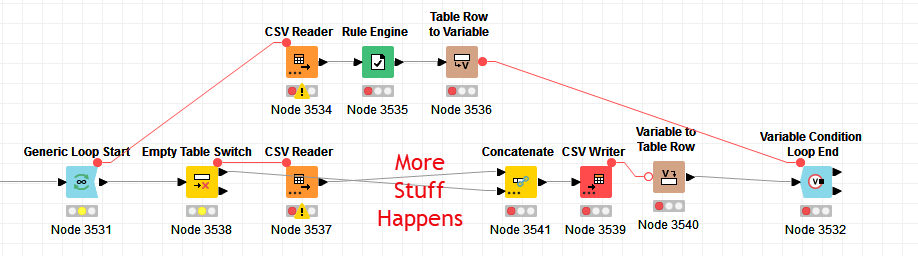
Hi @alabamian2 , I’ve occasionally experienced similar situations The generalised problem for me, if I recall, is if we have a Switch where we wish data to progress (so not just flow variables) on one port, but we only want the flow variables to progress on the other port. The fact that the activation of the flow variable port cannot be controlled via the Switch condition means we lack control over a downstream process.
As an example I have a feeding data source. If that data source has rows, I wish to continue processing that data. If that data source has no rows, I wish to substitute in a different data source and process that instead.
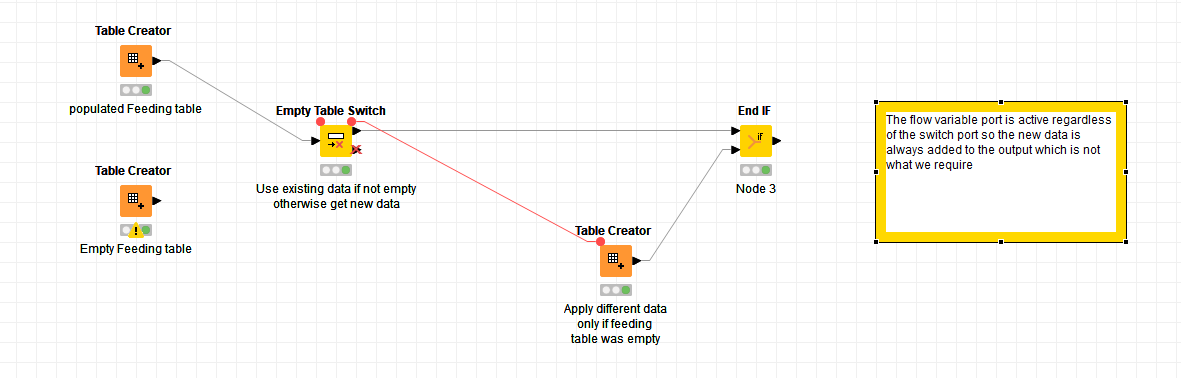
Conceptually, I want this (except that I only want the flow variable port on the Empty Table Switch to be active if the input table is empty. )
My input feeding table looks like this:
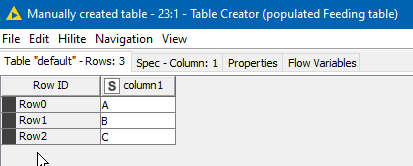
My “substitute” data source looks like this:
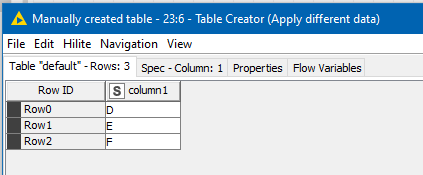
and as things stand, my output data source is NOT what I would want, as it will always be the concatenation of both tables:
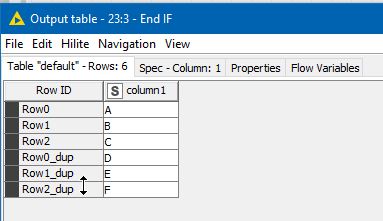
What I actually want is for it to be this:
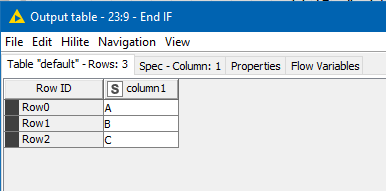
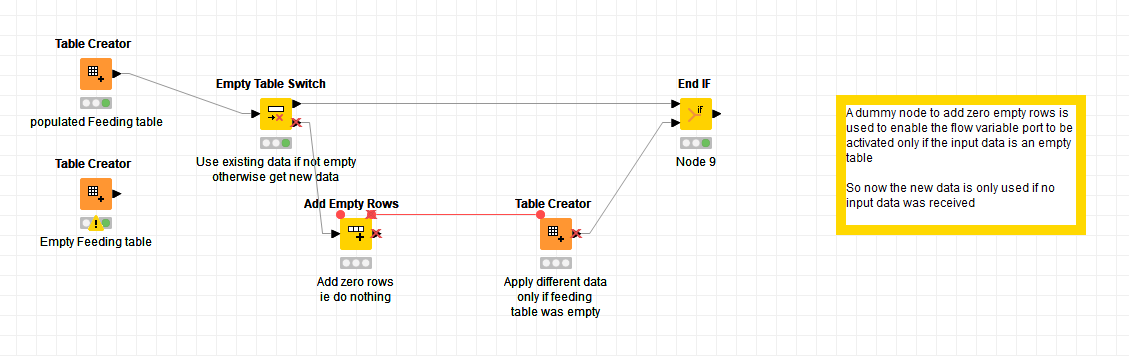
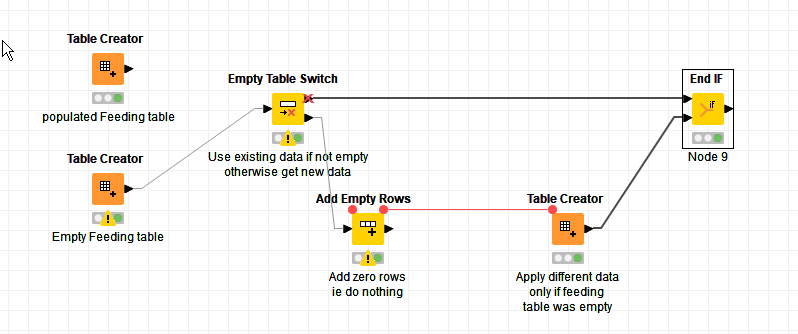
So what I have done in the past, is use an Add Empty Rows node, and tell it to add zero rows, or require that there be at least zero rows! (which both equate to “do nothing”)/ In this specific example is probably doesn’t matter much what this node does as I won’t be using its output. I just want it to be minimum overhead. It could be used in other cases though where you want it to be present but not affect the data flow.

This is then activated only if the input table is empty, and as a consequence the substitute data is only used under that scenario.
Now my output data source will be
or

if I hook up my demo with an empty feeding table
So yes, I totally agree that the need for a dummy node is real. I haven’t needed it often, but I’ve certainly found need for it in very specific use-cases (of which this is obviously a contrived and simplified example)
Use case for do-nothing-node.knwf (24.5 KB)




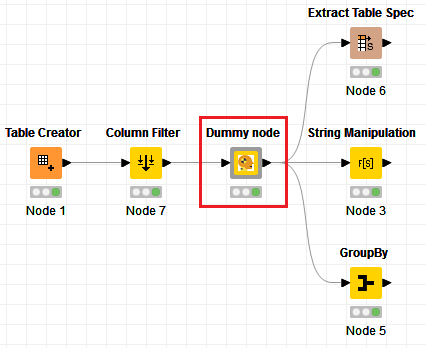

 ) - no need to further fill the node repository, I would say. Plus you can adjust the port types to your needs. What do you think?
) - no need to further fill the node repository, I would say. Plus you can adjust the port types to your needs. What do you think?