Hi all,
i am new in knime
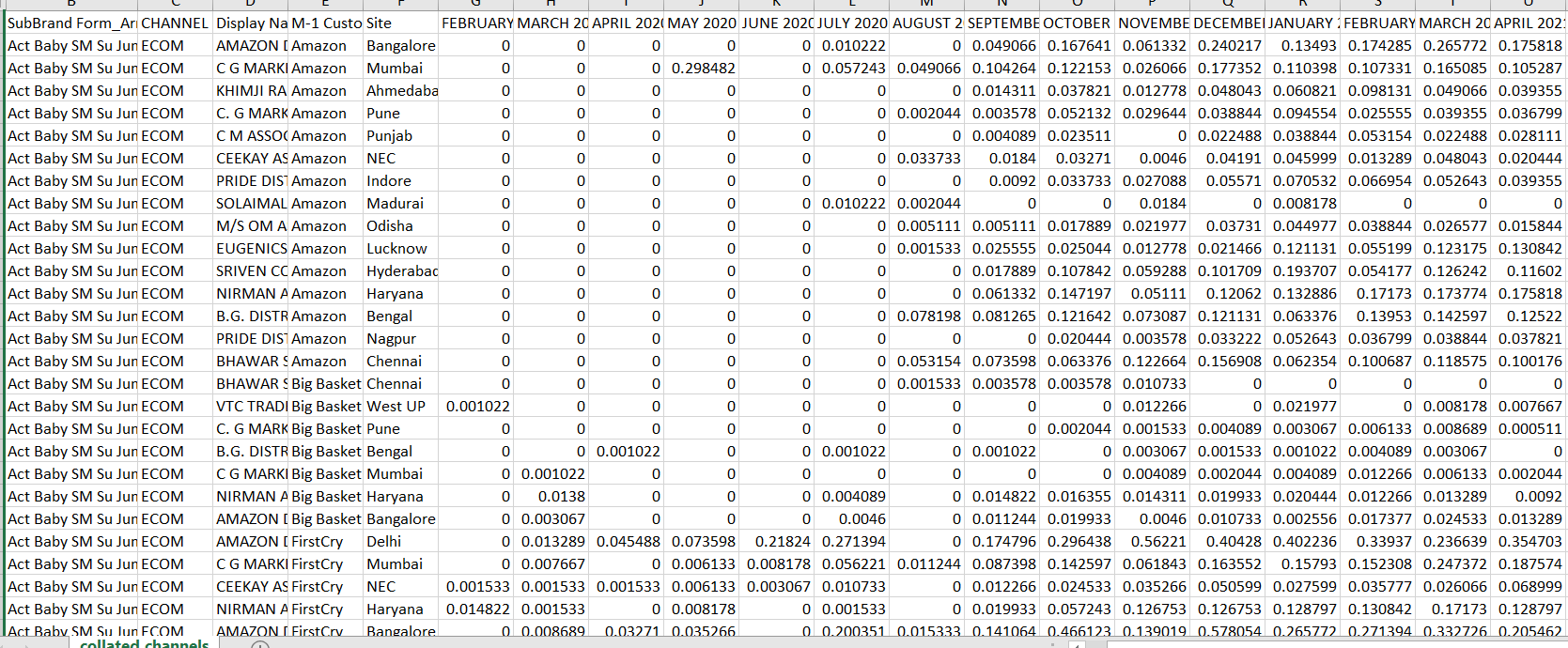
i have two files,
I want to achieve average of columns of (file 2)
in such a way that when “sub brand form” of (file 1) matches with the sub brand form of (file 2) then only those column should be selected for average of (file 2 ) which are tagged as valid field i.e “1” in (file 1)
(file 1):
To check if I got it right. So for Act Baby SM Su Jumbo you want to have avarage over every row in file 2 where subBrand is Act Baby SM Su Jumbo over Mar, Apr, Jun, Dec 2020 columns because there is 1 for those columns in file 1?
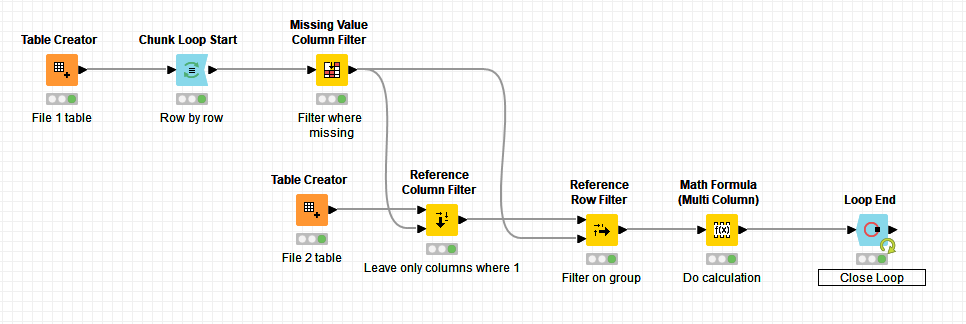
So loop over each row from file 1 and remove columns where missing value is (assumption is you will have missing values upon you import data into KNIME). Then use both column and row reference filter nodes on your file 2 data as preparation for desired calculation. Considering you are dealing with changing table columns you should use Math Formula (Multi Column) node to address it. Thing left is to shape your output the way you want. Workflow is attached. Give it a try and if any issues/questions feel free to ask.