Due to some error in knime workload, my EC2 instance stops responding where knime server is installed. every morning at a specific time.
I am using knime server small on AWS EC2 8 cores 32gb memory ( 26gb assigned in ini.config)
I am attaching a log for the last two days.
Please look into this and help us understand the issue.
please let me know if anything requires for analysis.
11 June 8 Am to 10 Am server was down.
10 June 9 am to 11 Am server was down.
Thanks for submitting your question and attaching the logs as well.
Can you please help us clarify a few more things.
When you say that you EC2 instance is not responding, what does that mean? Are workflows not running, and giving an error? Are you not able to get to the web portal to even see the jobs that are running or scheduled? What errors are you seeing in the workload, and can you send a screen shot of it?
What we saw in the logs was that there may have been a timeout for the web portal and Knime was attempting to run/execute/discard some jobs using a token that had expired. We may be able to adjust the timeout so that this doesn’t happen as frequently or we can test to see if that is the issue as well, once we get a bit more information on the issue.
as no error appear cant understand the cause. no screenshot available but.
after affect -
we cant reach to web portal.
during that time no scheduled workflow runs.
cant even login to AWS EC2 instance.( nothing is reachable ).
everything stuck / hang on screen.
Last option I left with Reboot the AWS EC2 instance.
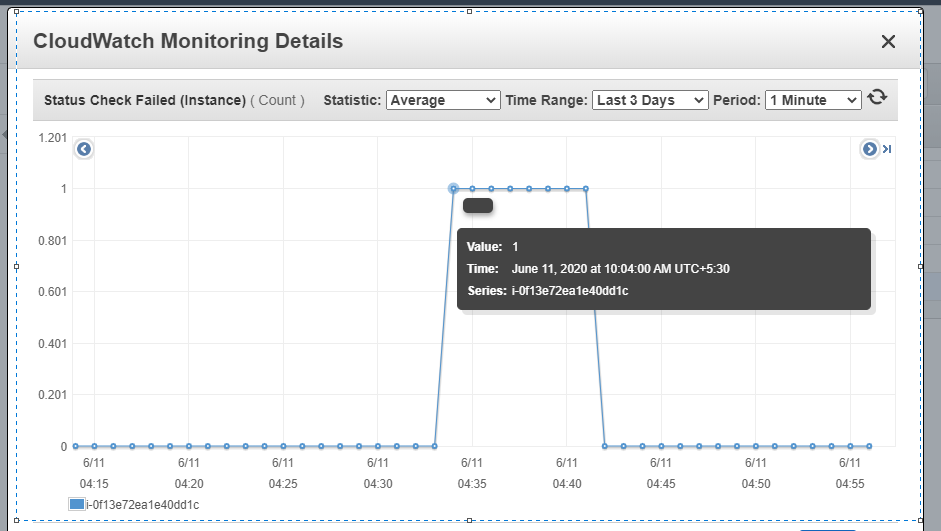
I have sent alert on AWS cloud watch if such thing happens reboot it…
I have screen shot for AWS cloud watch…
I think when memory utilization high then it happens.
But i have given 26gb out of 32gb.
May be executor not releasing memory for next running workflow.
A few more questions to help us narrow down the issue:
Is it possible to give the machine more than 32G, say 64 and try increasing memory usage for Knime to 60 GB?
Do you know when the last scheduled job runs, or manually run job runs before the issue occurs is? And what workflow is specifically run at that time? I am curious if it is a specific job that is taking up a large amount of resources? If you can attach that workflow as well that may help us see if if this worfklow is very resource intensive.
Are any other applications running on the Knime server? Any DB’s, AV software, etc…?
If the entire server is locking up and the issue is not just not being able to reach the Web GUI, then it appears to be an issue with memory usage.
I would like to first narrow it down to whether or not it is memory usage, and then if we determine that memory usage is the issue, then we can figure out what is causing the high memory spike. Please let me know if you are able to increase the memory usage and we can go from there.
Can you please also attach your configuration file, which can be found on the Knime server web interface or <server-repository>/config/knime-server.config. We want to take a look at what you currently have set so that we can see if there’s anything that might be affecting your environment.
Please set the com.knime.server.executor.max_lifetime= from 20 to -1
and then let’s also give the executor only 20 Gb to run, so that Tomcat and the OS have enough resources to run smoothly.
Let’s try these settings and go from there. If you still have issues with memory after changing these, we can adjust the executor settings to be a little less memory intensive.
Yes , I guess this was the solution,
but simultaneously I moved heavy workflow to separate time. and
com.knime.server.executor.max_lifetime= 10m
refused xms =24g/32g