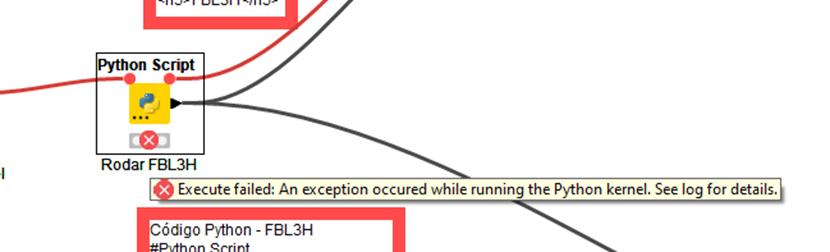
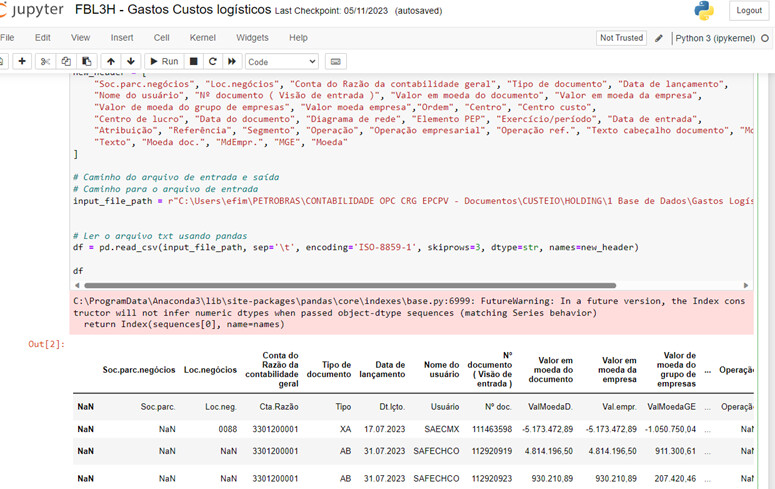
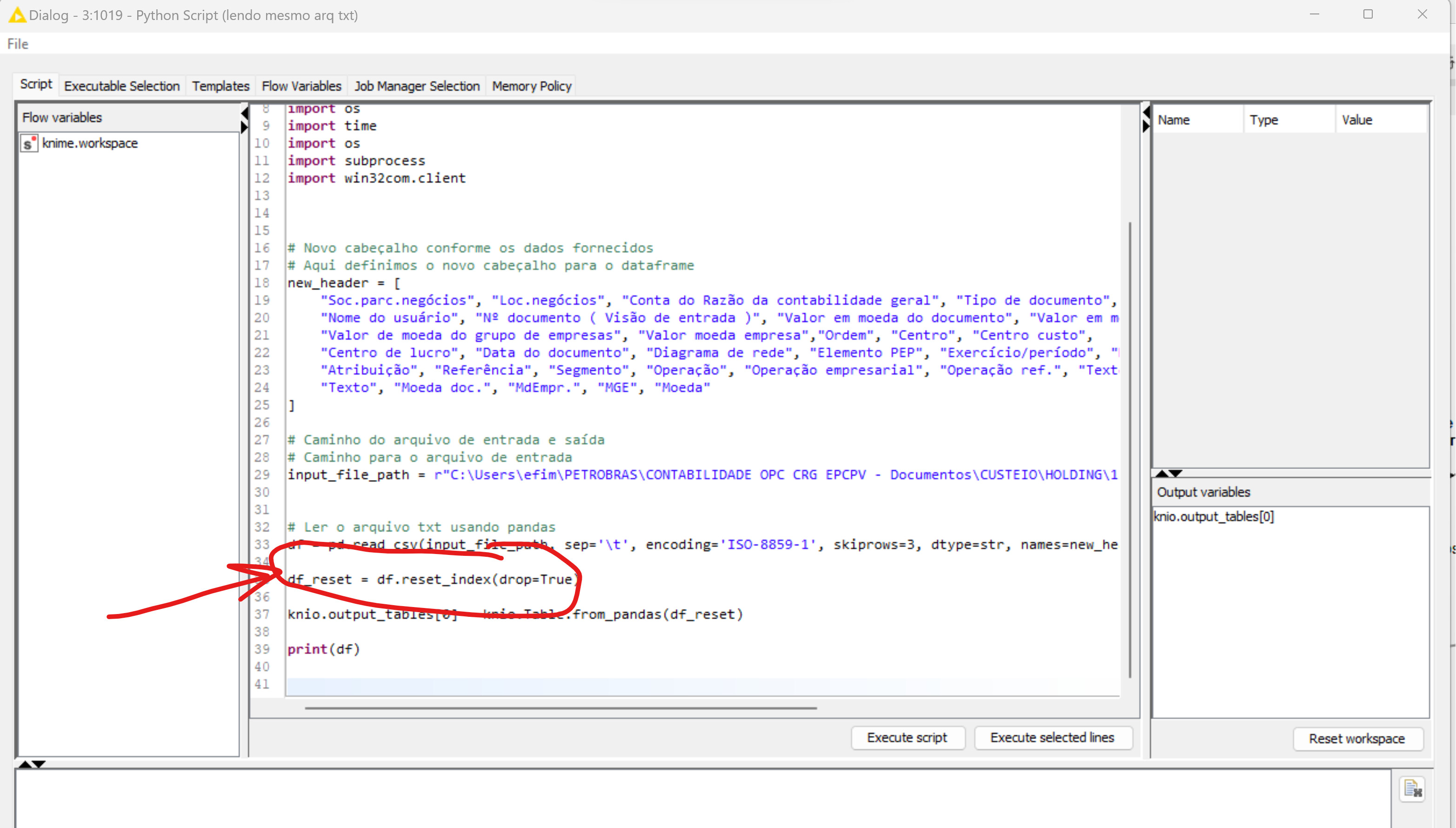
“I ran another code reading another file in KNIME and it worked fine. The file I am trying to read, I noticed that the first column is blank. So, I removed that column in the code. Even then, it continues to give an error.”
Did you look at the KNIME log? Otherwise I think the error should be shown if you click the Execute script button in the configuration window (see your second screenshot).
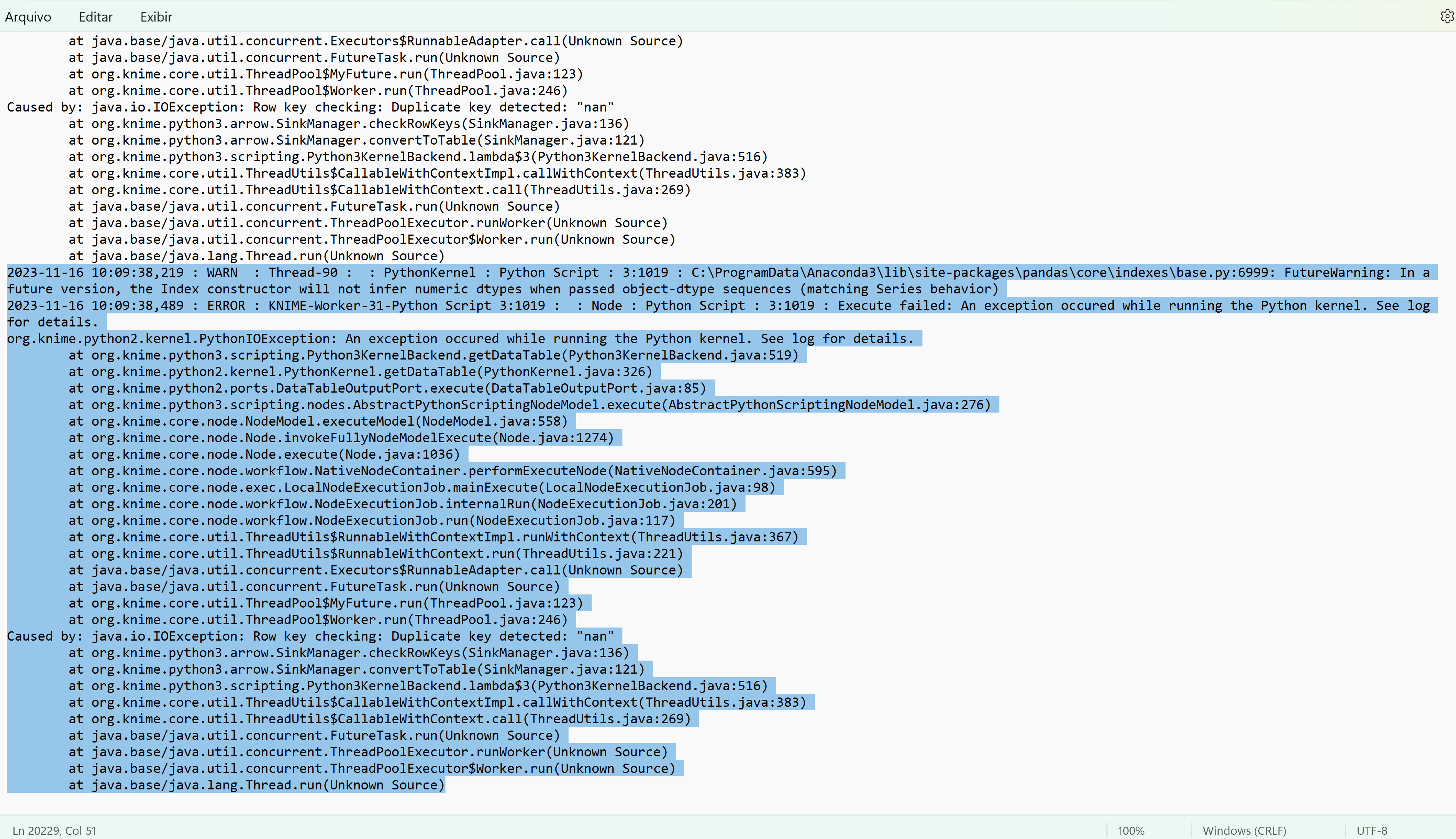
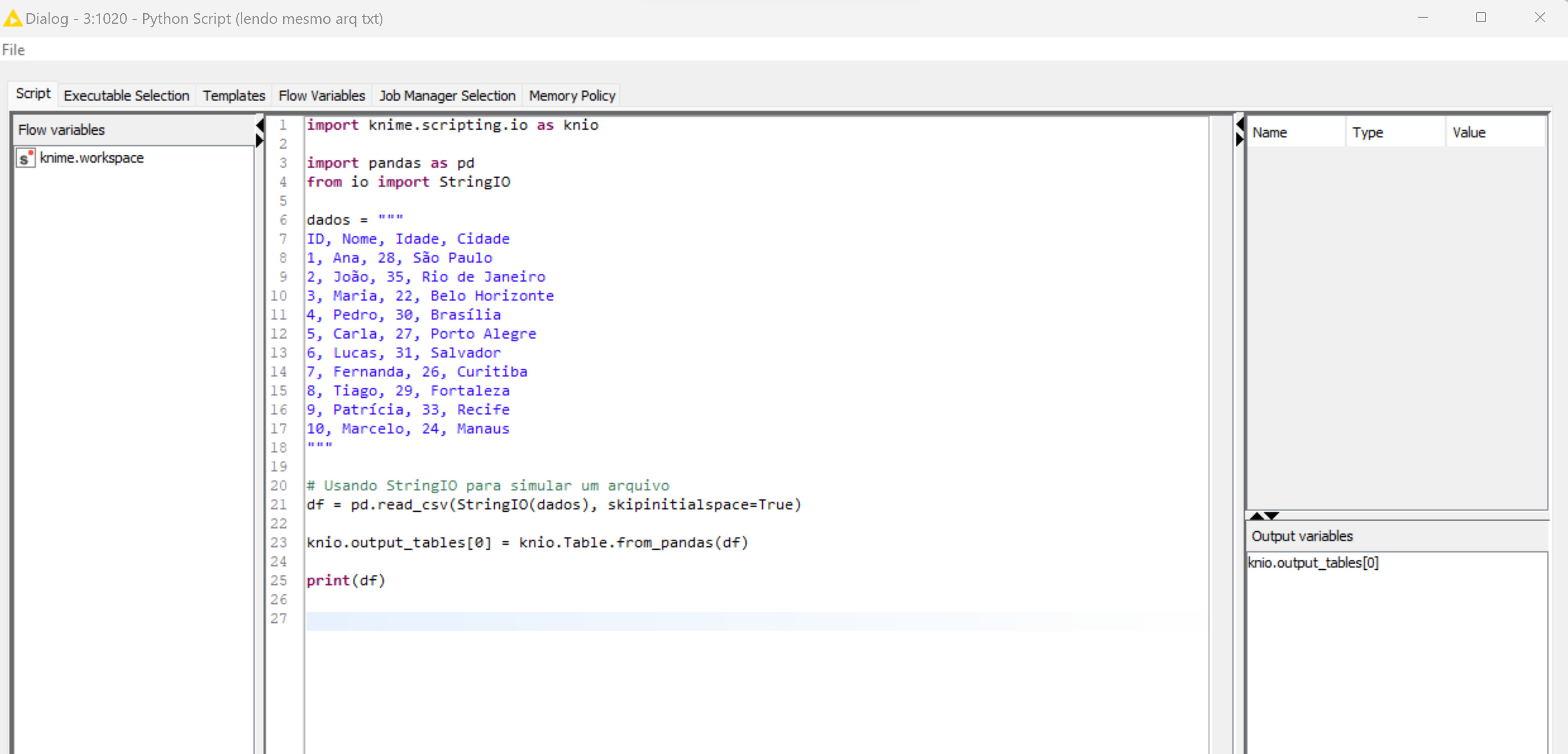
I created a separate node just with Python and it works fine without leaking data. I even used another txt and it also worked. If I try to generate a df to be read later, it’s giving this error:
As I said in my previous post, please provide the knime log (I sent a link in the previous post) and not the error log. Furthermore I asked, if you see anything in the scripting windows if you click Execute script. Please provide these details.
I conducted a test with a simple dataframe and it worked. The issue seems to be with the text file that I am reading. I noticed that the message mentions “nan”. I will perform a cleanup on that to see if it resolves the issue.
Your thought with nan is correct (and you spotted it correctly in the knime.log). I still don’t understand if you can see that same error also in the scripting window.
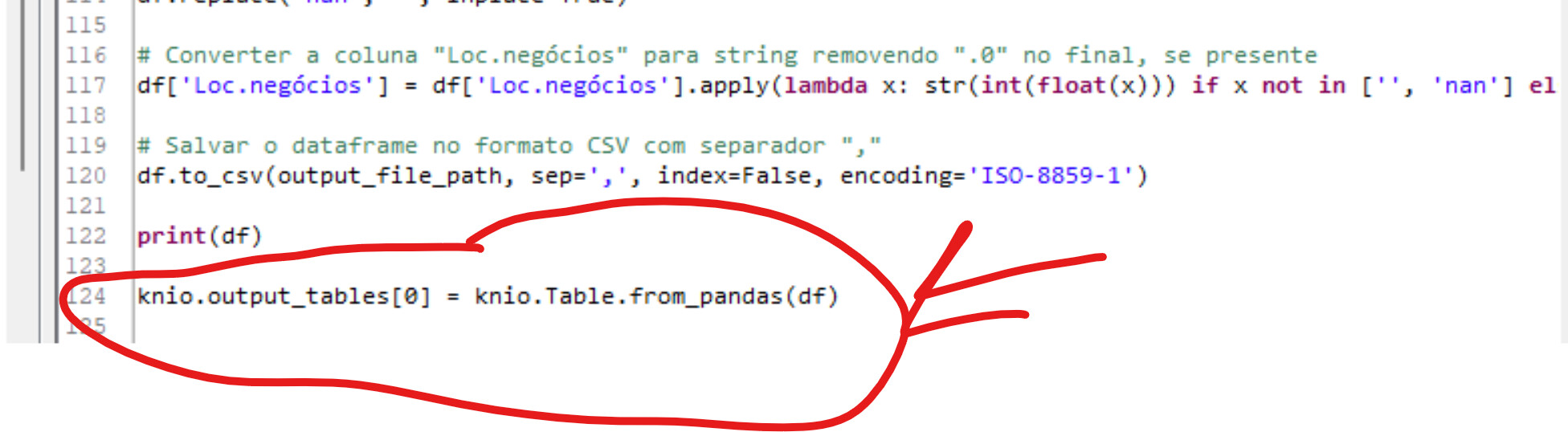
Your CSV file has as row ids always nan. KNIME does not allow that. You could either fix that in the CSV file already or have a look at the detailed documentation: Python Script API — KNIME Python API documentation
There you can see that we can override the given row ides when passing the DataFrame to KNIME. I think, the following could work: