Hi @hhaw, and welcome to the KNIME community,
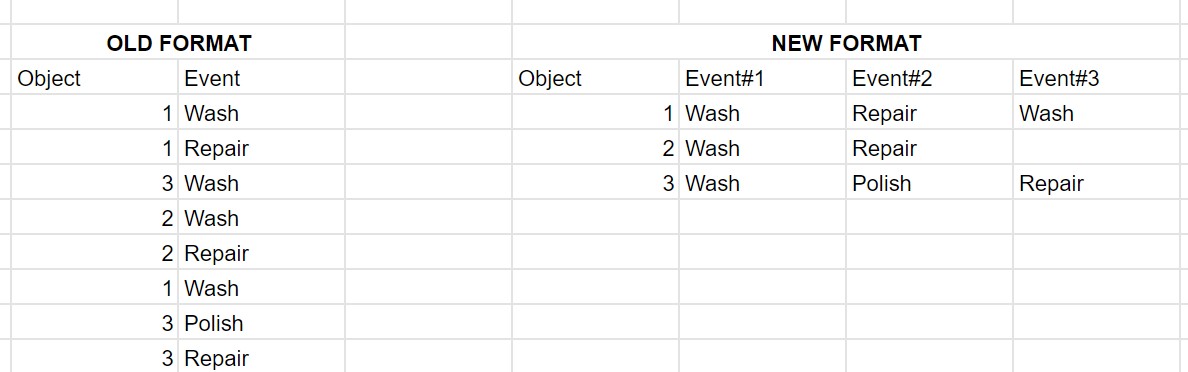
On the face of it, transforming your data from “row-based” to “tabulated” is a job for the Pivoting node, and I wish I could just say “use the Pivoting node” but it isn’t quite as simple as that.
In order for the pivoting node to work, it needs at least three columns to play with.
- The “groupings” which in this case will be the Object
- The data to be tabulated, which in this case is your Event data (“Wash, Repair…”)
- The values around which the data is pivoted… “Event#1”,“Event#2”… etc, and so we need to find a way of generating this information before we can pivot.
For your example. we need the data to first look like this
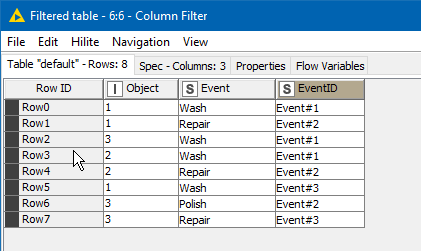
So the trick is how to generate this “EventID”.
Well there are a few ways, and others may come back here with simpler variations, possibly involving just one or two nodes, but the method I’ll use here is a combination of a Counter Generation, Rank and String Manipulation.
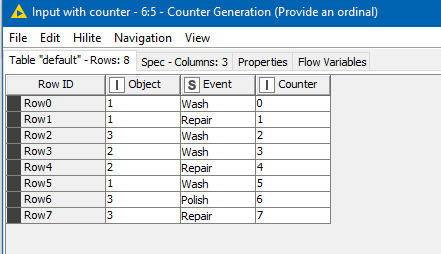
Firstly, the Counter Generation is used purely to provide an “ordinal row number” that allows the Rank node to do its stuff. Without this, the rank node would potentially try to rank your data but in the process would sort your event names, and they wouldn’t then be in the correct sequence. That probably makes no sense right now, but just go with it… 
So here is your data with the Counter generation applied. As you can see it simply provides a sequence number against each row
After that, the ranking node will be used to rank the Counter , grouping by Object, in ascending order, and we get this:
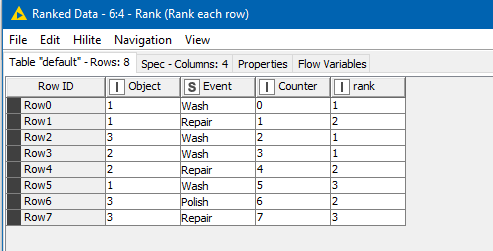
This ranking number is the basis for our “Event#n” values that we need, and this can be generated using String Manipulation to simply join the term “Event’#” with the rank that we just generated:
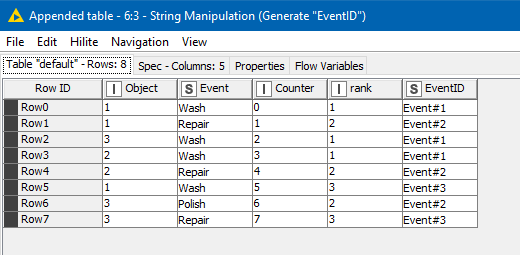
Filtering out the intermediate columns with a Column Filter (this step isn’t actually necessary as they would get filtered out by the Pivoting node anyway, but I’ve done it to demonstrate the columns required by Pivoting node), we get the data we need:
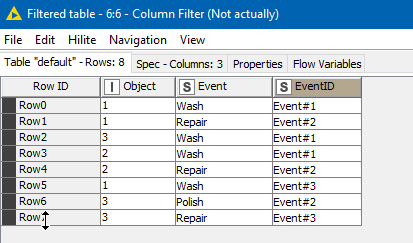
After this, the pivoting node can do its thing.
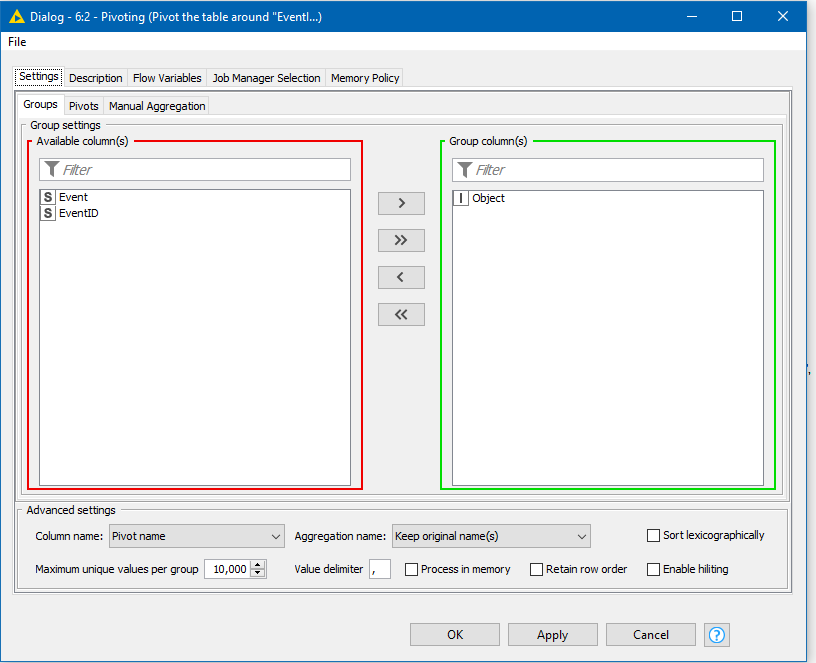
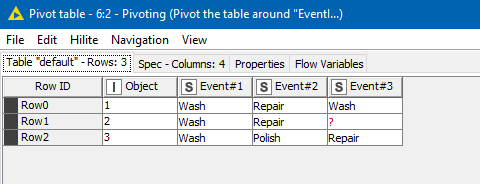
We tell it to group the data by Object
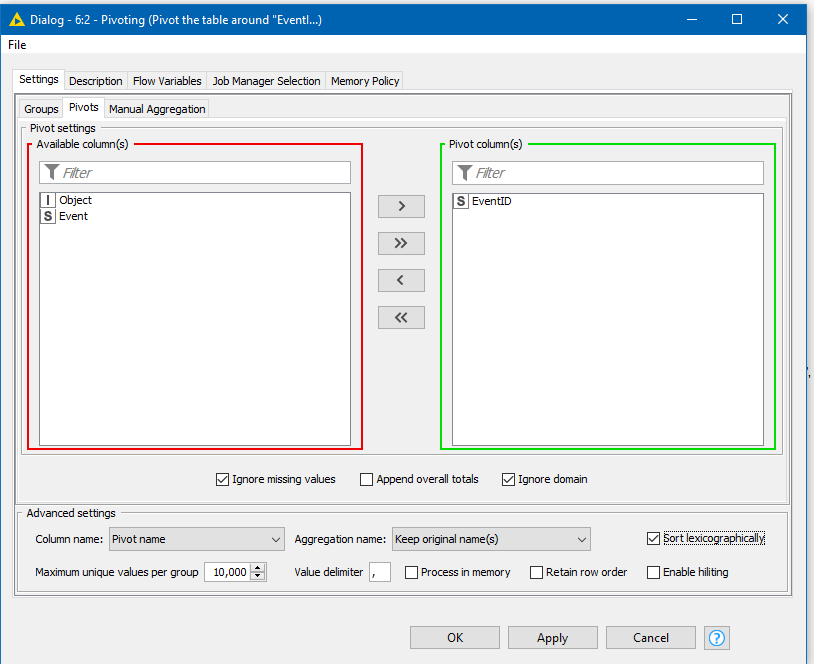
And pivot on EventID:
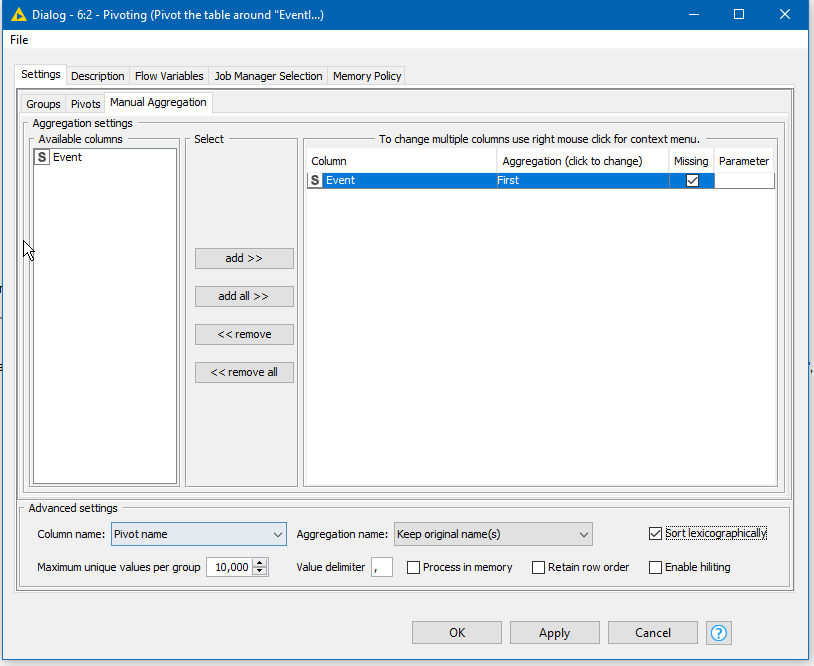
For the “Manual Aggregation”, in each case for each combination of “Object” and “EventID” we simply want to take the value of Event, and we can do that by simply specifying “First” as the aggregation method:
I also ticked the “Sort lexicographically” which I think means output the “pivot columns” in alphabetical order. If you find that you have numeric event# columns going over 9, you might want to untick this, as you may end up with column ordering such as “Event#1”,“Event#10”,“Event#2”,“Event#3”…
But anyway, the end result is this:
knime pivot example.knwf (14.8 KB)