I have no idea where to start, my KNIME work has all been local with DB or XLS file manipulation or joining.
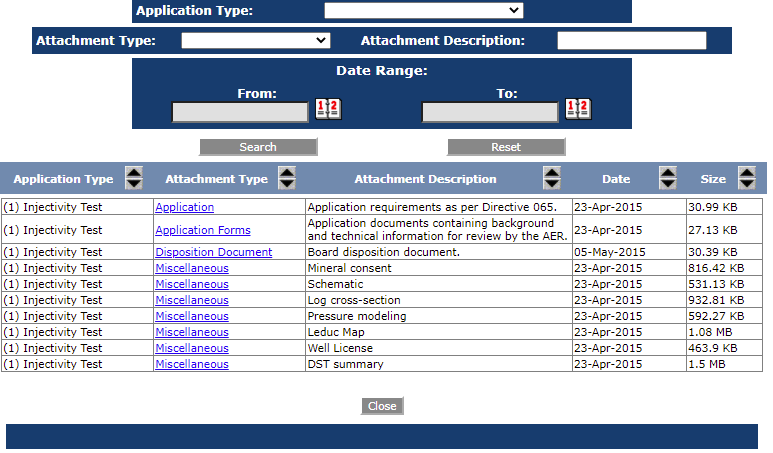
Trying to get a workflow built that can get the following public data:
Save locally the file names based on the Attachment Description in the website table. Most are PDF or doc or xls.
First I want to prove I can download a single application and all the attachments before I build in the table of applications.
I am not adverse to putting in a Python script if necessary. But some nodes ARE limited by my company.
I separated the host data from the request data (Table Creator and String Maipulation), because we need the host data later again.
The first GET Request fetches the application data. The Regex extracts all document numbers.
To fetch the documents we need a document query, build with host data and our extracted data, and the application query as Referer (Request Headers Tab).
At the end we have the filename, which we query with the entry Content-Disposition (Response Headers Tab), and the binary data of the document. The rest should be simple.
Thank you! You definitely got me started on it. Had a bit of issue in the beginning. Your workflow is built on KNIME 4.4 and I was using KNIME 4.3
The difference was the RegEx Extractor node couldn’t handle the List that the GET Request was creating. Basically, it’s an Array. Once I figure that out. I was able to use UnGroup node to move it back to a string rather than an array and it began to work.
It also appears I need to open and search for one application on the website before running. If this doesn’t happen the GET Request is blocked or not received and retries endlessly.