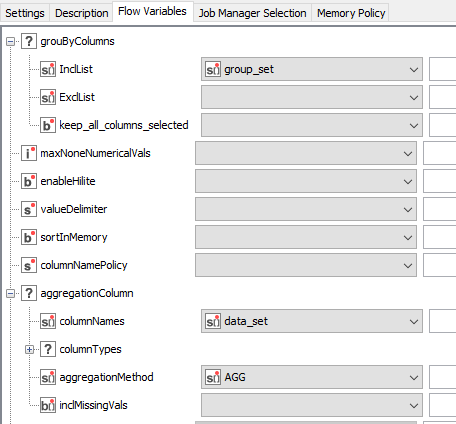
I am trying to execute a groupBy node via flow variables with ‘set’ of columns to apply in the flow variables configuration as shown below. You can see I have created sets for the groupBy columns, the aggregated columns and also aggregation methods (AGG). I have tried without the AGG list without success. The node issues a configuration warning ‘Errors loading flow variables into node : String for key “numericColumnMethod” not found.’ I see a few related posts but none seem to solve this - can anyone help please ?
Hi @SteveThornton , could you post example screen shots of what the configuration would be if you were configuring it manually, so we can get an idea of what configuration you are trying to achieve in this instance with the flow variables. thanks.
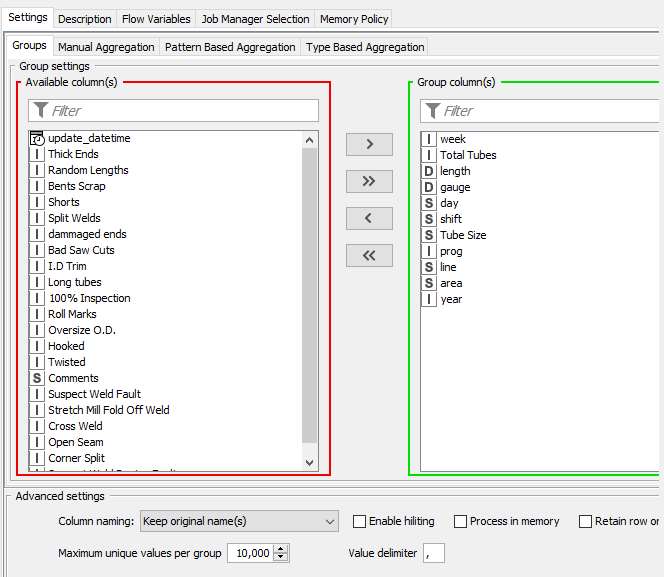
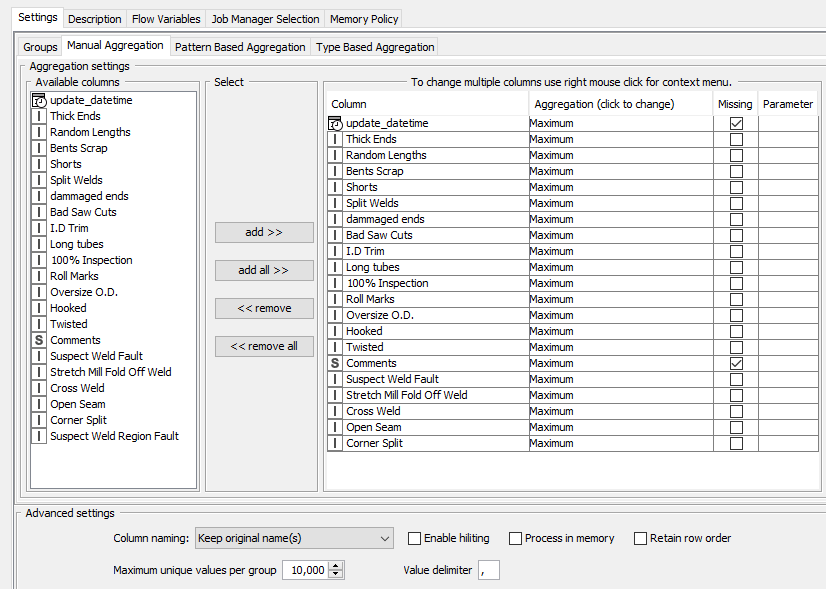
Hi, thanks for your response, a couple of screen grabs below… Basically what I’m trying to do is loop through several workbooks where departments have logged numbers of defects against a group of categories. Each area has a different collection of grouping and aggregation fields. Looking at the manual config maybe I need to include the ‘missing’ tags…
As an update - I tried grouping the aggregation methods in a list instead of a set, whihc gave me a full list with the repeats, and then get different error (see below), I thought to assign column types in the same way but there does not seem to be an option to enter flow variables for that as a set/list. Maybe I’ll try to specify all separately but not sure how to then load those into the individual column types.
Errors loading flow variables into node : Coding issue: Index 1 out of bounds for length 1
Haven’t got time to play with this at the moment, but just a thought…
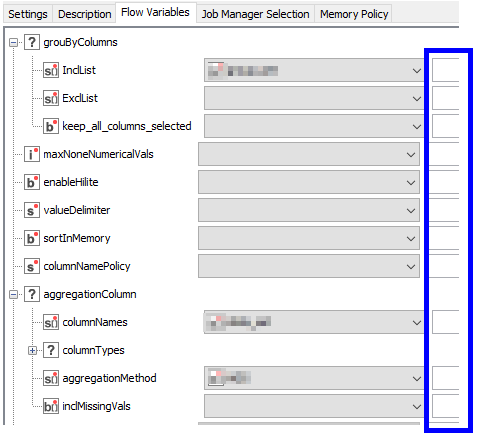
With your manually configured groupby node, go to the flow variables tab and enter some new variable names in the boxes to the right of the drop downs (a new unique name in each box of interest) .
i.e. the boxes I marked in blue here:
Don’t specify any variables in the dropdowns themselves, and then execute the Group By node.
Take a look at the flow variables that get created for each of those entries and see what values KNIME has put in there. That may give some clues about what you are aiming for.
Thanks for that - those created variables look pretty much like what I have generated as lists. Sticking point does seem to relate to the column types where it seems that the flow variables need to be submitted for the specific column…
What happens if you feed those flow variables created by the manually configured group by into another group by node that hasn’t been manually configured?
Initially I also thought that if I feed in arrays with the column names for aggregationColumns and the corresponding values for aggregationMethod it should work - however it didn’t.
It appears that you can preconfigure a number of columns in the manual aggregation tab and I think these need to match the data type you want to feed in.
So let’s say you have an array of column names (col1, col2), an array of their type (Integer, String) and an array of the aggregation function (Sum, First)
If you set these as flow variables you won’t be able to leave the config view unless you go to Manual aggregation and put in one integer column and one string column with a any aggregation function…
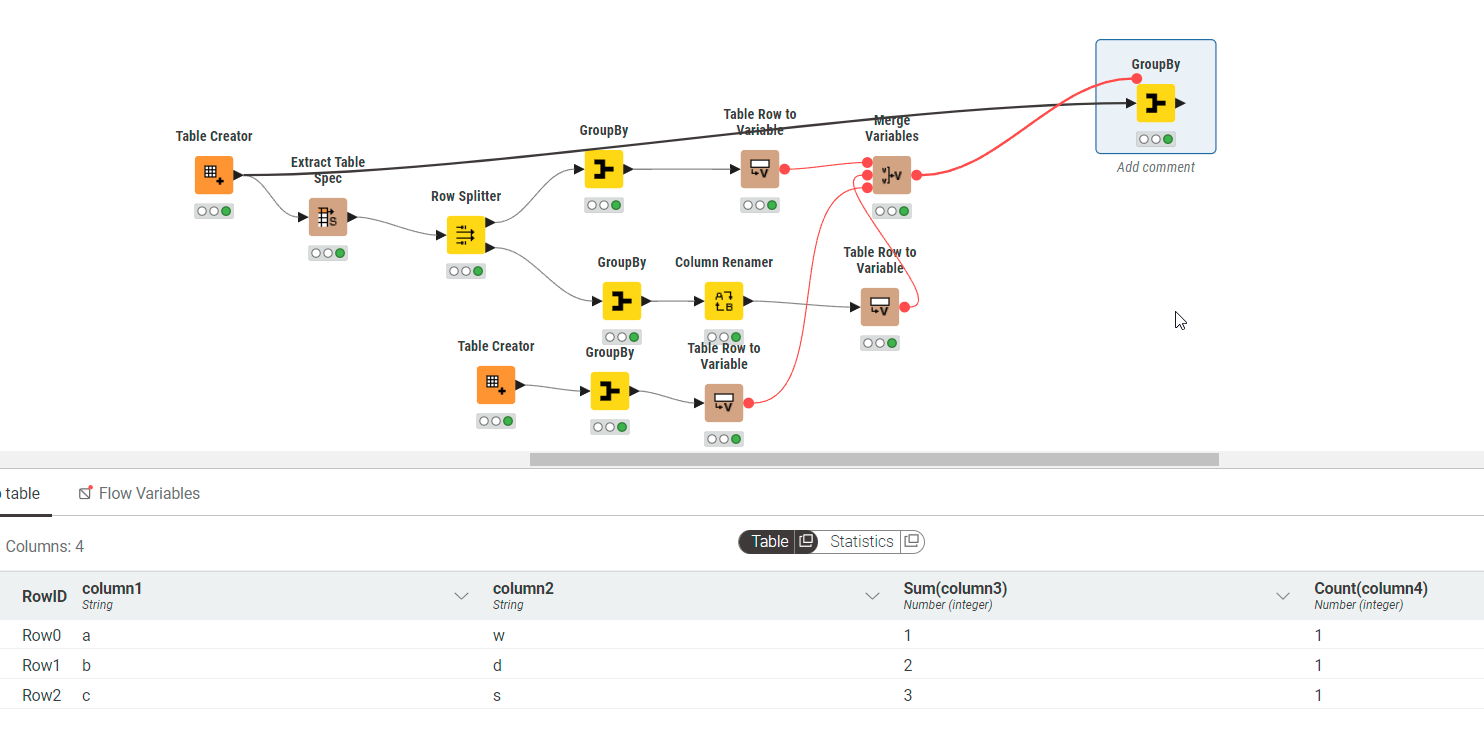
Let me maybe illustrate that. Here is a prototype: KNIME_project.knwf (96.0 KB)
When you then go and configure again and check the flow vars tab, something weird happens. The column types option does not accept arrays anymore, but needs individual variables for each column - now you also can’t save anymore:
Thanks for your efforts I have been trying to create individual column types as variables with values as indicated by the experimentation above (e.g. below) the types being computed via a rule engine from a table of ‘types’ I have already, substitute into RowID, then transpose and convert to variables; then preconfigure the GroupBy. preloaded with ~40 aggregation candidates, with these types as flow variables for the column types options. Close but no cigar (node seems to forget the preconfiguration) - getting complicated I think, may have to look at some looping method to achieve the result I seek…
Following your method @MartinDDDD I do see the array option for column types when no aggregation fields are specified. But as you say, on selecting a field to apply an aggregation (which as you say is necessary to exit the config), the individual column mode for the flow variables is presented. I did find that the array format is retained if a type or pattern selection is applied but I still receive an error on the node which prevents execution, the error is ‘Errors loading flow variables into node : String for key “numericColumnMethod” not found’. I can’t easily test the approach you first tried (which seemed to work) as there are ~30 fields to be aggregated in my case. I flagged this up to KNIME Tech during a meeting we had today so maybe they can advise
I got the feeling it might be worthwhile to move this topic to Feedback & Ideas as an improvement idea or bug report :-). Depending on how you look at it!
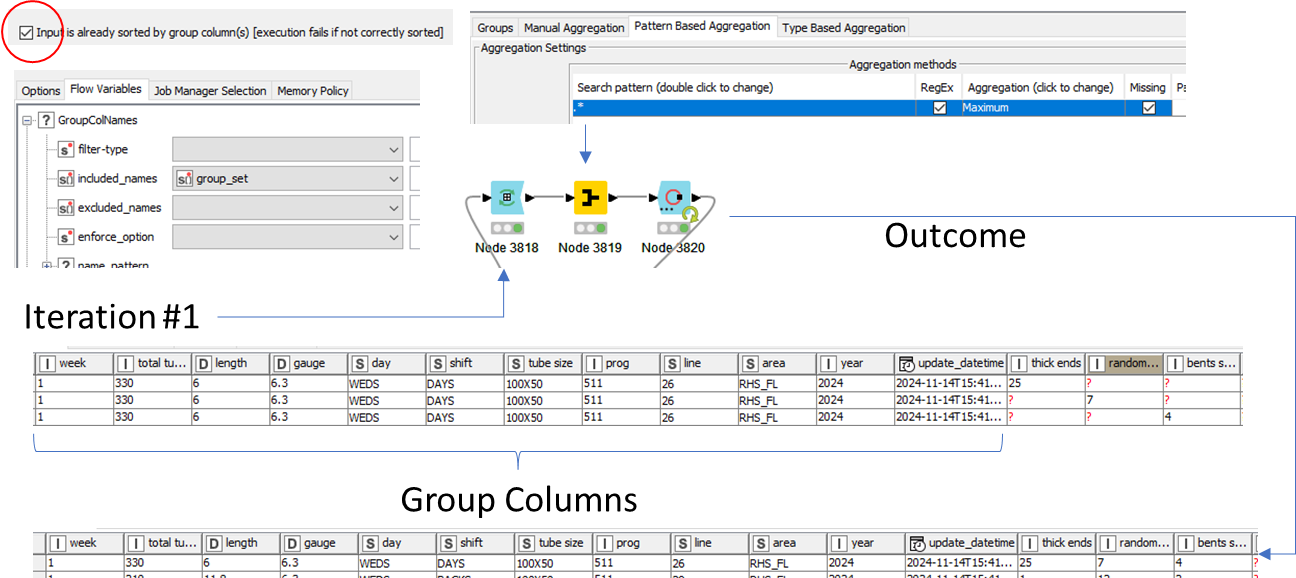
Just to round off the current discussion, I did manage to find a work around using a ‘Group Loop’, but is slow and this is an interactive application so not ideal. I’ve attached schematic of this solution in case anyone wants to make me a nippy JAVA snippet to do the job : )
Spoke too soon… Something still amiss, the ‘group_set’, in the first data set for example, has only 9 members in the group but the group loop node is reporting a key with 11 members. This works OK still for this particular data set, but in a seond data set I have 11 members and group loop reports key with 20 members. Something definitely amiss here I think,
Duplicate key detected: “Input table was not sorted, found duplicate (group identifier:%11%%207%%20%%6%%12.0%%2024-03-13%% DGRSTK%%ER%%120 X 80 X 10%%24128343%%7T29110%%INSP_100%%2024%%?%%?%%?%%?%%?%%?%%?%)”
%% appears to delimit - so 20 members, extending into the data to be aggregated…
group_set entered is
i.e. 11 members - go figure …Looks like I’ll have to write some code.