This is how my workflow looks like:
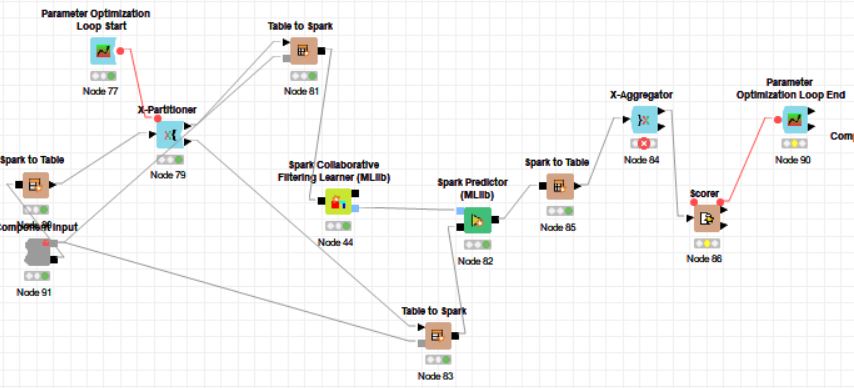
I tried looking at the data itself but there are no duplicates in it. DBscan on the same data was able to produce an output.
Any help is much appreciated.
This is how my workflow looks like:
I tried looking at the data itself but there are no duplicates in it. DBscan on the same data was able to produce an output.
Any help is much appreciated.
When you use Table to Spark, the rowids generated for each Spark table are new rowids starting from 0. This would lead to overlapping rowids. If you are using spark that implies your data is quite large and so I recommend instead that you use the Spark Partitioning node. Cross validation is great when your data is small-medium, but for larger data it is unnecessary in my opinion. As well, the set up would be quite complex (going from table to spark and spark to table may be costly) so I would avoid X-nodes.
Thanks for your answer.
Acctualy my Data is not that big, im using Spark because of the Collaborative Learner for my Movie Lens recommendation Engine.
Cross validation would be helpful in this case. Spark Partitioning Node dont support a slpit into more than 2 parts and after that im only able to use one of them for the loop. Is there a way to replace X-Partitioner in a Spark Context ?
Hello,
Unfortunatley, we do not have dedicated nodes for this with Spark DataFrame Input/Output.