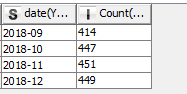
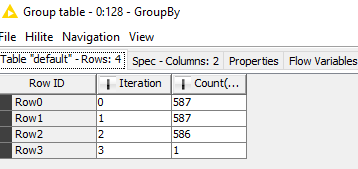
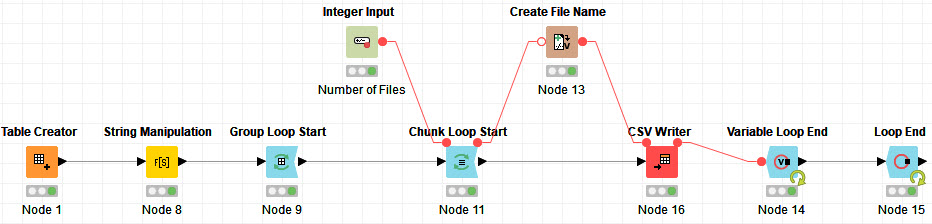
I created a solution equally divided file 2.knwf (251.3 KB) that uses a Partitioning node twice, within a GroupLoop (for every month). So every month there are 3 equal (more or less) groups.
Hi @89trunks and welcome back to the KNIME community forum,
In addition to the solution by @HansS, Here is a workflow in which the number of files for division can be specified. So you can divide your file into any number of files, and the number of rows in all files are almost equal.
Hint:
If you want to divide dates in such a way that each file contains dates sequentially (e.g. the first 10 days in the first file, the second 10 days to the second file and the third 10 days to the third file), then you need to use a Sorter node after the Group Loop Start node.But if you want the dates to be shuffled before division, then use a Shuffle node after the Group Loop Start node and a Sorter node before the CSV Writer node.
Nice I didn’t know that partioning can be used like that. But what if the data is much bigger and I have to divide it into 400 equally parts? Can I do something like that ?
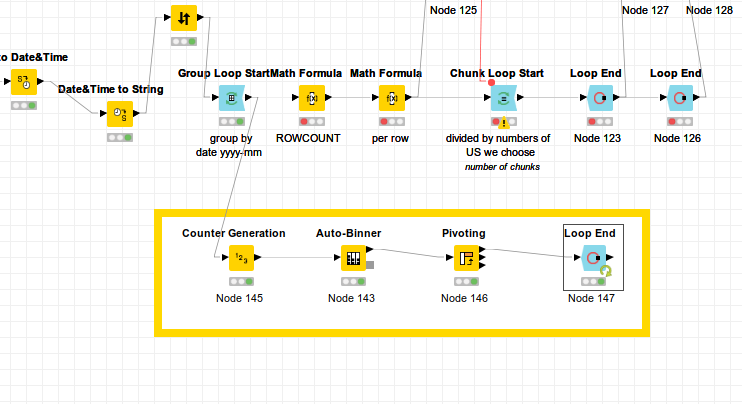
In that case, try the Auto-Binner node, in this example equally divided file 3.knwf (179.2 KB) creating 20 equal groups per month. Only the last bin (in this case Bin20 ) is not equal to the other bins.
Hi I was hopeing you may have an idea or hint how to get out of another problem.
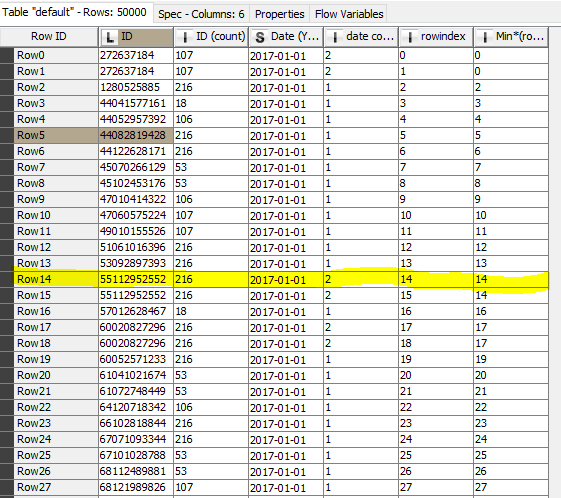
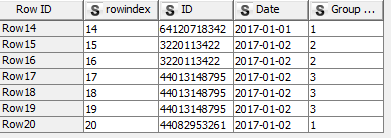
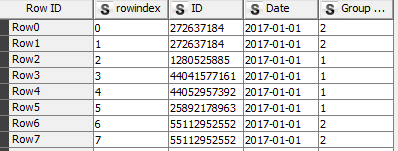
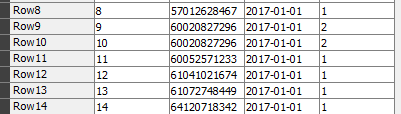
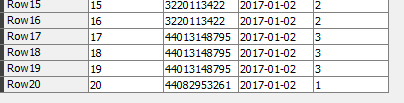
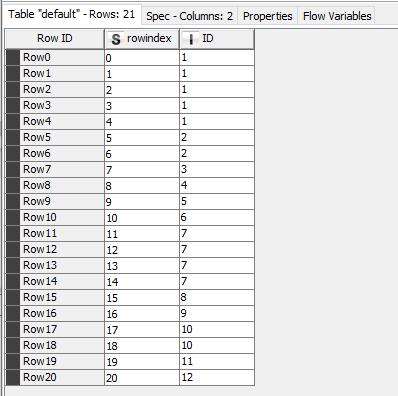
It happens that I need to divide table as ealier into equally divided files but the next condition is that if the end of that part is a first/middle or any other row of the same values it has to take them whole. to that part . In above picture we have numbers of ID and dates that some occures more than once. If for instance I devided this data into two parts I would like to that both rows go to the same part. So let’s pretend that equally divided file will have rows from 0 -14 and 15- 30. But row 15 has the same ID and date - so it should go to the same part.
I do not know if this is good visualisaton of this problem.
My data is big and I wolud like to split it as equally as possible into X parts but when the last row of occures in next row I want it to be placed into the same “bin”.
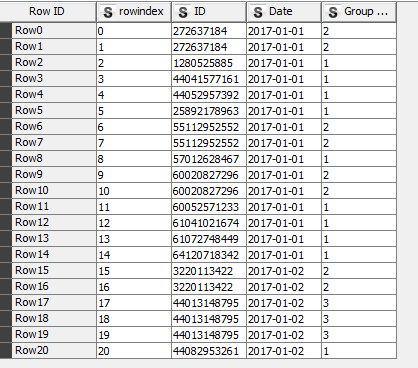
Data:
dividing into 3 equally parts: (21 rows / 3 = 7 rows per part)
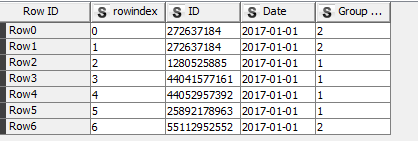
part 1
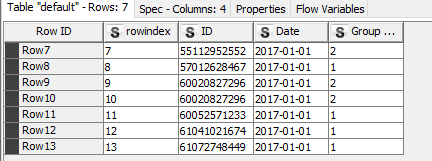
part 2
part 3
but my goal is to have something like:
part 1
part 2
part 3
I do not know if it can be done … I did not find good solution.
Best solution will be
that it will take always x rows (acording to dividing) but if the last one occures again it takes till the last one (stops when the new one showes up).
the same thing as 1) but it counts desired number of rows and if for instance 7th is repeated n times it omits it and takes next single one. The next part will start with what is omitted ang goes on.
Do you think that something like that can be achived?
I tried group loop/ chunk loop start/ partioning and other nodes with no results.
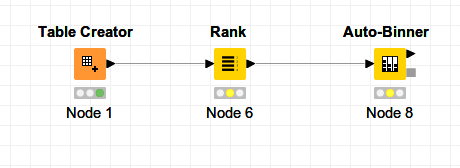
How about adding a Rank node an rank your ID. Then do a Binning on the ranked values. The only condition to be met is that you have your table sorted by ID.
See this example equally_dived_file.knwf (17.9 KB)
The solution by @HansS works great. I think you should rank on Date and IDs then bin the table.
Or
If I have got you correctly and it is fine to remove duplicates then I think there is a straightforward solution for this:
Using Duplicate Row Filter or GroupBy on ID and Date columns makes it possible to remove duplicates then you can do the same approach as before to divide the table.
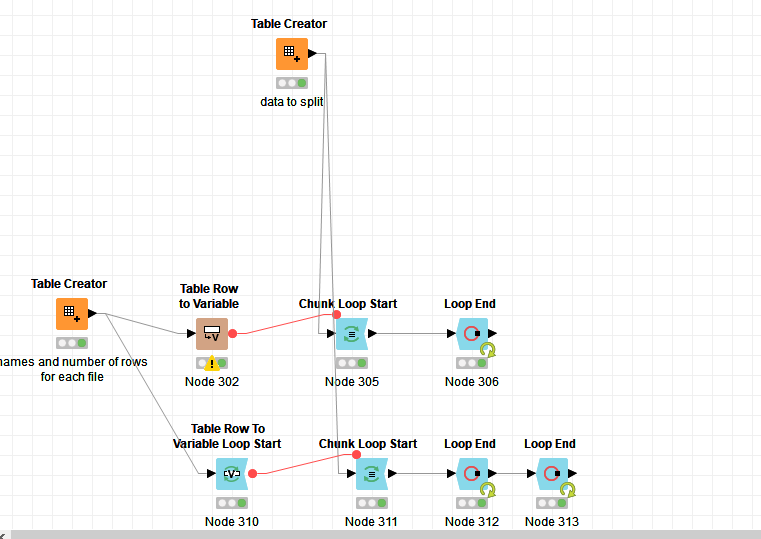
I was wondering is it possible to divide one file into x files were each one has different specify number of rows with the similar rule as width binning.
I was experimenting with chunk loop start with row per chunk as variable. But somehow can’t do it.
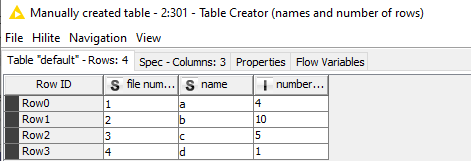
just for exercise it is 4 each with speciic number of rows.
So the whole data sholuld be splitted into 4 files where first has 4 row, second 10, third 5 and forth 1. If something is left it should leave it be and not include it in any file or create one exrtra file where the excess rowes will be placed.
So my first goal is to divide it according to x number of rows for each file. (this data is small and I have to work on very big ones - so this is just to illustrate the problem)
My second goal is insure rule that this original topic originate. I tried Rank and Auto binding but no result.
If needed I will create seperate topic for this but it somehow relate to this.
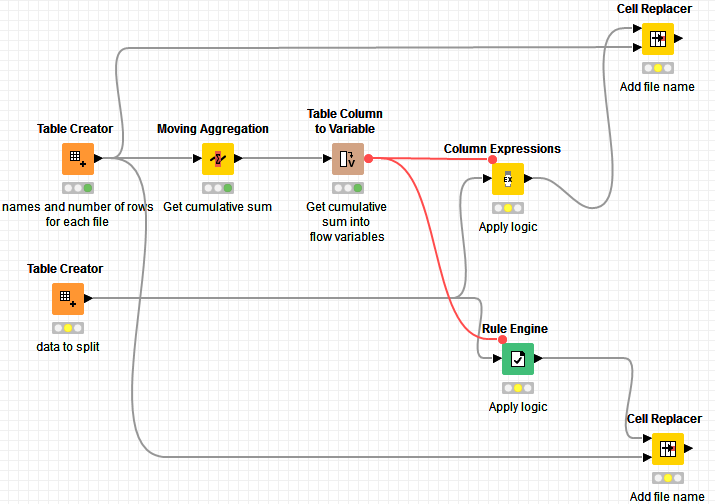
if I got you right you can avoid loops in this case. So by using Moving Aggregation node you can calculate Cumulative sum i.e. in which row index each file ends. Then transform those numbers into variables and feed them into Column Expressions or Rule Engine node where you apply your logic with simple Ifs. After that use Cell Replacer node to add file name.
ipazin you are genius - this should do the trick but in my case I have bigger data and have to divide it into almost 400 files with different numbers of rows. I will have to work on the ifs sentecnes. But will manage it.
With the loops how can I achive the same result? Just of curiosity I was tying it but it failed. I mean did not get the same result as you.
glad it helps. Regarding loops. Tried it but now not really sure how to do it without making it too complex. Loop to use for processing different number of rows in every iteration is a Group Loop Start but in this case is not applicable as what you are doing is defining “groups”. So, forget about loop in this case