Hi,
I am looking for a workflow with a loop(!) that allows me to download all files from a webpage into a local directory. I am looking for a solution with a loop and error handling (in case that a file can not be downloaded the loop should continue). I prefer a solution that does no contain a URL list that I have to create - I am expecting the webpages that I am using will add files in the future.
For example, several zip and text files are alternating on this webpage: MSHA - Open Government Initiative Portal
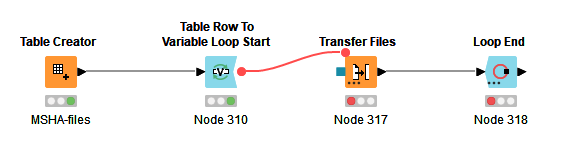
I am only able to download the files individually. I have tried several versions of a simple loop where I create a table with the URLs. It is not working - I can not configure the Transfer Files node. See example.
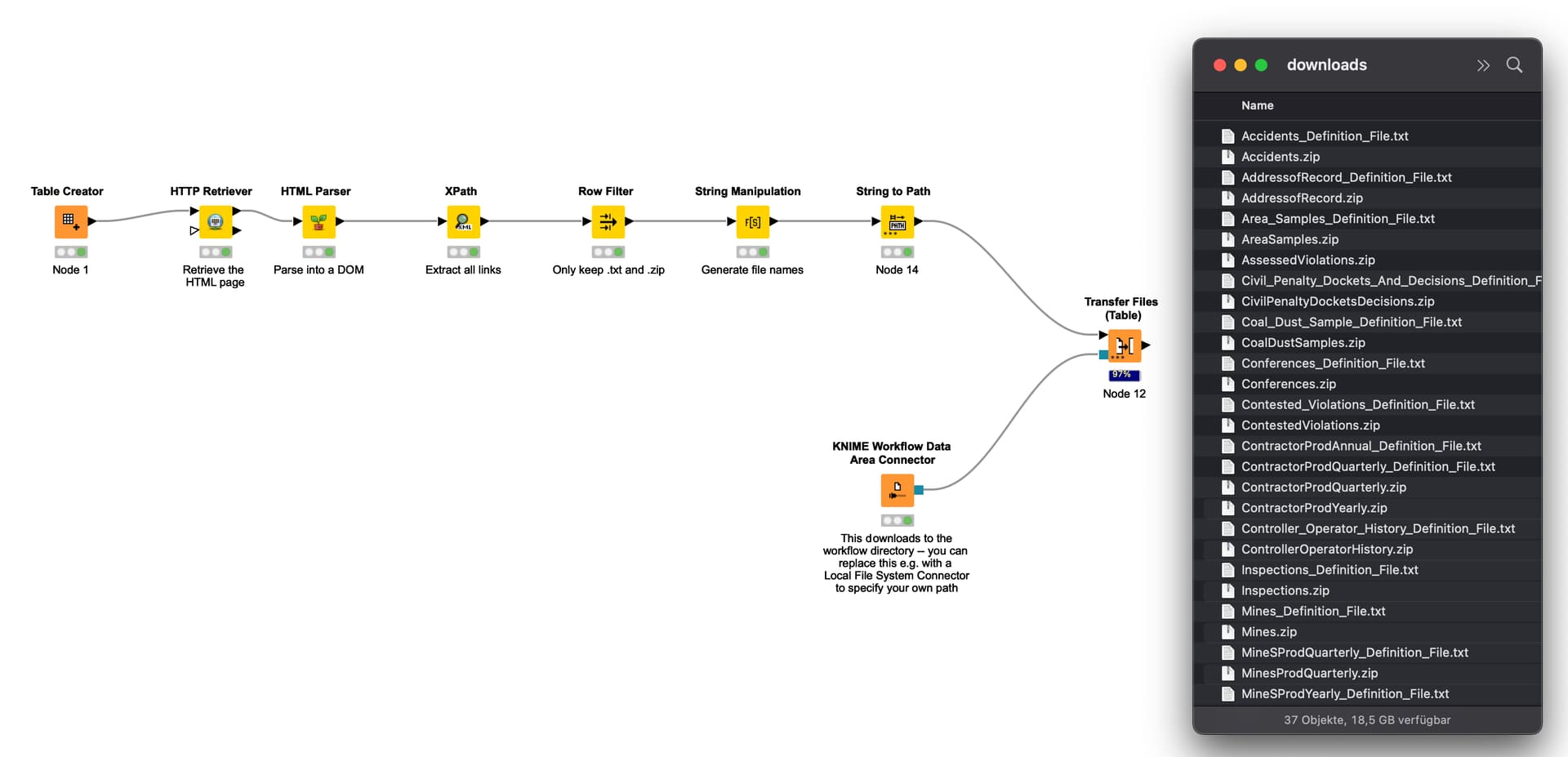
You can retrieve the webpage with the HTTP Retriever, parse it using the HTML Parser, then extract all links using an XPath expression like //a/@href. From there, filter the links you want to download and then use eg. a Transfer Files node to download the files to your computer:
My workflow doesn’t take into account files already downloaded, so you should think about a solution.
But checking the downloaded files in your folder and removing them from the list “to download” should do it, I guess.
Br,
Perfect. It does do the job very well. I am not a big fan of extensions (I keep loose them when I upgrade), but it is a very good solution. I should be able to use it for all my problems. 2cents: It is a very good example for the NodePit space, but I would not find the example with the title and filename. Why not calling it: Download all files from a webpage?
Thank you!
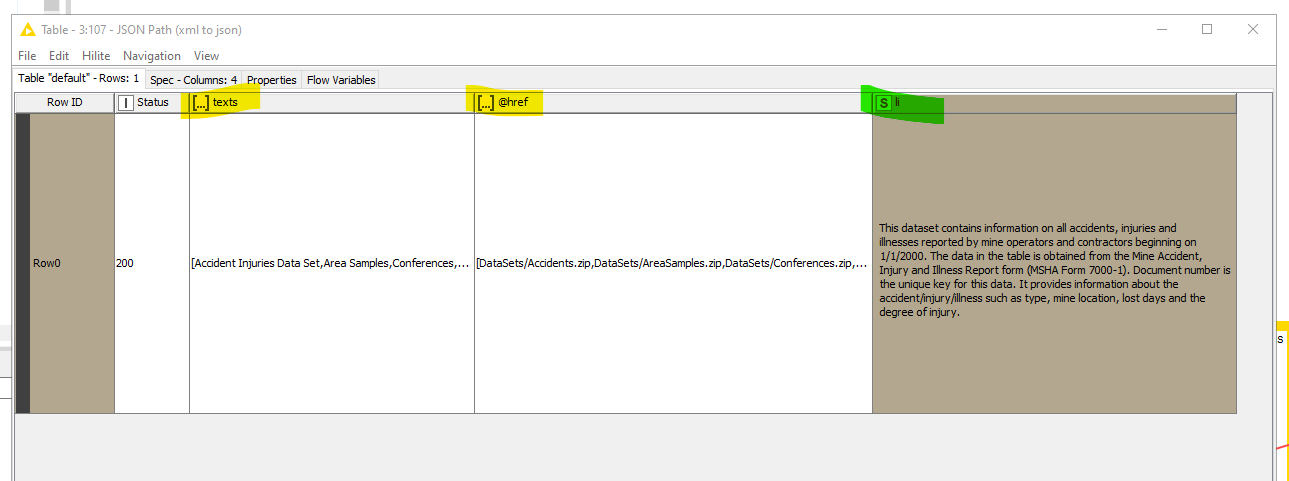
I like this solution, too, because it does use loops which I will need. The data table of the Ungroup seems to miss one text descriptor - maybe an issue of the webpage? I will uses with non-legacy nodes. Thank you!
But actually, you should adapt the solution of @qqilihq and add loops. Because, you never know when a legacy node can be “removed” from the core. So a solution should be made to be stable in the future (or you’ll have to change your WF often, which doesn’t make sens right ?).
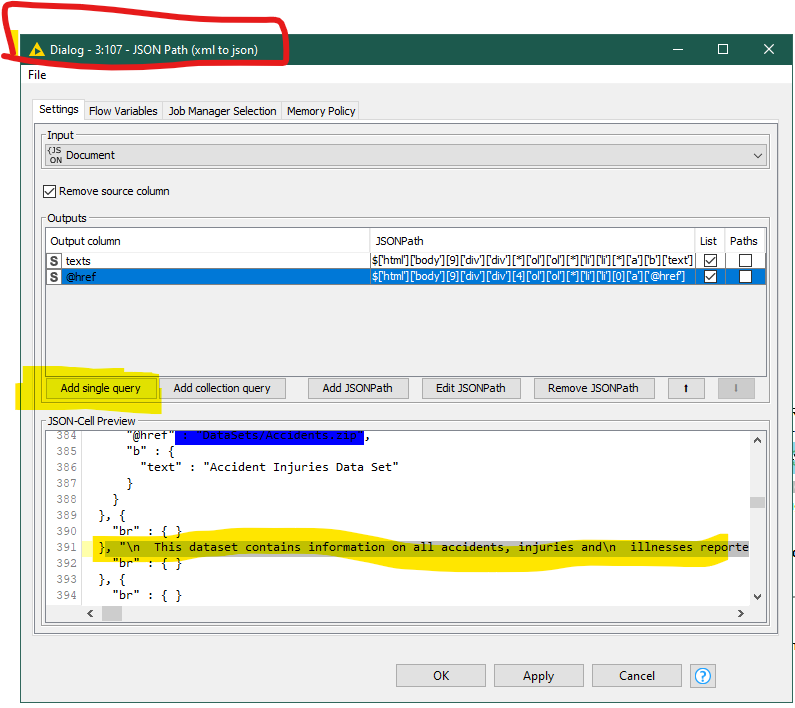
I’m not sure whether I understand what you mean regarding the “Ungroup Node”? The “Ungroup Node” is just used to beak apart some Json. If problem there is, it should come from the “Json Node” actually. If you miss something, you should look into the “Json Node” and add the wanted field like this :
In the pic above, you can see that the description is a string, so there is nothing to do more. But the other columns are lists (because of the brackets), so you have to ungroup them.