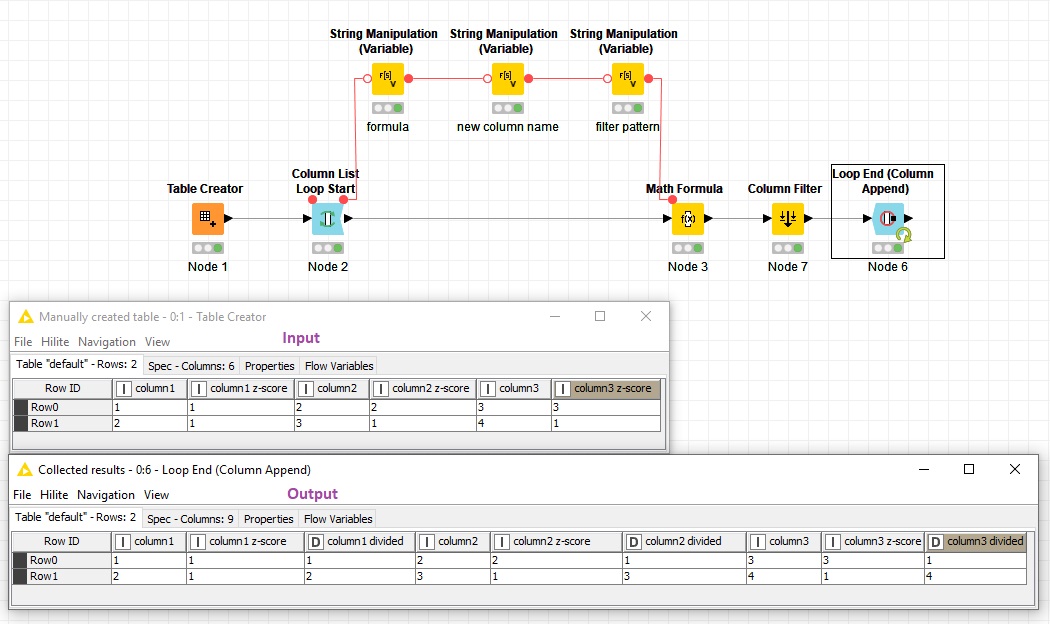
Please check the workflow and feel free to ask your questions:
z-score divide.knwf (28.2 KB)
Best,
Armin
1 Like
The point of unpivoting in my suggestion was to reorganize the table so that you only have one column to deal with in the Math node.
It seems new function needs to be added to Math Formula Multiple Columns- say, COL_Ref(n) which returns value from column with number of Current +n.
1 Like
This is exactly what I needed, thank you!
1 Like