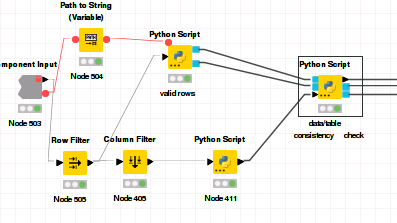
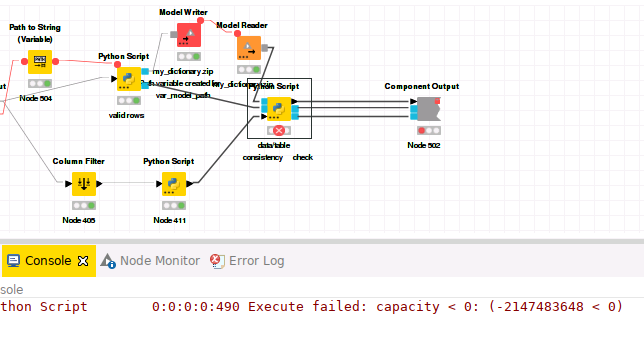
My workflow component reads in ECG data from files using a spefiic python library into a list of arrays. 1 file = 1 array.
Every node works perfectly as intended, as long as I don’t try to read more files than a certain breakpoint.
The valid rows Python script is the main reader, the consistency check is basicly irrelevant, identical outcomes with any python script with these inputs.
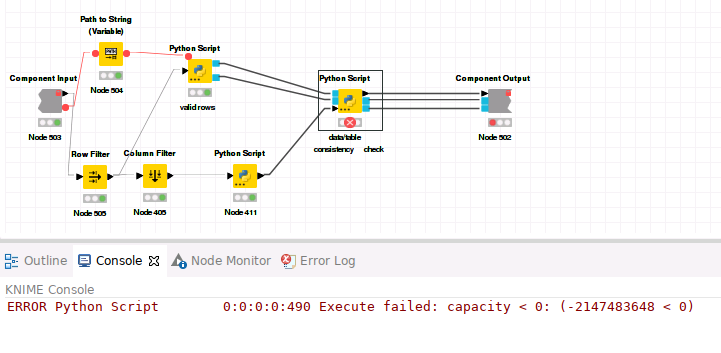
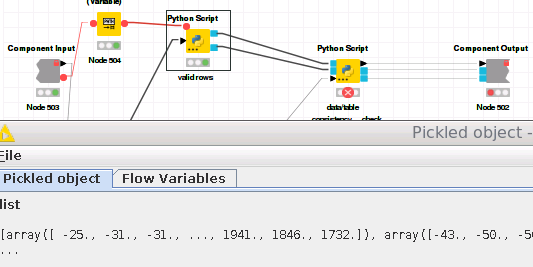
My problem appears after I read in too much data, make a pickled object from it and give it to another python script as input.
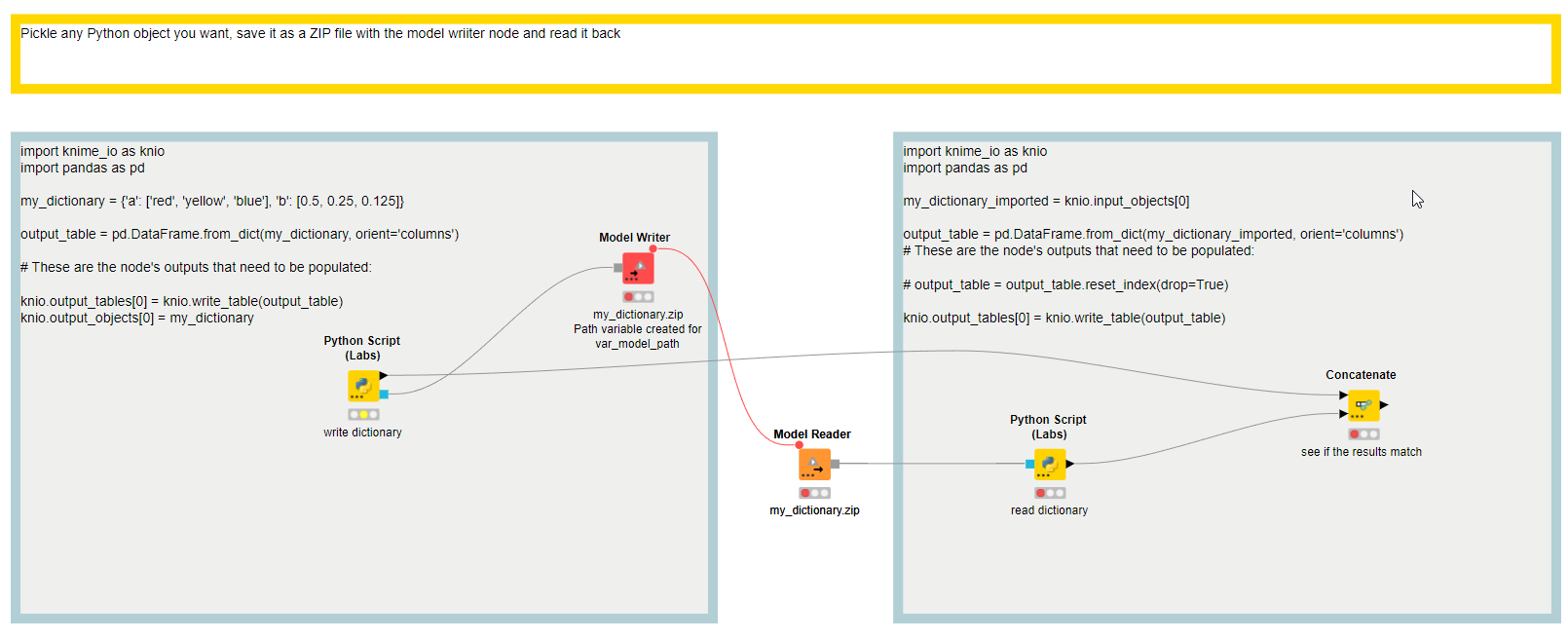
@botichello have you thought about saving the pickled object as a ZIP file and reading it back like in this example. Could you say how large this object then is?
If it is ‘just’ date (Pandas dataframe) you could try and save it as a Parquet file or use the new Columnar backend integration that should enhance the collaboration between KNIME and Python.
@mlauber71 Thanks for your answer!
The main problem with this approach is the way I want to process the data. I would like to keep the data in memory, and work with it in multiple different components afterwards.
I can only guess how much slower would it be to write it to a ZIP and read in every time there is a python script to python script connection.
In every file there are ~7 million float values (there are some way smallers aswell), and the breakpoint seems to be at the 18. file
For the context 7 million floats equals a 2 hours long record of ECG data.
@botichello maybe you give it a try. How large would the ZIP file be?
Can you save the data as a ‘standard’ Pandas Data frame? Then you might be able to benefit from the new Columnar storage integration mentioned that would speed up the transfer of data between KNIME and Python.
Then you could try and optimise your settings within the Python code. You could delete unnecessary items or you could try and run Garbage Collection from within the Python environment.
One last thing you could try is if the large individual job would run to put a conda environment propagation into the loop and reset the Python environment in every step in order to freiem memory. You would then have to have a loop in KNIME and restart the Python environment in every step.