I have a huge table wi more than 3000 columns. The most of the Column names are like this pattern.
Part1.Something_else.xyz
The “Part1” can be fife different Abbreviations
“Something_else” is alphanumeric String
“xyz” is also an alphanumeric String
Using fife Column Filter Nodes for the “Part1” is easy but now the “Something_else” part has between 20 and 80 different String that I don’t want to create up to 80 Column Filter Nodes
Which kind of Loop do I have to configurate? I tried the Column List Loop Start Nodes but I don’t understand the Flow Variable configuration.
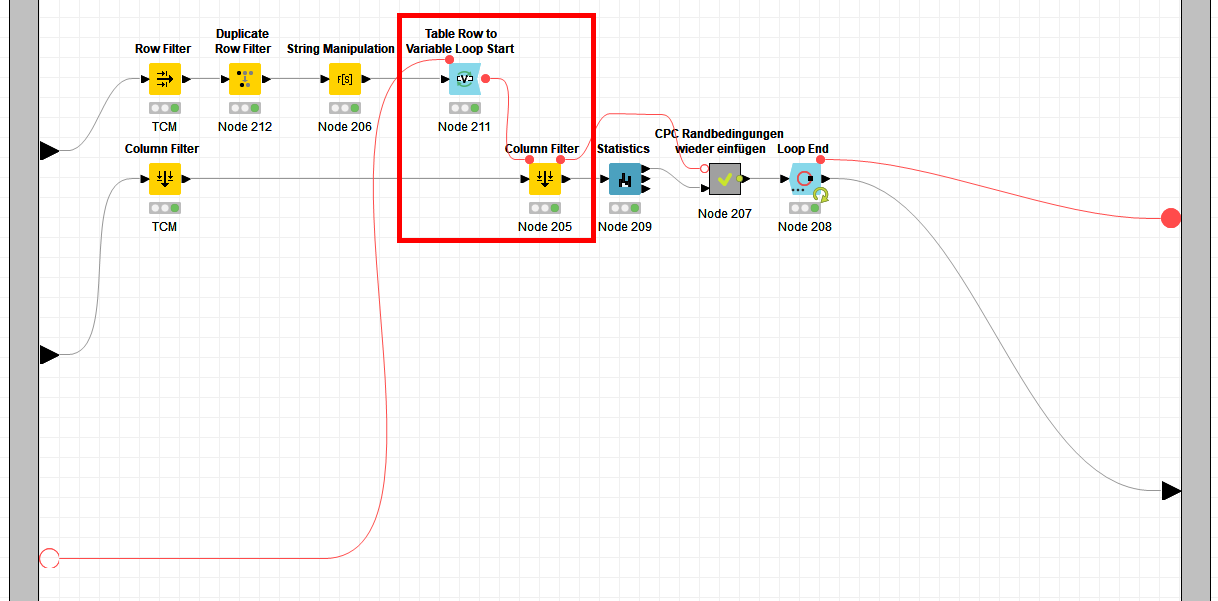
The pattern I have created with a Table Ro to Variable Node an String Manipulation (Variable) Node. Do I have to create the “type” variable as well let’s say “Wildcard” and caseSensitiv = 0?
If the goal is to just filter columns based on rules, then I would skip the loop altogether. Here is a quick workflow that shows how you can efficiently filter or split columns based on any number of column name rules you like.
thanks for your example workflow. I think we have the similar idea.
I have now a solution for my problem. In the top data lane I filter the “Something_else” String and add the wildcards in the String Manipulation Node. The result is “.Something_else.”. With this wildcards I start the Table Row to Variable Loop Start an now control the Column Filter Node
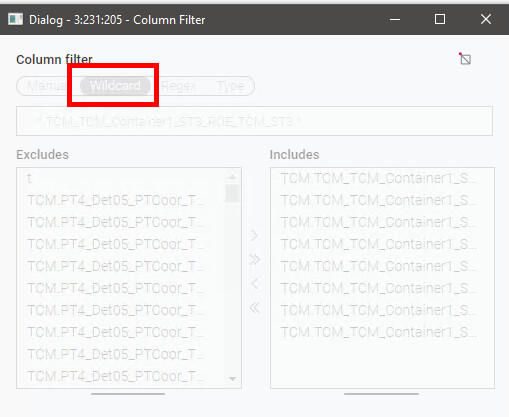
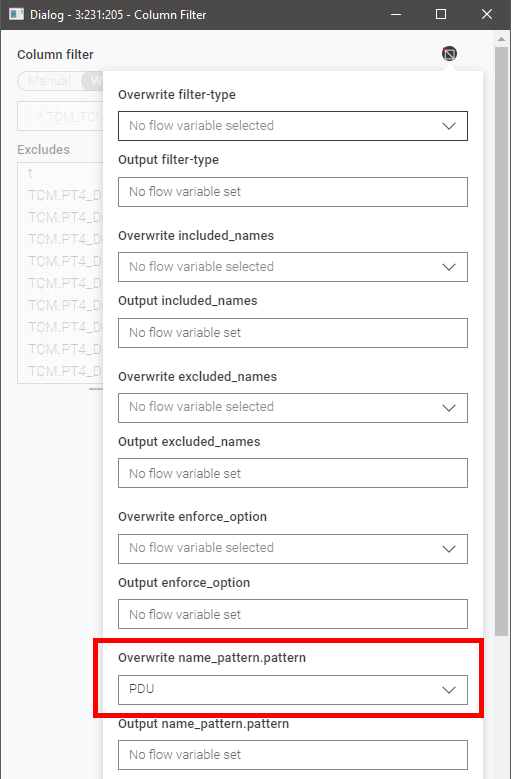
I was surprised by the configuration of the column filter node. You first have to click on “Wildcard” in the Column Filter Node and then select the flow variable in “Overwrite name_pattern.pattern”. Then, per loop pass, it filters for the corresponding columns that have the same wildcard in the column name.