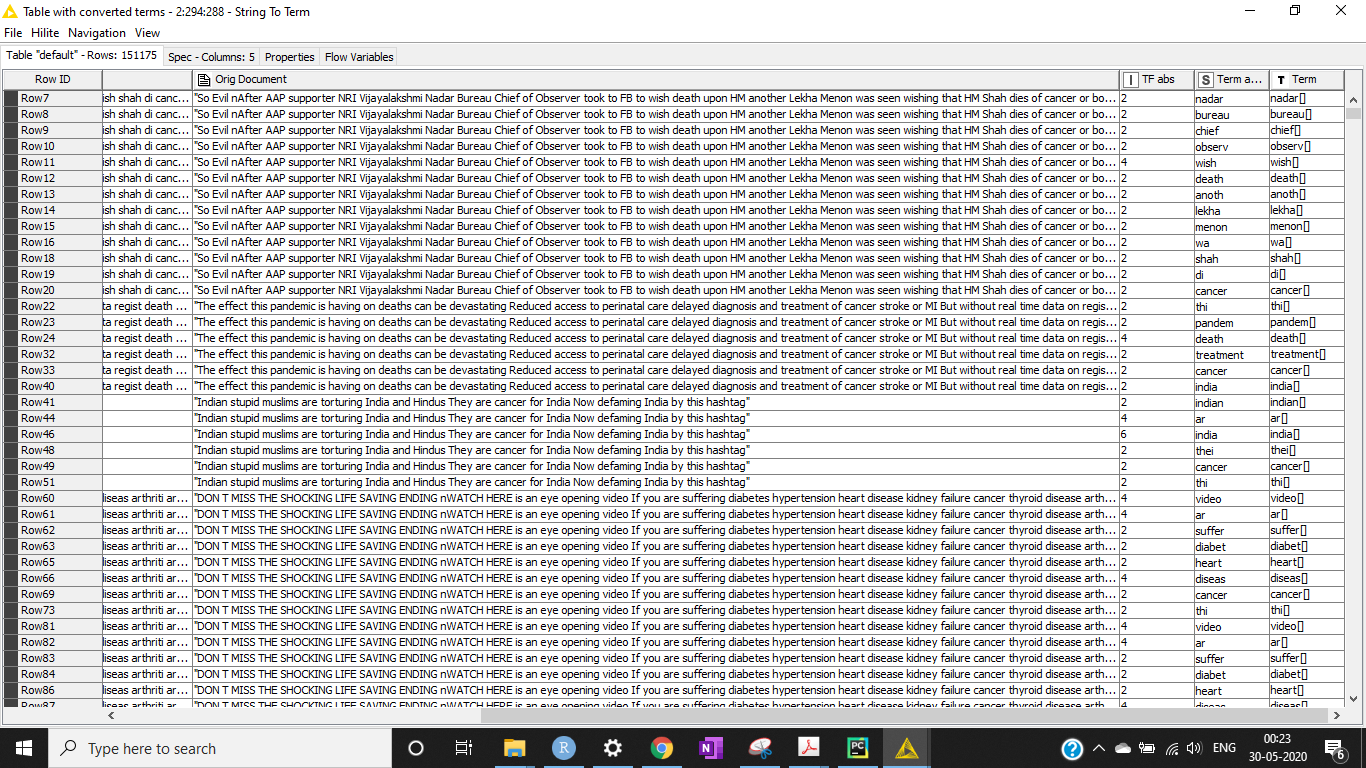
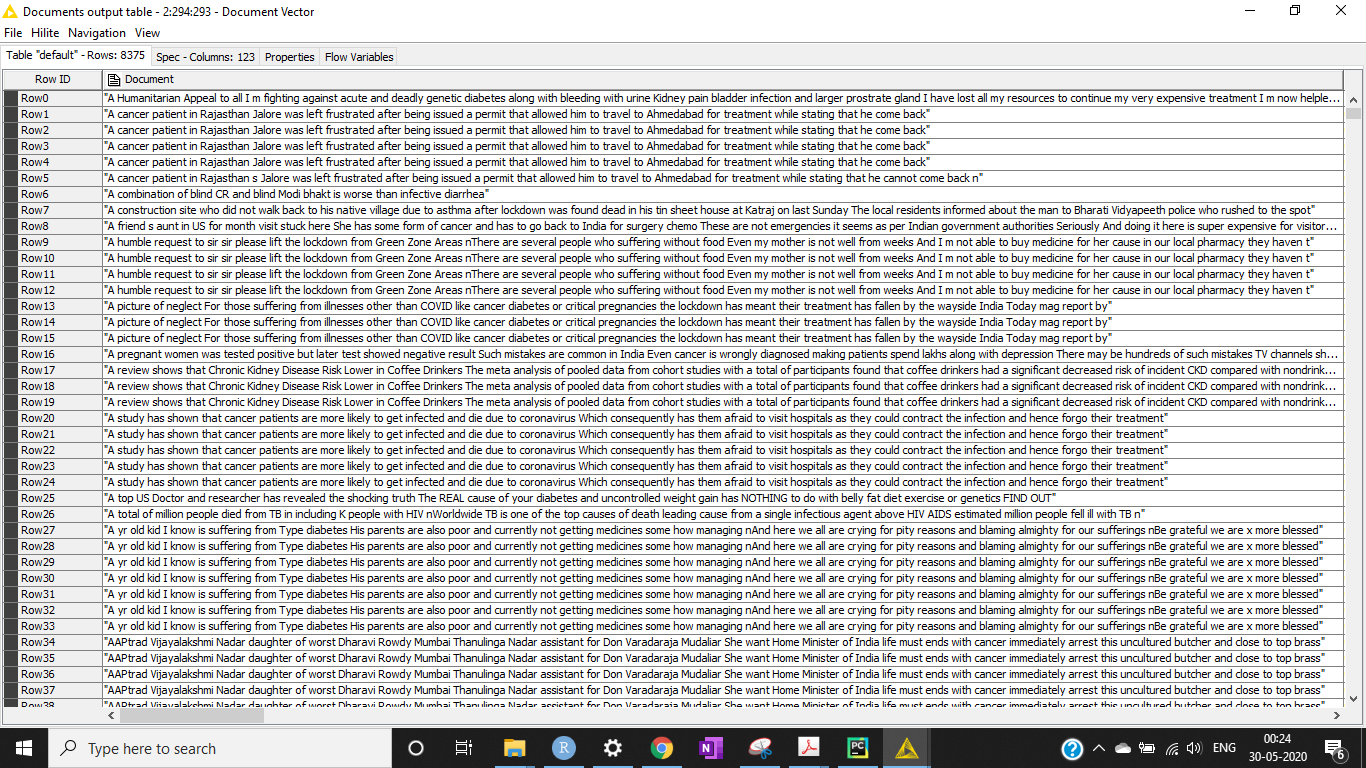
I have only 2 columns in my dataset - Data and Category. My first 1000 rows are the training model but because of this sorting, I’m unable to train the TOP 1000 rows using partitioning and decision tree.
It is really urgent and I’m unable to figure out an alternative way to solve this problem.
What about partitioning your dataset first, then using the Document Vector node in your training branch, and the Document Vector (Apply) node in your test branch?
If I am misunderstanding something - all too likely! - maybe post your workflow and someone can take a look.