I’m struggling to understand from the output of the Term Vector node in which documents a certain term appears: the column names are cryptic (the numbers don’t refer to anything I can recognize), and the order in the collection column is not explained anywhere (the node’s help says that “the ordering is specified in the data table spec”, but I can’t find it there).
Hi @mpenalver !!
Could you give us a little more detail on what you want to do? maybe a workflow or some images could help us to understand the problem.
I was playing with some documents and i got the Term Vector. It’s possible to see in which documents (ID number in columns) a certain term (rows) appears (1 or 0). Did you use Bag of words and Term freq nodes before to compute the term vector table?
By the way, my text data is not clean, don’t notice this (just and example giving importance to Term Vector node).
Thank you!!

Term Vector.knwf (2.4 MB)
2 Likes
Thanks for the response, @cristiancandia.
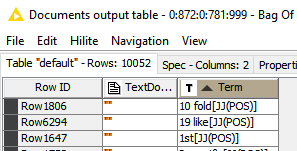
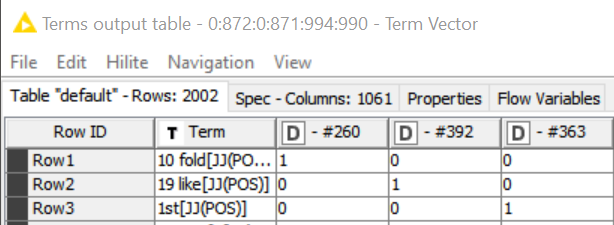
Below is an example output of the Bag Of Words Creator and Term Vector nodes, which are directly connected. Each of the three terms shown only appears in one document. My question is: how can I infer to which documents of the Bag Of Words Creator node’s output the columns of the Term Vector node’s output correspond? In other words, how should I interpret those columns’ names? Notice that my docs purposely have no title, as I don’t want terms in the titles to be considered.
1 Like
Thank you @mpenalver now I can see the problem; you are right, when you assign an empty title to each document to avoid terms in the titles to be consider, the output for Term Vector would be not easy to link with the original docs.
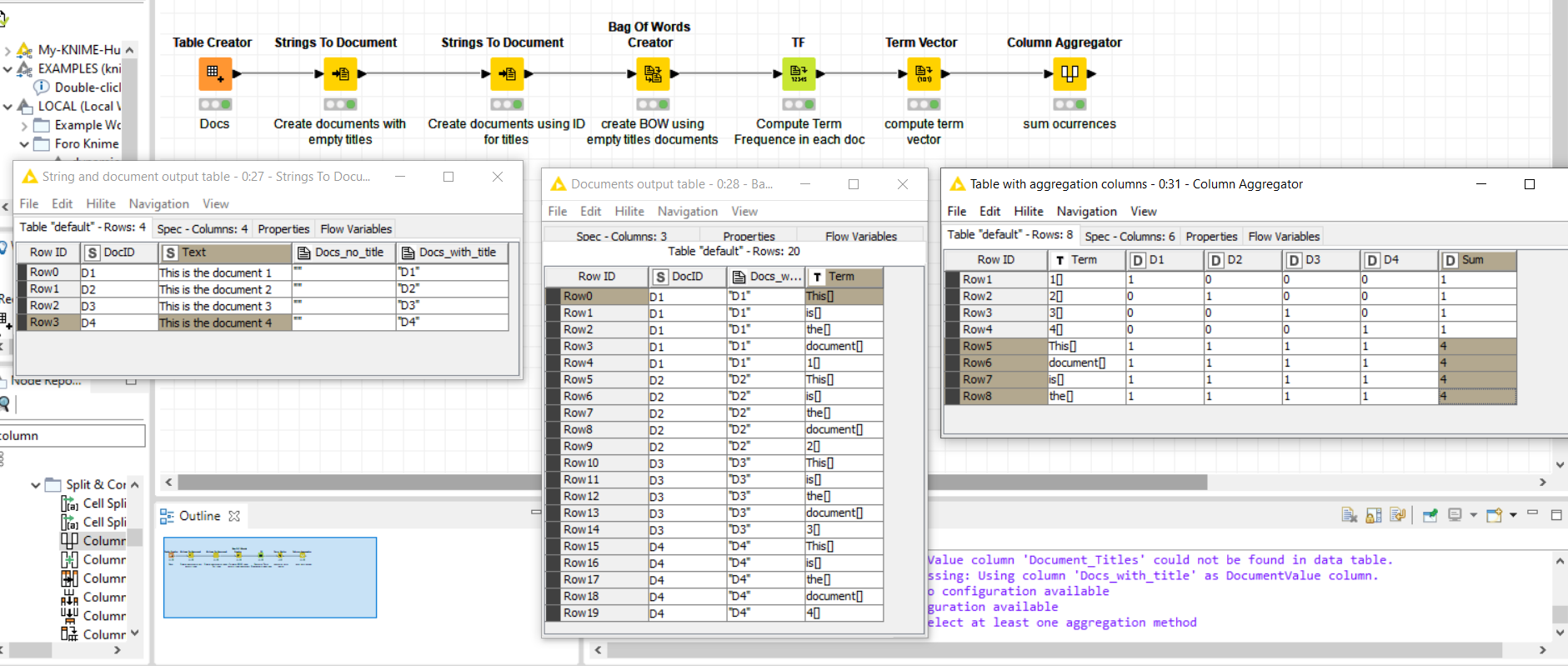
What if you generate two different versions of the documents (2 cols) ?
you definitely need an ID for each document (to identify them faster), then you can create two columns, one with no titles documents and another document col with titles (ID as titles). On this way, you build the BOW using the column with no titles and then keep the documents columns with titles to generate the Term Vector.
i’m not sure if that is the best option but works for me, you could try it.
Term Vector.knwf (35.2 KB)
2 Likes
Thanks for the idea @cristiancandia. I was hoping for the column names coming out of the Term Vector node to be more descriptive of the document they refer to. You are right in that we need a doc ID (even with title, as two docs might have the same title), so the node’s configuration could give the option to choose a column in the input table that denotes the doc ID and use its values to name the output columns. In the absence of a column ID, the names could correspond with the order of the docs in the input table (the first doc would be named #1, instead of some apparently random number).
1 Like
Inspection of the source code reveals how the Term Vector node names the rendered columns. In this function, a Java HashMap data structure is created storing an index for each input document. That index is assigned according to the lexicographical order of the input terms, i.e., index 0 is given to the doc where the first of the sorted terms appears. In this other function, that map is used to name the document columns. The map is iterated over to obtain the doc titles and indices. The column order corresponds to the indices’, so the docs appear in the order in which they were added to the map, i.e., the term lexicographic order. The column names, on the other hand, correspond to the docs’ titles. If several docs have the same title, a suffix of the form " - #" + count, with count being the number of additional occurrences, is added. Because iterations over a HashMap do not guarantee the order of the retrieved items, that count is effectively random.
In conclusion, relating input docs to output doc columns can’t be done reliably through their names. Instead, the input table must be sorted by term; the order of the docs in the resulting table will then correspond to the order of the doc columns, and, I suppose, to the order of the docs in the optional collection cell created. This should be reflected in the node’s documentation.
1 Like
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.