Buen día
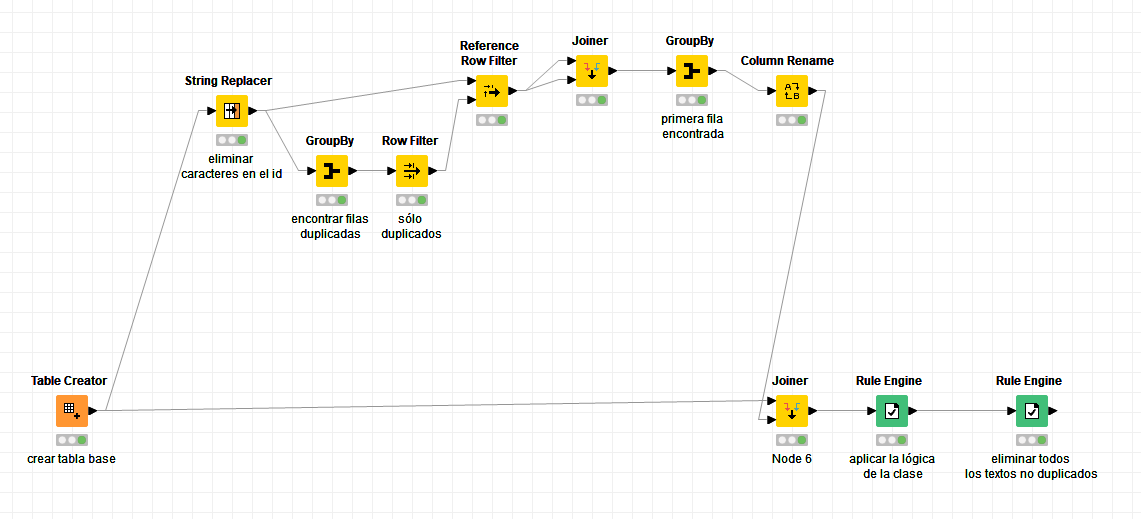
Me gustaría saber si hay una manera de usar el nodo “Duplicate row filter” con expresiones regulares o aluna alternativa y recibir un resultado de la siguiente manera.
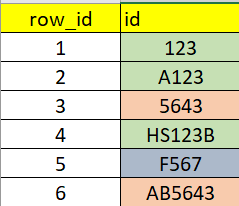
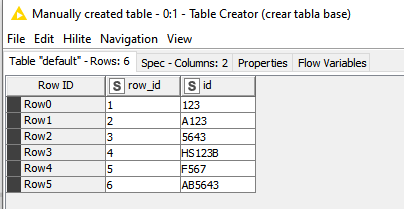
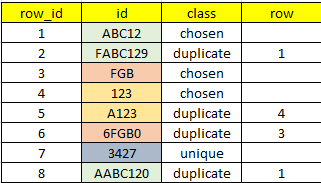
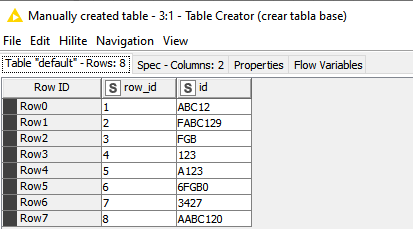
Supongamos que tengo esta tabla
Lo que deseo es ver si un registro se repite en una parte de otro, en este caso los verdes contienen “123”
Still cannot read/write spanisch… hopefully auto-translate is somewhat understandable
Todavía no puedo leer/escribir en español… espero que la traducción automática sea algo comprensible
¿Puede explicar cuándo un caso se considera duplicado?
¿Qué parte del texto es decisiva?
¿Si más de tres caracteres del texto son iguales? ¿O cuál es la lógica?
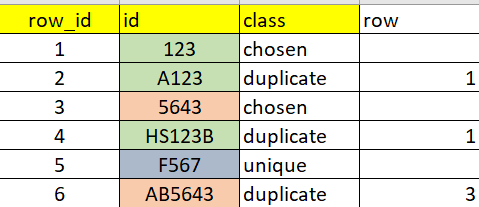
Antes que nada pido una disculpa, ya que la ultima respuesta que deje no era correcta, así que la he eliminado.
La lógica es la siguiente:
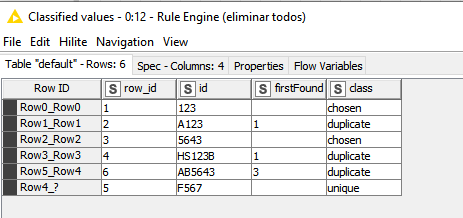
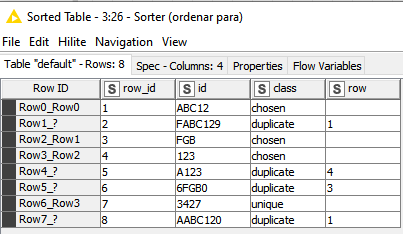
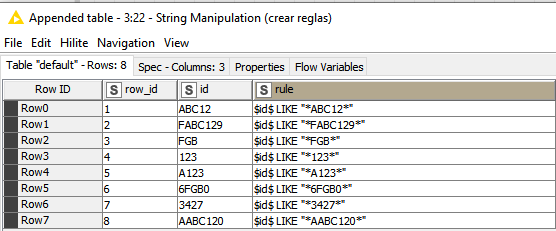
Tomar el valor de la primera fila completo (ABC12), entonces paso a siguiente fila (FABC129) y si encuentra dicho valor en algún lugar de la segunda entonces esta incluido y se marca como duplicado y así sucesivamente con todas las filas, hasta llegar a la fila 8 (AABC120). Luego, seria tomar la segunda fila y hacer lo mismo con todas.
esta solución también encontraría una coincidencia en las filas anteriores - si no coincide con ninguna otra fila (no estoy seguro de si esto tiene que ser excluido o no)
Por ejemplo, la fila 1 contiene ABBB1 y la fila 7 contiene B1…
marcaría la fila 1 como duplicada y la fila 7 como escogida
también una sugerencia para futuras preguntas.
Si creas tu pregunta en inglés, recibirás ayuda mucho más rápido
Creo que el foro en inglés es mucho más activo