Could you please help with the following problem.
I am using DL4J, Word Embeddings, Word2Vec.
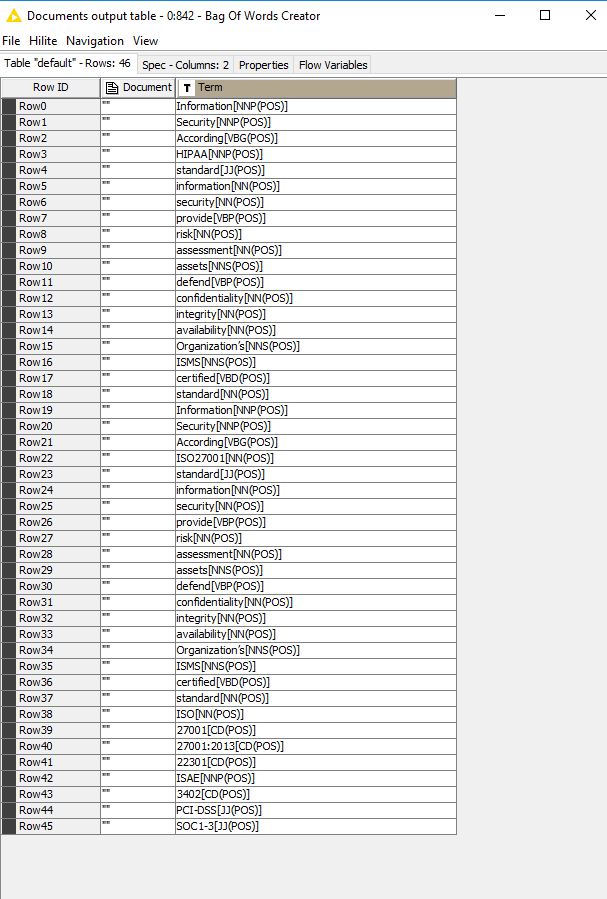
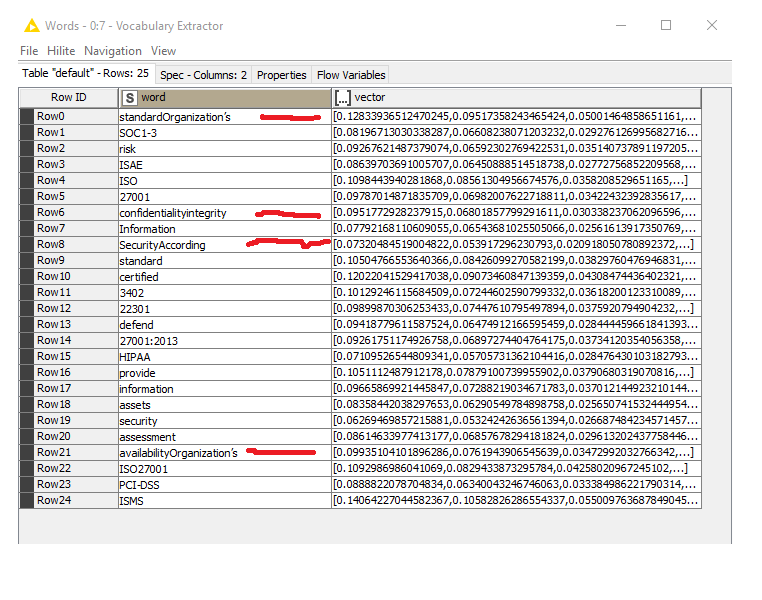
After Word2Vec Learner node Vocabulary Extractor did some mistakes – bad mergers. Please see rows dedicated by red lines.
Bag of Words is good. Vocabulary Extractor is bad.
What should I do to avoid these mistakes as they corrupt all calculations?
Now I am forced to analyze bad combinations and insert them in the table of selected words to save estimation.
the tokenizer of the Word2Vec node just splits on whitespace. For the Bag Of Words (or more precise when the Documents are created), a more sophisticated technique is used (the technique can be selected in the configuration of the Strings To Document node). Hence, in your highlighted examples the terms seem to not be split via whitespace in the original data, thus the Word2Vec node recognizes them as a single term. Sorry for that inconvenience.
As a workaround, you could tokenize the raw data (I assume every document is s String in your case) before feeding it to the Word2Vec node. I.e. insert a whitespace after every term. I’ll try to find a convenient method to this in KNIME.
You could do it using NLTK using a Python Scrip node. On the linked page, the first example shows how to tokenize a string.
thanks for the workflows. After the content Strings are converted to documents, the N Chars Filter seems to connect some words if they are separated by punctuation followed by whitespaces (we are going to look into why that happens). You can see this by looking at the Documents using a Document Viewer node before and after the N Chars Filter node. As these words are then connected, the Word2Vec Learner node does not recognize them as separate terms anymore. In order to fix this, just use a Punctuation Erasure node before the N Chars Filter. This way the N Chars Filter won’t connect the words anymore. Then, the Vocabulary Extractor outputs the same number of words as the Bag Of Words Creator (if duplicates are removed)
I attached a workflow showing my described solution.