Hi,
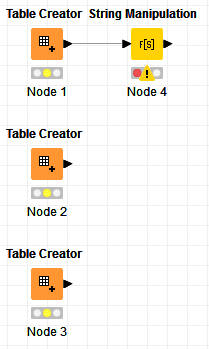
We have a workflow with a component and a meta node that we want to run in series. The component extracts data from a database and writes it in knime tables. The meta node reads from the knime tables and does some data cleaning steps and outputs eight tables of data which are used to generate excel files and emailed to end users. We also store data about the processing in a QA/QC database. Here is an image of the workflow:
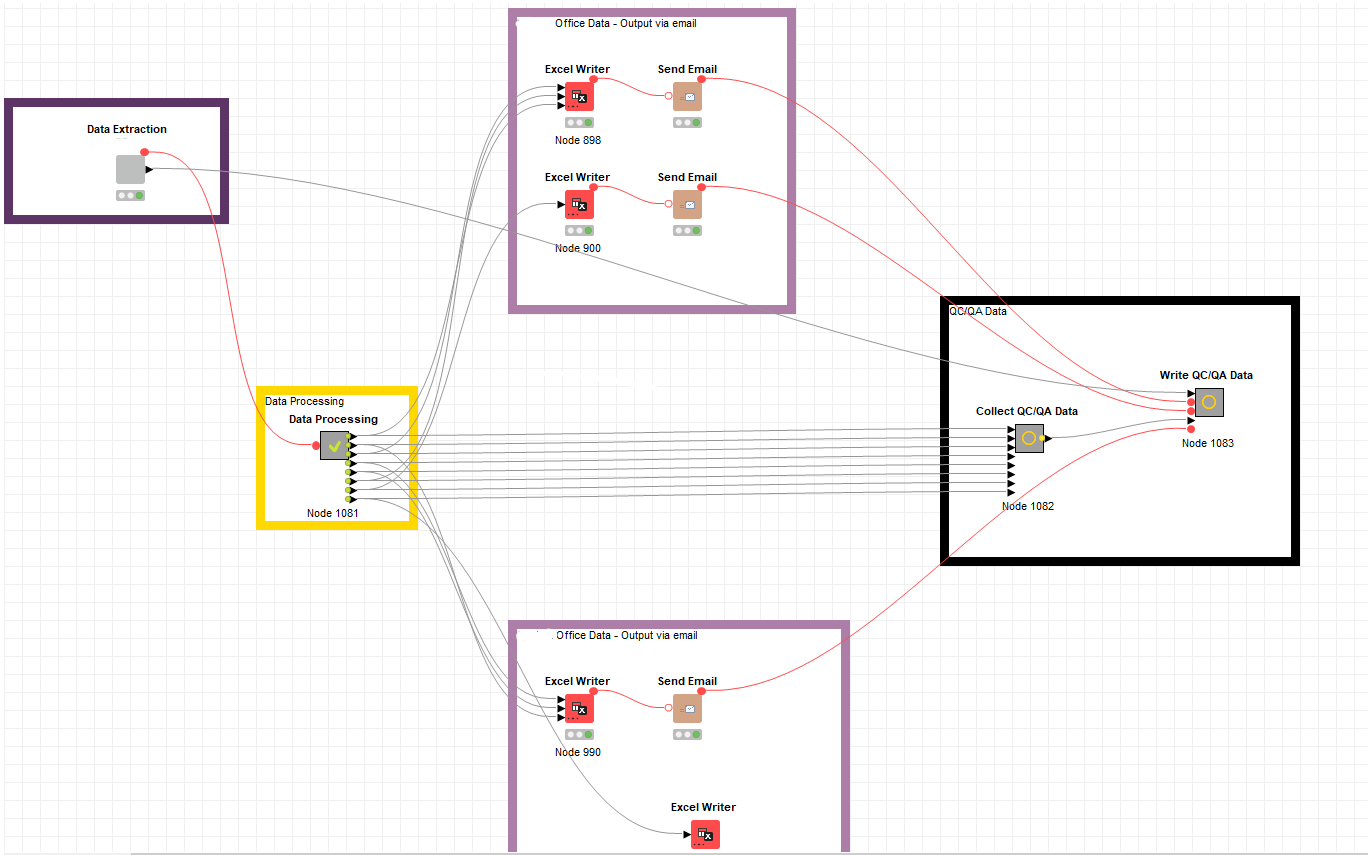
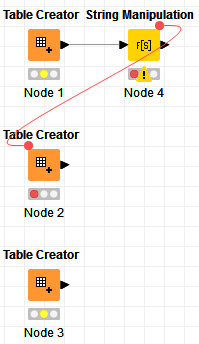
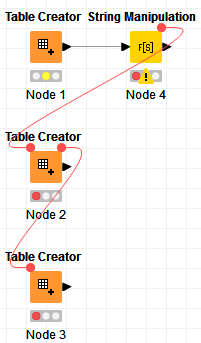
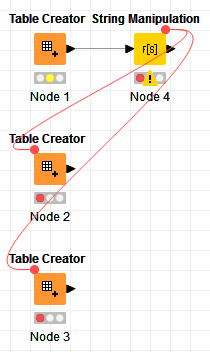
We do not want the data processing meta node to run until the Data extraction component is finished. We added a flow variable connection between them as suggested in this forum article. The article suggests adding a flow variable connection between the nodes to force the second node to wait to start until after the first node finishes. We tried this but it doesn’t seem to work correctly in our development Knime server. Oddly, it does seem to work correctly in our production server, though. We are enhancing the workflow and the versions on the development and production servers are not the same, although we have compared the connector and do not see how they may be different.
This scenario is a little different because we are not passing a table or other element between the two nodes except a flow variable.
Is there another way to force them to run in series? Or perhaps we are missing a configuration parameter for one or both of these nodes?
We are using:
KAP(Client): Version 4.3.2
KS(Server) :version 4.12.2
Executor: Version 4.3.2
Any advice would be appreciated.
Thanks!