I’m working on a workflow that helps identifying duplicate invoices/payments. Due to the great support of this community, I was able to finish lots of the harder workflows.
There is only one problem left: Identifying similarities in invoice numbers and marking such invoices as duplicates.
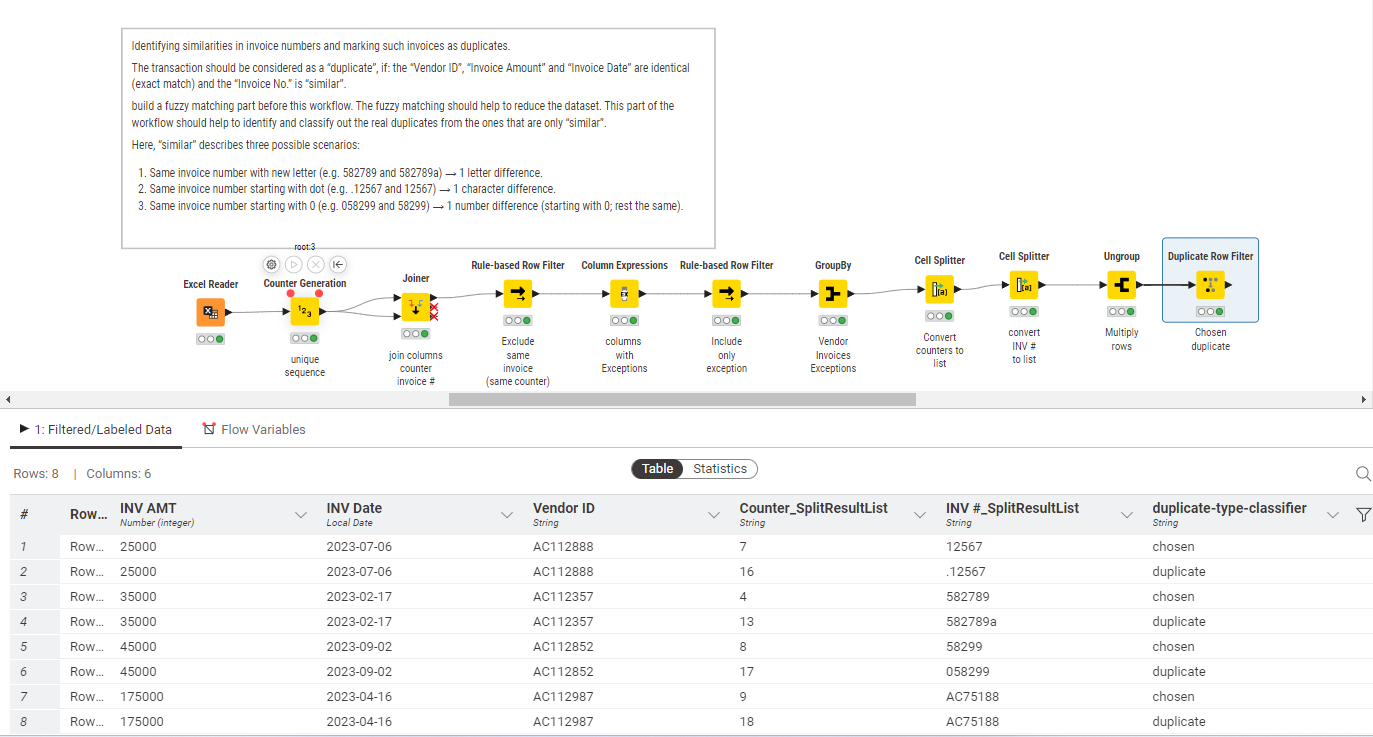
Basically, there has to be a check for every invoice (each row in one column) in an excel file. The transaction should be considered as a “duplicate”, if: the “Vendor ID”, “Invoice Amount” and “Invoice Date” are identical (exact match) and the “Invoice No.” is “similar”. In fact, I also have to build a fuzzy matching part before this workflow. The fuzzy matching should help to reduce the dataset. This part of the workflow should help to identify and classify out the real duplicates from the ones that are only “similar”.
Here, “similar” describes three possible scenarios:
Same invoice number with new letter (e.g. 582789 and 582789a) → 1 letter difference.
Same invoice number starting with dot (e.g. .12567 and 12567) → 1 character difference.
Same invoice number starting with 0 (e.g. 058299 and 58299) → 1 number difference (starting with 0; rest the same).
The rules are basically the same, I just made a few additions. The second tab “Test Data” contains test data that I have used for the workflow: Duplicate INV No.knwf (21.0 KB)
I managed to identify and display the similar duplicates. However, I don’t know how to read them separately based on the rules and display them as in the example above (1st rule → First Expression; 2nd rule → Second Expression; 3rd rule → Third Expression).
@hmfa Thanks to your help I was able to solve the previous problem. Can the problem here be solved and presented in a similar way?
@DA2023 did you tried to calculate the distance matrix? You could do that for one value or concatenate many into one. It provides an automated approach to identify, or as you call it, fuzzy matches.
Based on the distance of the strings you can create bins to break down the list into buckets if further manual verification becomes necessary.
Take note that this simple solution does string-within-string comparison. It generates false positives because it identifies invoices ex: 12345 as a duplicate of 12345432. It also generates false negatives because it does not identify ex: 12345 as similar to 12354 You will have a better solution if you use the distance matrix approach.
I would like to give you a quick update: I have implemented the distance matrix calculation. Then I divided the workflow into two parts (first part: to calculate the distance / second part: check which rule applies):
My goal is to identify and extract general similarities in the INV#. This should be done using the Distance Matrix Calculation.
I would then like to limit the data set using a plausible and appropriate ranking and thereby only recognize and read out possible or clear duplicates.
Then I would like to show which duplicates apply to the rules.
Finally, I would like to summarize the possible/actual duplicates based on the ranking that should be used for checking.
Thanks to your help, I seem to have succeeded in part. However, I don’t know which ranking would make the most sense here and how the whole thing can best be implemented. Do you have any ideas/suggestions or suggestions for improvement?