Hi there,
I made an interesting observation training and scoring data with the XGBoost Tree learner and Predictor.
I use the same set of features to train 4 models (purchase probability for 4 different products) and one set of features to score customers using the 4 models. So far so good.
In two cases the scores look fine, in the other to cases there are duplicates in the customer ID.
All the input files are unique regarding the customer ID.
Since I can dedup the output, that’s no big harm (the duplicates have the same score), but it took me some time to recognice the fact, that I have duplicates in my scores, since I wasn’t expecting them.
Any ideas what’s happening there and how to prevent it?
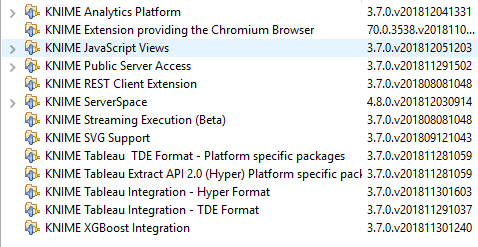
I am using KNIME Version 3.7.0 and XGBoost Integration 3.7.0v201811301240 on Windows X
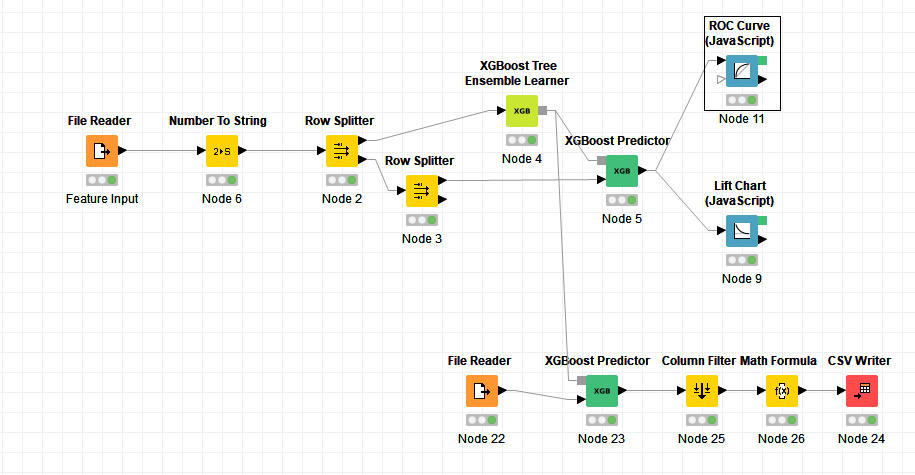
Workflow:
Cheers Tom