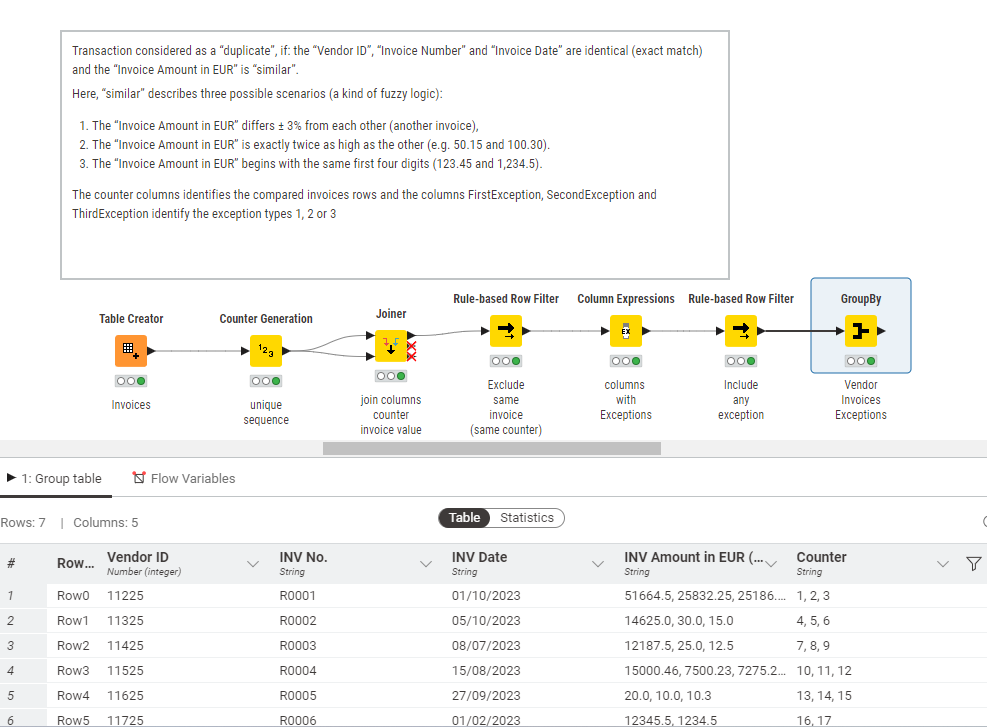
I’m working on a workflow that helps identifying duplicate invoices/payments.
Basically, there has to be a check for every invoice (each row in one column) in an excel file. The transaction should be considered as a “duplicate”, if: the “Vendor ID”, “Invoice Number” and “Invoice Date” are identical (exact match) and the “Invoice Amount in EUR” is “similar”.
Here, “similar” describes three possible scenarios (a kind of fuzzy logic):
The “Invoice Amount in EUR” differs ± 3% from each other (another invoice),
The “Invoice Amount in EUR” is exactly twice as high as the other (e.g. 50.15 and 100.30).
The “Inoice Amount in EUR” begins with the same first four digits (123.45 and 1,234.5).
It would be great, if the output could be similar to the “duplicate row filter”, with the duplicate classifier (chosen and duplucate) and duplicate identifier (e.g. row 12), so that the duplicates can be extracted and displayed seperately (e.g. for internal audit purposes).
Unfortunately, I have no idea on how to realize the “similar” criteria, as I don’t know how to do the check for each individual row in the column (check for all invoices, from invoice to invoice) and hope that someone can help.
My problem is that I don’r really know, how to define a check from invoice to invoice. The invoices have to be compared to each other. The problem is that I don’t know, how to do that in KNIME.
unfortunately, I am not allowed to use the real data. But I have created an excel table. Here, I have tried to implement the patterns, I would like to search for. Hope that helps.
it works perfectly well, many Thanks for your support!
Just for my understanding: with the “Counter Generation” & “Joiner” nodes you have duplicatet the input in order make it comparible to each other, right? Can you tell, where I can find additional info regarding coding in the “Column Espressions” node?
Yes, you are right.
The counter generation serves to uniquely identify each invoice.
The joiner relates the table to itself, to compare each invoice to all others from the same supplier and date, including itself.
Finally, it excludes lines where an invoice compares to itself because it is no exception (same counter).
The column expressions node is very powerful.
You can find more information about JAVA script rules here.