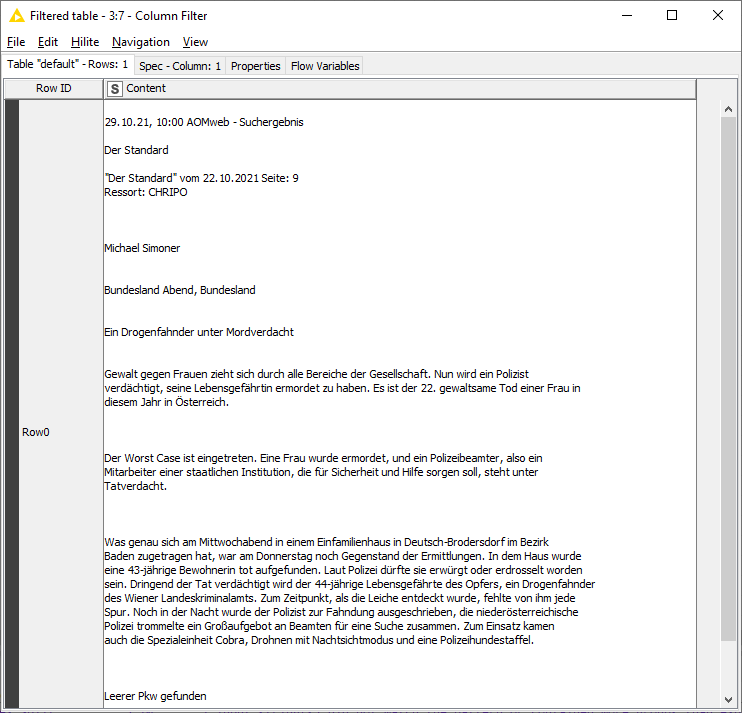
I have an example document which contains roughly 40 sub-documents to extract.
Each of these documents contains a starting regular expression such as “"Der Standard" vom \d\d.\d\d.\d\d\d\d” and an ending expression such as “von \d\d.\d\d.\d\d bis \d\d.\d\d.\d\d”.
I have started with the following workflow: PDF Parser → REGEX Split.
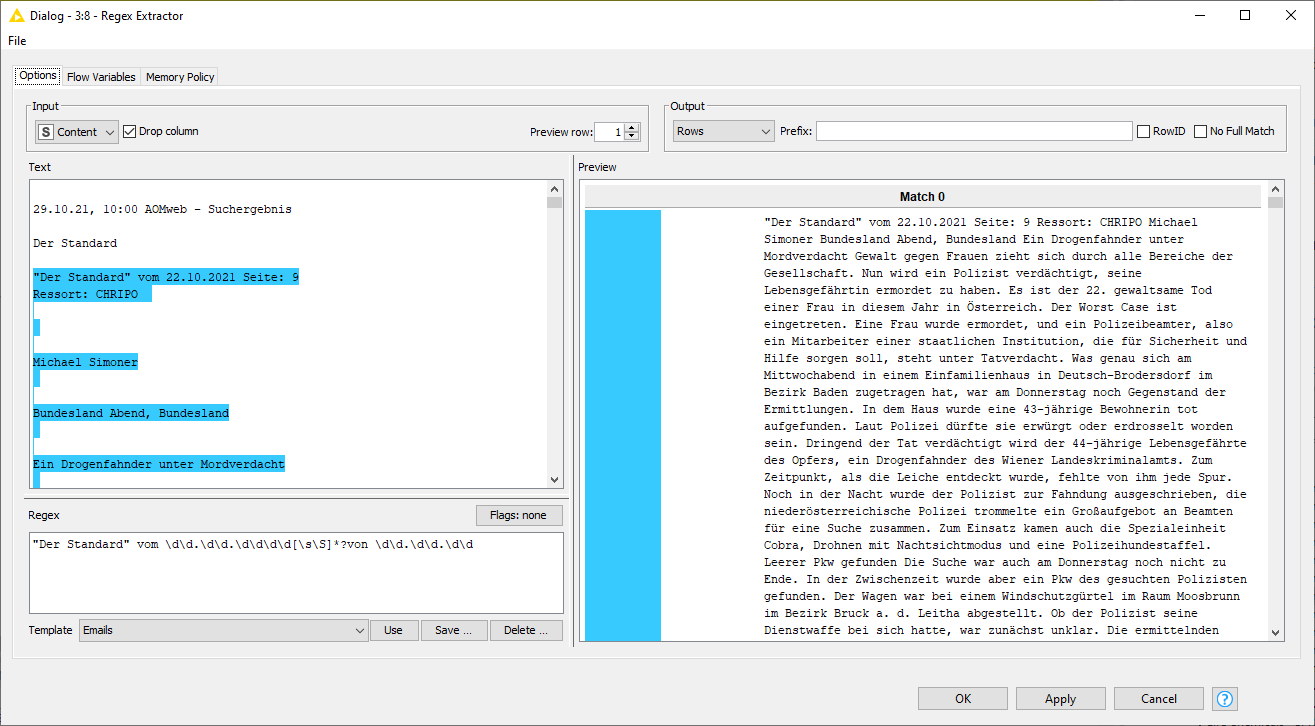
The Pattern I am using is: "Der Standard" vom \d\d.\d\d.\d\d\d\d(.*)von \d\d.\d\d.\d\d
However, the split contains multiple results. The warning is: “input string(s) did not match the pattern or contained more groups than expected”
My view is that the RegEx Split node is best used with with simple strings. How did you construct and check your RegEx? You’re trying to handle a multiline string and the RegEx you wrote cannot parse new line characters.
I think a more user-friendly way to approach this would be to use the Tika Parser node to parse the pdf then filter out all unnecessary columns.
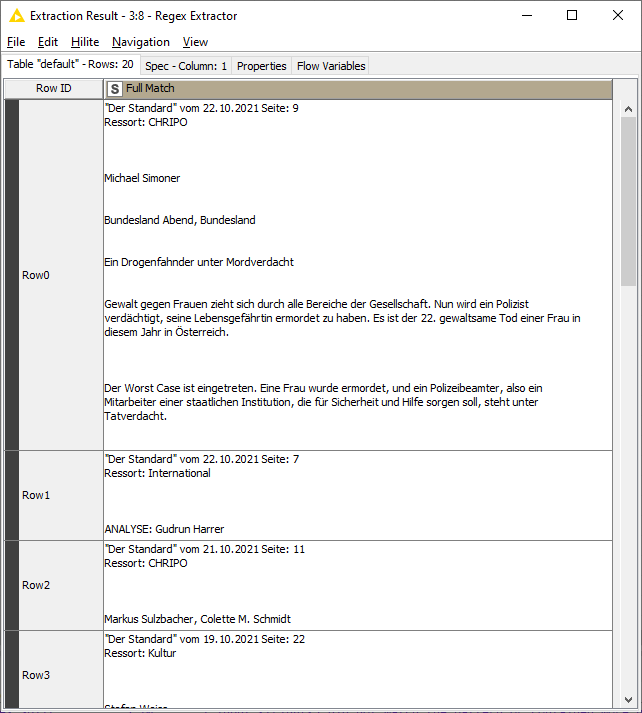
At this point I’d use the the Regex Extractor node to do the splitting using the expression: "Der Standard" vom \d\d.\d\d.\d\d\d\d[\s\S]*?von \d\d.\d\d.\d\d. The [\s\S]*? will parse newline characters