Is it possible to combine entity tags from a python script using something such as Spacy or the ChemDataExtractor with further processing using the text processing extension in Knime? It would be good to be able to mix and match depending on speed and capability but I don’t know how to handle documents with python and append tags to the terms. Ideally, I would like to be able to take my text, run it through Spacy to identify named entities and then feed these in to the document for topic analysis / clustering etc.
Hey @EwarWright,
it is not possible to convert the text as it was processed in spaCy to KNIME documents directly. The only way I could think of would be to provide the entity tags as an output of the Python Script node, then convert the original text to documents using the Strings To Document node and finally, applying the tags using Dictionary Tagger, Dictionary Tagger (Multi Column) or Wildcard Tagger.
Since spacy uses other tokenization models, the results might differ from the original results spacy provided.
Best,
Julian
Thanks for the response Julian,
That is a shame as it would have been nice to have an easy way to feed in tags from external libraries then mine them with knime. One way around it might be to modify the text that has been tagged in the python node such that a regex tagger could work with it (eg Company → |Company(Org)|) and then process it with a wildcard tagger and just clean it up once it is back to string level. The other would be to do most of the pre-processing externally and then just run the strings to document on the final set.
Thanks,
Ed
Maybe we can find a workaround that is sufficient for you.
Do you have a sample text or sentence together with the output that spacy creates for these sentences? Just wondering how the output looks like. I guess we can extract the entities and use a Dictionary Tagger afterwards.
Best,
Julian
At the moment I don’t really have any sample text to look at, it was just a case of having used both in the past I was thinking that it might be good to combine the two in future workflows. I’ll have a look and see if there is something suitable to compare the two and will post when I find it.
1 Like
Hello @EwarWright
You might be interested in our extension Redfield NLP Nodes, where we have integrated Spacy into Knime. You can process Document type data with these nodes using Spacy models.
You can take a look at the example workflow on Hub: Analyzing Breaking Bad subtitles with Redfield NLP nodes – KNIME Hub
3 Likes
I actually have this same question @julian.bunzel. While the Redfield NLP nodes are handy, they cost money and $250 may be too much or people to manage. spaCy is free and in a few lines of code you can easily tokenize, lemmatize and more leveraging SOTA transformer models and more.
Obviously the handy thing with KNIME is simply integrating it into a workflow. Here are some example of output with sample data when tokenizing.
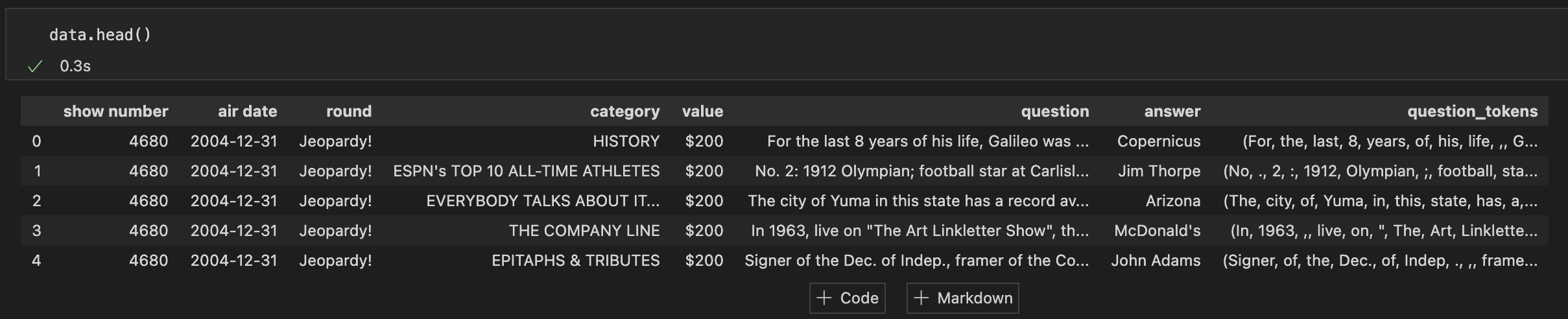
Running this code in KNIME the following error outputs:
ERROR Python Source 0:1 Execute failed: No serializer extension having the id or processing python type “Doc” could be found.
Unsupported column type in column: “question_tokens”, column type: “<class ‘spacy.tokens.doc.Doc’>”.
In the dataframe the column is a pandas series and datatype is spacy.tokens.doc.Doc
I’ve been researching how to process text with spaCy first and then move it out of the python node and into the workflow but have not had any luck yet.
Any insights as I continue my research would be most appreciated!
From what I can gather, the only way to do this would be to essentially run the model in Spacy to get things like entity tags and then concatenate the original text with the entity of interest (eg text[TAG] instead of just text) and then return that as a string column from the python node. After that, you would then use a wildcard tagger to look for the tags to convert in to knime entities in a document. At the moment it feels like something of an either / or situation where all the text cleaning and feature generation is done in one of knime or spacy rather than being able to mix and match bits of the pipeline as required.
Hello @EwarWright
Now Spacy is supported and integrated with Knime Text Processing extension. You can check it here:
Perhaps you may also find this simple useful:
1 Like
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.