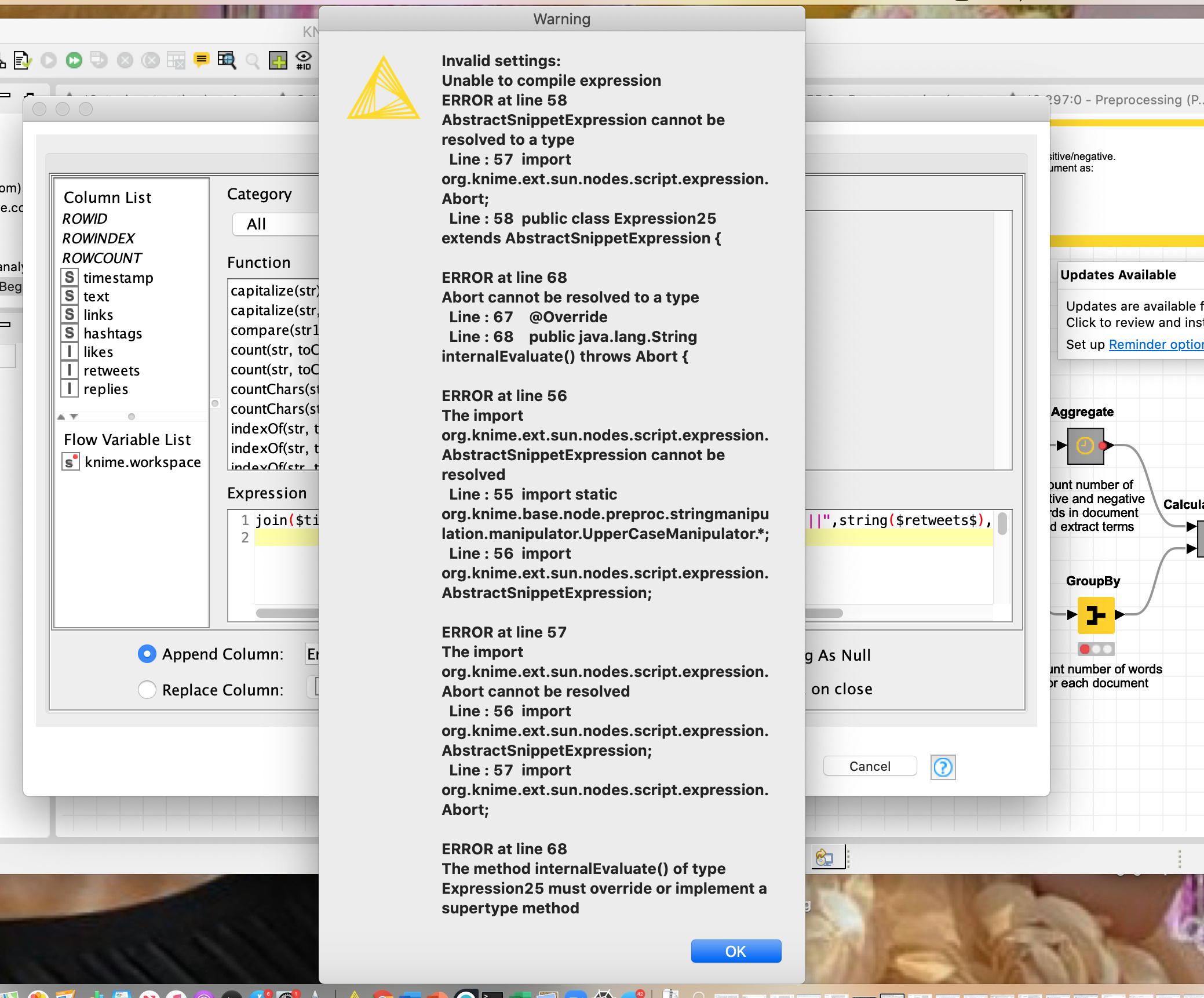
I am getting an error message in string manipulation node while running sentiment analysis. I attached the workflow I am using along with a sample data and would be glad if you can help me to figure out why I am getting this error.
When I run your workflow with the provided data, I don’t get any errors with the String Manipulation node. Can you provide what the error actually says?
Also, is it possible the error only occurs with the full dataset, and not the sample?
I am not sure if you see my reply yet but I would be glad if you can help me with this since I am still receiving an error and need your help. I also have one more question regarding the output I got from the sentiment analysis. As the original file, I have the text itself for the sentiment analysis. However, in the output, I only got the results of the sentiment analysis but the column for the text does not show any texts anymore. However, I want to be able to see the results along with the texts. How I can do that?
Sorry for the delay - I was on vacation and am just now getting completely caught up with forum items again.
I think it would be best if you can post the current version of your workflow. The screenshot above indicates some type of syntax error in the expression inside the String Manipulation node, but the error is blocking the expression itself so I’m not sure what the problem is.
As to your second question, again I would have to see your workflow. It’s possible that you just need to join your predictions back to the text by some type of common ID, but it’s hard to guess without more info.
Please post your latest workflow and data and I will take a look.
Attached is my current workflow with a sample data. Before you told me that when you tried it, you did not have any errors with the sample data but I also got errors with the sample data. I also contacted with Killian and he told me to try the joiner node instead of string manipulation. I also tried to do that but when after the preprocessing, BOWs, the row ID column disappeared so I cannot add the columns back since there was no Row ID column anymore. I would be glad if you can help me to figure this out. I need to have all the columns same they are when I get the output including the text columns.
the problem with this is, when I tried to see the preprocessed column, I could not. I want to use the excel writer node after the preprocessing process and see the preprocessed column. But in the document column, it only showed me the row ID’s. How can I see the preprocessed tweets?