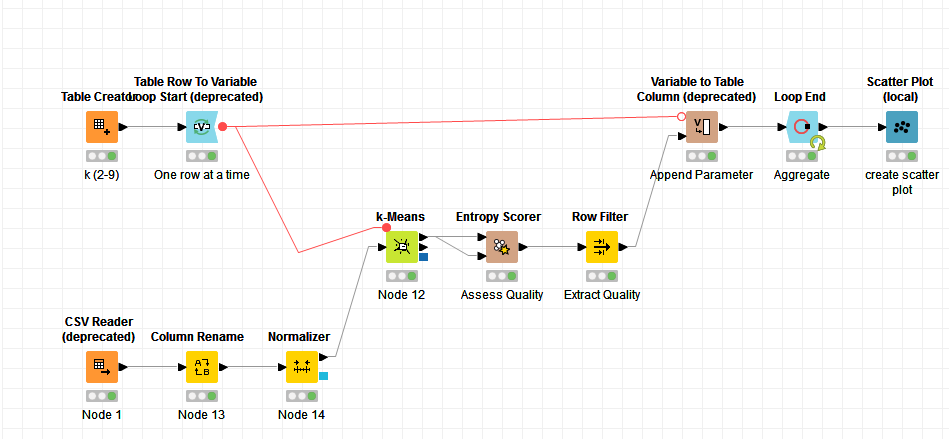
I want to calculate entropy of K-means clustering using Entropy scorer node. I’m using USArrest 1973 dataset (Details). For entropy scorer node, we need to have reference column but this dataset does not have any.
I seem to remember in some prior examples that use the Entropy Scorer, you actually end up connecting the output port from the k-Means node to both ports of the Entropy Scorer:
This looks a little weird but in some cases gets the job done. If you’re still having trouble, maybe you can post an example workflow of your progress so far?
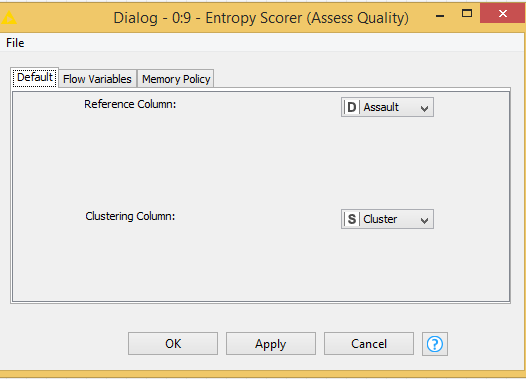
Now if I change the reference column from “Assualt” to “Murder” Entropy change.
I’m clueless about this. I need to find out the optimal number of clusters for K-means. And As far as I searched, it can be easily done via Entropy scorer. For that it requires reference column. So I need your advice on this.
Well, your dataset doesn’t have a reference cluster column at all - you only have the state and the 4 numeric columns. So I don’t suppose you can use this method.
You may want to check this recent forum post for some additional suggestions about the elbow method and Silhouette coefficient: Clustering in Knime
Your response is quite helpful.
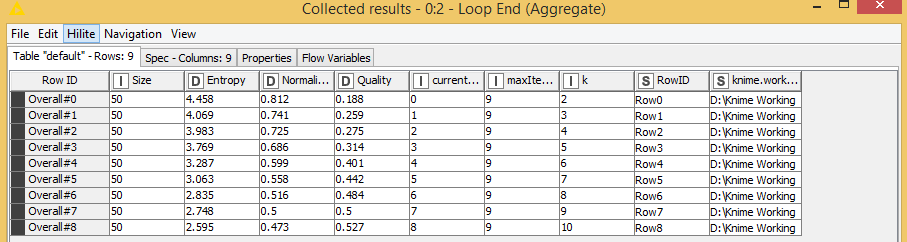
One more thing: whenever I searched for the problem online, it states that there should be 4 clusters. But when I use the above extension, it shows that there should be 2 clusters. So any suggestions?