Hello all.
I am trying to install the python extensions to run a script but there is an error installations with this message :
" An error occurred while installing the items
session context was:(profile=KNIMEProfile, phase=org.eclipse.equinox.internal.p2.engine.phases.Install, operand=null → [R]org.knime.python.giskard.channel.bin.win32.x86_64 5.3.0.v202406260950, action=org.knime.product.p2.actions.ShellExec).
ShellExec command exited non-zero exit value:
Installation of the Python extension failed:
critical libmamba Download error (35) SSL connect error [https://conda.anaconda.org/conda-forge/win-64/ca-certificates-2024.7.4-h56e8100_0.conda]
schannel: next InitializeSecurityContext failed: SEC_E_ILLEGAL_MESSAGE (0x80090326) - This error usually occurs when a fatal SSL/TLS alert is received (e.g. handshake failed). More detail may be available in the Windows System event log.
See the files “C:\Program Files\KNIME\plugins\org.knime.python.giskard.channel.bin.win32.x86_64_5.3.0.v202406260950\bin\create_env.out” and “C:\Program Files\KNIME\plugins\org.knime.python.giskard.channel.bin.win32.x86_64_5.3.0.v202406260950\bin\create_env.err” for details.
Please refer to the documentation at Create a New Python based KNIME Extension.
If the current system has no or only restricted internet access a special setup for an offline installation is required. See Create a New Python based KNIME Extension. "
I have checked my preference configuration in Python tab and it is set up to ‘bundle’. I also checked the bundle content and Pandas Lib is included.
Here is the script I am running and going more in details i see that the second line of my script has a ‘not quick fix available’
My Script:
import knime.scripting.io as knio
import pandas as pd #here appears the first line error
Load the input table
df = knio.input_tables[0].to_pandas()
Sort the dataframe by ‘Customer’, ‘Product’, and ‘Date’ in descending order
df = df.sort_values(by=[‘Customer’, ‘Product’, ‘Date’], ascending=[True, True, False])
Initialize new columns ‘New_SI’ and ‘New_SO’ with the original ‘SI’ and ‘SO’ values
df[‘New_SI’] = df[‘SI’]
df[‘New_SO’] = df[‘SO’]
Function to process each group
def process_group(group):
# Find indices where there are 3 consecutive zeros in ‘SI’
zero_indices = group.index[group[‘SI’] == 0].tolist()
for i in range(len(zero_indices) - 2):
if zero_indices[i+1] == zero_indices[i] + 1 and zero_indices[i+2] == zero_indices[i] + 2:
# Set all previous ‘New_SI’ values to zero
group.loc[:zero_indices[i], ‘New_SI’] = 0
break
# Find indices where there are 3 consecutive zeros in 'SO'
zero_indices = group.index[group['SO'] == 0].tolist()
for i in range(len(zero_indices) - 2):
if zero_indices[i+1] == zero_indices[i] + 1 and zero_indices[i+2] == zero_indices[i] + 2:
# Set all previous 'New_SO' values to zero
group.loc[:zero_indices[i], 'New_SO'] = 0
break
return group
Apply the function to each group of ‘Customer’ and ‘Product’
df = df.groupby([‘Customer’, ‘Product’]).apply(process_group)
Sort the dataframe back to the original order
df = df.sort_values(by=[‘Customer’, ‘Product’, ‘Date’], ascending=[True, True, True])
Output the result
knio.output_tables[0] = knio.Table.from_pandas(df)
I continue to investigate and have identified that although my ‘python setup’ is using the bundle mode, the pandas lib is failing to execute.
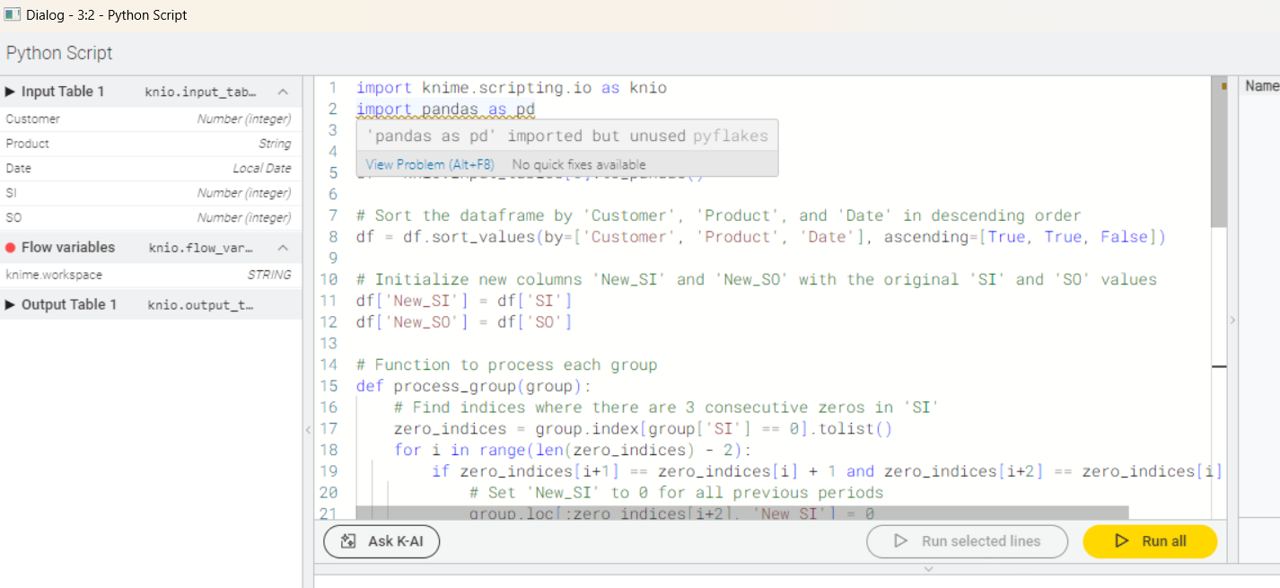
@Xtian you could try and do a fresh installation. Then you could provide us with a clean log in debug mode:
- Set logging level to debug in the preferences
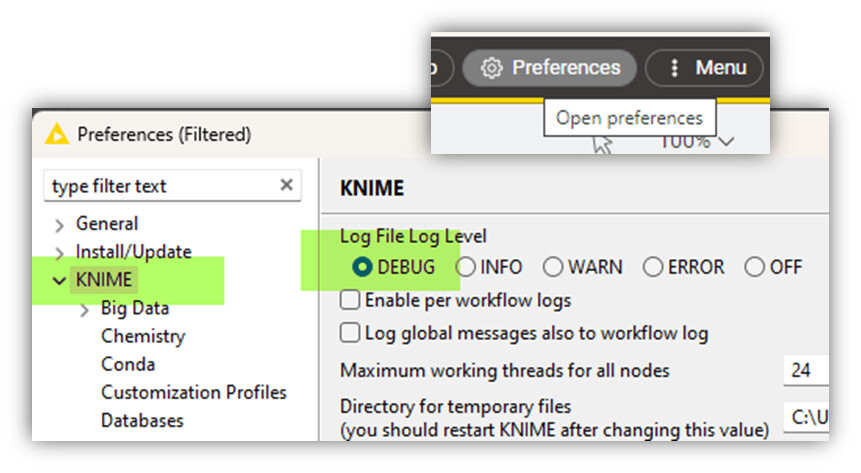
- find the location of the log file
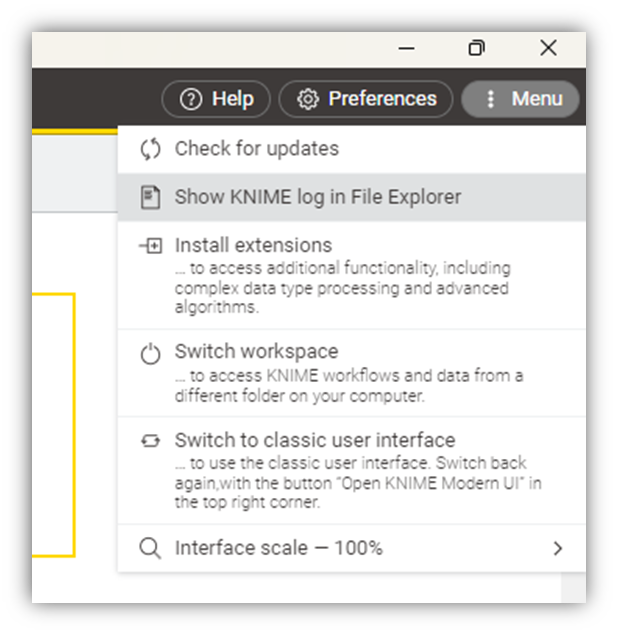
- Delete or rename the existing log (you might have to close KNIME first and store the path to find the log)
-
Restart KNIME and do the operation that causes the problem
-
find the Log again and zip it and send it to support or post it in the forum
-
Reset your log level to WARN (or whatever you prefer)
If you present code in the forum it would be great to have it in a readable format or as an attachment
Hi @cristianghlt,
the error message gives detailed hints of where to start investigating, did you follow them?
Best regards
Steffen
Thanks, I have no technical background but I will follow all your suggestions. Let me check.
Hello all again
Partial positive news. I made a fresh reinstallation of Knime and Python Extensions were installed without errors.
Next step for complete solution will be to run again the Python Script Node with the Bundle Configuration since I am using simple ‘pandas lib’ in my Python Script.
I’ll be back
Thanks
Hello
Here is the first failed test with Python Bundled Option. Attached you will find the documentation
Testing Python Script with Python Bundled Option.pdf (799.9 KB)
knime.log (1.0 MB)
Python Script.txt (1.6 KB)
I will the test the Conda option as well
Regards
@Xtian I suspect a problem with indexes. Maybe reset them at some point or ask ChatGPT for advice
Hello @mlauber71 . I tested this script in Jupyter Notebook and is working fine.
I will continue to check why is not running in Knime environment
Thanks
@Xtian in the past KNIME sometimes had problems with Python / Pandas indices when bringing them back from the Python world. So maybe you can rest the index right before bringing back the dataframe to KNIME.
Hi @Xtian,
Thank you for your detailed report! It appears that the issue is not related to the bundled environment.
The warning on the line “import pandas as pd” (in step (5) of your slides) indicates that pandas has been imported but not used. This warning should appear when hovering over the relevant line.
You’ve also uncovered a bug with our Python integration. When we pass data from the KNIME table to a Python script, we use custom Pandas extension arrays to prevent information loss in the columns. However, the current implementation of the extension array is missing the “_from_factorized” method, which is required when sorting a table by multiple keys. I’ve created a ticket (AP-23311) to address this issue.
In the meantime, you can work around this by converting the “Date” column to a native Pandas datetime array before sorting, as shown below:
# Convert the extension array to a native Pandas datetime array
df['Date'] = pd.to_datetime(df['Date'])
Thanks @bwilhelm !! It worked perfectly!
Thanks again!
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.