I am using an Excel Reader node to read several hundred Excel files. All should have the same structure (i.e., column names), but invariably there is a file that does not conform and I get an error that indicates, “The following columns are not contained in all source files:”. Is there a simple solution to identify the offending file?
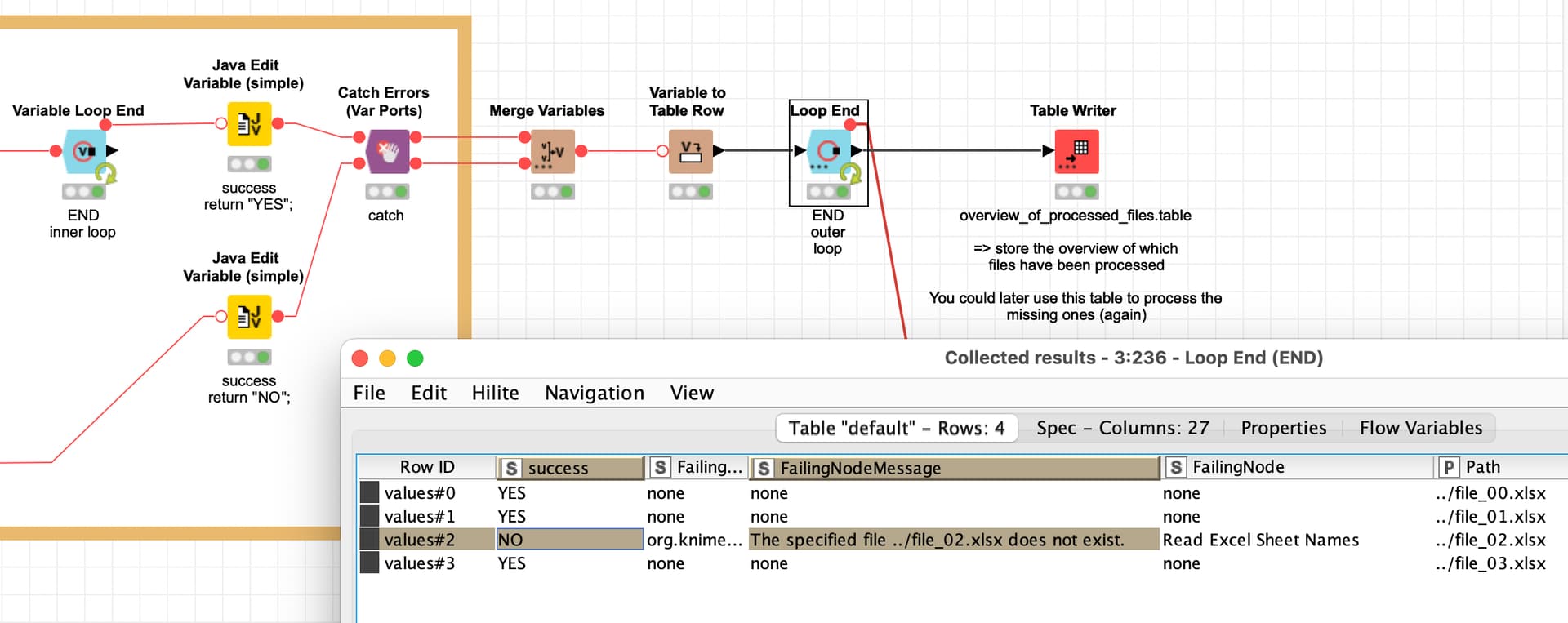
@kmarrs901 the concept would work something like this (only a screenshot in the thread):
A sample workflow with a try-catch block that could be modified:
You could record which file failed. Ans also later use that collection to maybe process the failed files again.
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.