Hello my friends, I hope you’re all doing well!
It’s been a while since my last activity on the forum, and I’ve missed you ![]() . I’m sure many of you have experienced this: you build a workflow, come back to it after a while, and think… “What the hell did I do here?”
. I’m sure many of you have experienced this: you build a workflow, come back to it after a while, and think… “What the hell did I do here?” ![]()
Even with node labels, complex workflows with lots of nodes can still feel overwhelming. Sure, we all know we can add workflow annotation — but who really has the patience to do that every time? ![]()
So if you’re like me — a bit lazy when it comes to documentation — this post is for you.
The easiest method I’ve found is to record a voice memo on your phone explaining your workflow. Just hit record and speak naturally in your own language, without worrying about sentence structure or clarity. Then let the Doc Doc handle the rest.
Doc Doc converts your voice into a clean, structured document — and the best part? It works completely offline!
![]() Disclaimer: I’m not a professional in this field, just someone who enjoys solving problems. So if you know a better way, please don’t roast me
Disclaimer: I’m not a professional in this field, just someone who enjoys solving problems. So if you know a better way, please don’t roast me ![]() .
.
What You’ll Need to Install
-
Ollama (for running the LLaMA3 model)
-
LLaMA3:instruct (for creating the clean & structured document)
-
FFmpeg (for converting audio files)
-
Faster-Whisper & Large V2 model (for transcription)
-
Git LFS (for downloading large V2 model locally)
-
PyTorch version that supports CUDA (for using GPU if you want)
![]() Python 3.12 is not officially supported by PyTorch as of now.
Python 3.12 is not officially supported by PyTorch as of now.
The workflow runs offline and requires downloading ~10GB of model files and installing a few packages. (less if you already have PyTorch).
To use the large-v2 model locally, you’ll need to download it using Git LFS or you can manually download it from here. just make sure you put it in a folder anywhere you like and your folder contains all of these files:
-
model.bin— the actual weights (~3.09 GB) -
config.json— model configuration -
tokenizer.json— tokenizer settings -
vocabulary.txt— vocabulary used for decoding
How Doc Doc Works
-
Double-click the component.
-
Select your voice file.
-
Select your Large V2 model folder
-
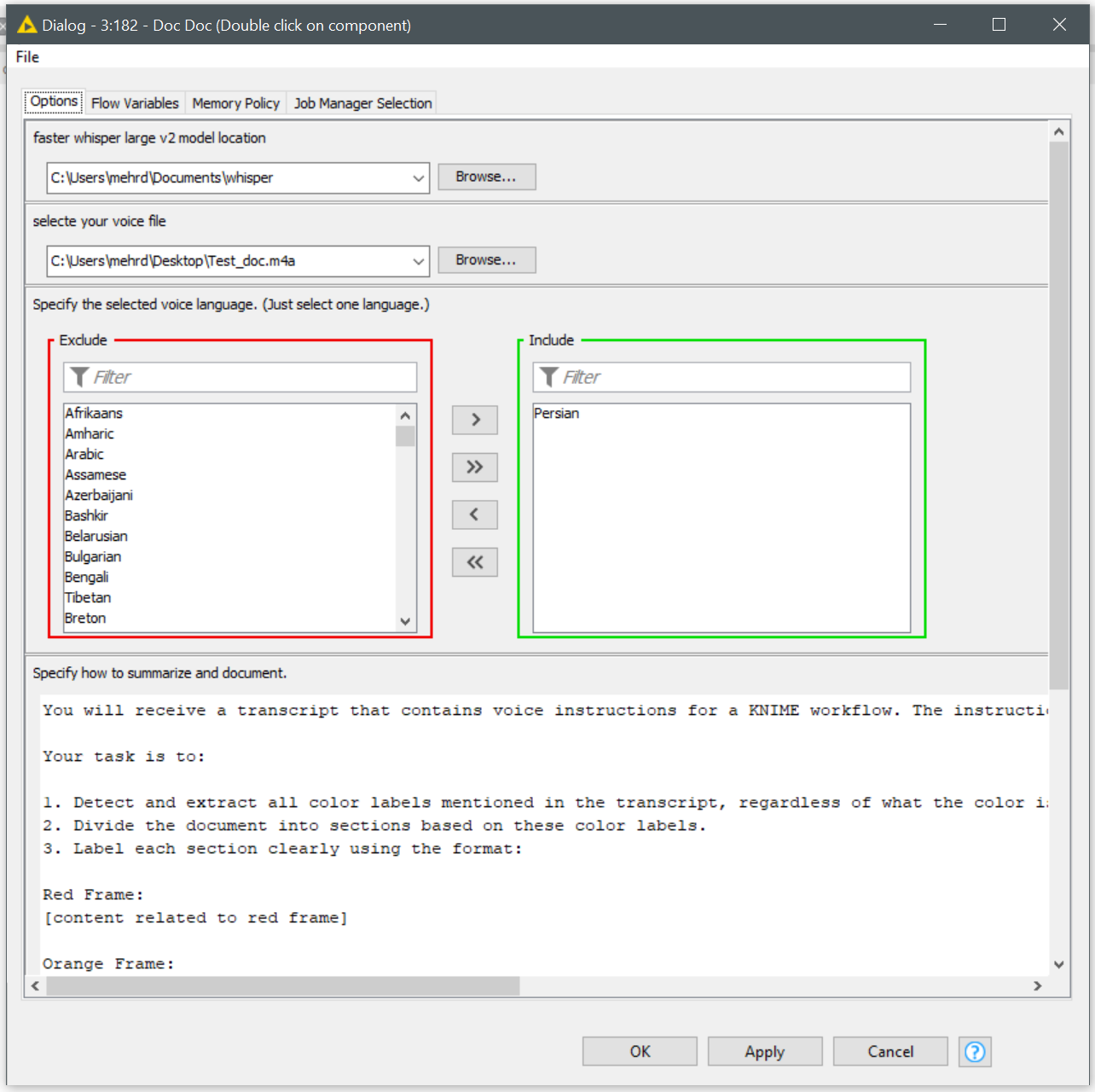
Specify the language used in the recording.
-
Write a prompt describing how you want the document structured. This will vary depending on your speaking style, but after a few tries, you’ll find a prompt that works best — and you can reuse it every time.
-
Choose whether you want the document to be translated into English or not.
Under the Hood
-
The voice file is converted to a 16kHz mono WAV using an External Tool node — one of the scariest nodes I’ve worked with
 .
. -
The WAV file is transcribed using the Faster-Whisper large V2 model.
-
The transcript is then cleaned and segmented into a document using LLaMA3.
Tips for Better Accuracy
Whisper’s accuracy is excellent, especially with the large model. But if you speak slowly, clearly, and in a quiet environment, you’ll get near-perfect results. Remember — you’re speaking to a machine, not a human.
I used PyTorch + GPU for faster transcription. On my RTX 3070, a 5-minute audio file took about 20 seconds to process and the workflow run under a minute.
Instead of large-turbo v3 I used large v2 model because it runs faster with Faster-Whisper + CTranslate2 backend. Even though v2 has 32 decoding layers and v3 only has 4, v2 runs faster than Hugging Face’s with PyTorch backend — and it’s more accurate. However, v3 detects the language better, so we manually specify the language in component config.
Notes on External Tool Node
The input and output files must be defined, so we create dummy files just to allow flow variable-based addressing. The actual file handling is done inside the batch file.
Color-Coded Workflow Documentation
Personally, I divide my workflow into sections using colored annotation frames. In my voice memo, I say things like “the red frame does this” or “the blue frame handles that.”
In the prompt to LLaMA3:instruct , I ask it to segment the document based on these color labels so I can copy each section and paste it into the corresponding annotation.
Of course, you can customize the prompt however you like to match your documentation style.
Hope this helps you out!
Best regards,
Mehrdad