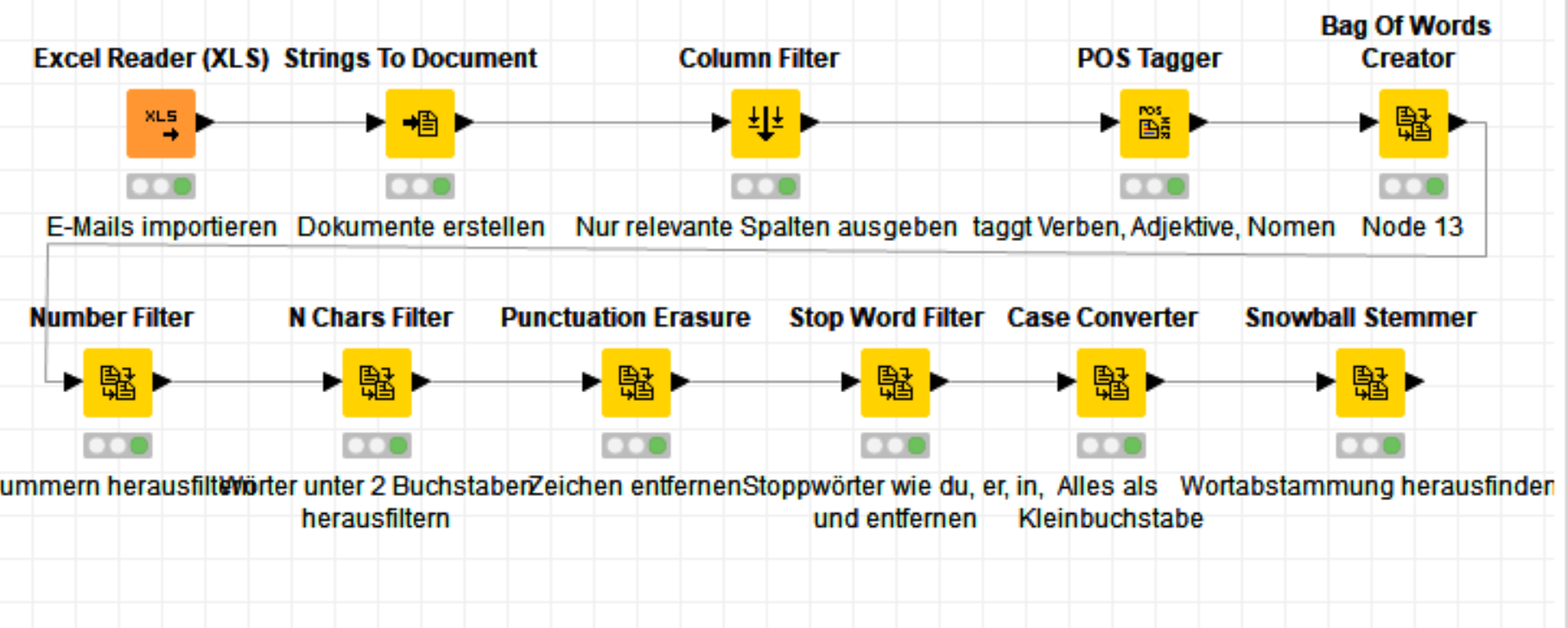
Hi, I’m new here because forgive me if I ask silly. I would like to create a cluster analysis with unstructured data or text documents. I have uploaded an Excel file that contains only one column. Although I have connected the individual nodes but I have the feeling that none of these works. For example, ‘Bag of Words’: After being converted to a document, the columns ‘Document’ and ‘Term’ are displayed. Further processing must be done on the column ‘Term’ or 'isnt it? For example at the n char node I want to delete all words under two letters, but it does not work.
Most probably you forget to check “replace column” box in Prepossessing of certain nodes; in this case you transfer the unprocessed document to the next node.
2 Likes
Hey Canan,
the ‘Bag of Words’ node has to be applied after the preprocessing/tagger nodes. The preprocessing/tagger nodes only work on document columns. So, if you create a BoW before preprocessing, the preprocessing afterwards would filter the documents, but the term column would stay the same. It worked this way in previous versions of KNIME and unfortunately it is still shown this way in the documentation, but we will fix that.
For textprocessing examples, you could visit the example server within KNIME (https://www.knime.com/example-workflows) and browse to 08_Other_Analytics_Types/01_Text_Processing.
Additionally, like @atabek said, you have to keep an eye on the document column settings in the node dialog of the nodes, so that you keep sure that you always preprocess the column you want.
Cheers,
Julian
1 Like
Hey,
I saw that there is an example workflow which suits my needs, the document classification workflow. What I want to do is that I have approx. 900 E-Mails or better said E-Mail bodies in one Excel Sheet. There is no other information. The first thing that i have to do is to find out which categories this E-Mails should have for example there are a lot of E-Mails regarding to contract termination or locked accounts and so on. My classification model should be able to predict the category of new E-Mails. the problem that I have is that there are more than 10 categories. What kind of node is possible to handle this kind of problem, because in the example there are only two categories.
https://www.knime.com/document-classification-example
Thanks in advance,
Canan
Hi Canan,
this looks like a general classification problem where you have only a few data points for some classes. Maybe try first an equal size sampling based on the class column. As classifier I would try first a single Decision Tree to get a base line and then optimize the result by using e.g. Tree Ensembles and GBT.
Hope this helps.
Cheers, Kilian
1 Like
Hey Kilian,
thanks, I will try it, but how can I equal size sampling based on the class column? Am I have to first convert the categories into classes to then apply the model? As you can see in the picture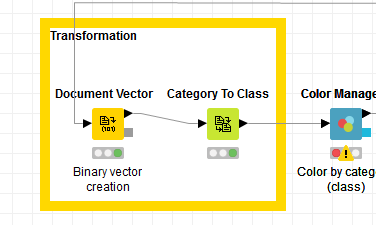
Thank you,
Canan
there is a node called “category to class”, is there a same node for multiple classes?
You can use the node “Equal Size Sampling” after the “Category to Class” node to do the sampling.
Cheers, Kilian
1 Like
Thanks Kilian 

I will try it out.
Canan
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.