Are you able to increase the memory to 10G and see if that helps with execution? Would you be able to send us the workflow you are running for us to test on our end as well?
Are you running this on the server or locally? If Server, what version of Server are you using?
If you decrease the number of cells being processed does the same issue occur? I’m trying to figure out if any workflow will run with less data to parse over.
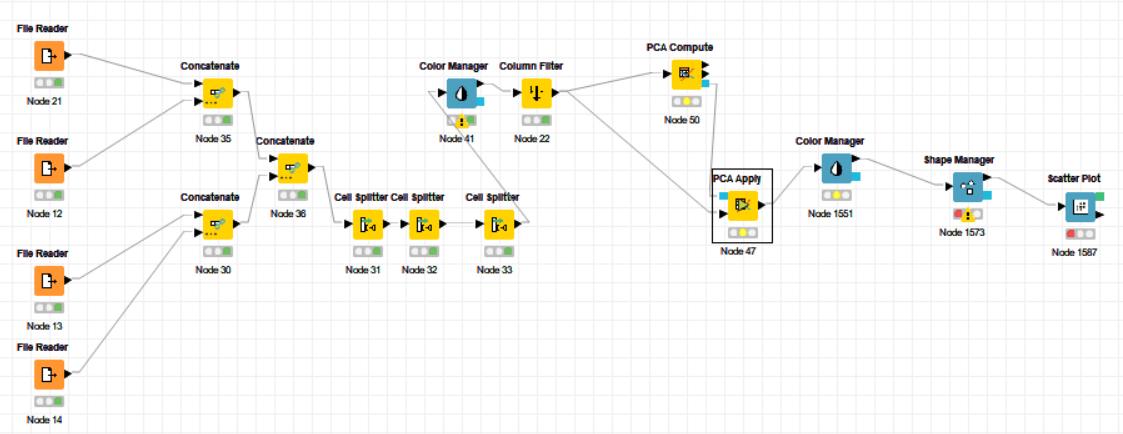
Do you have any other workflows that work using the combination of PCA Compute and PCA Apply, that you can test with?
Would you be able to attach the workflow as a file to this thread so we can test on our end as well? We should be able to generate fake data.
Have you tried splitting that into two workflows. Save the PCA model and the data and start a new workflow maybe with a garbage collector at the start (without any other workflows running).
Another idea could be to try the new columnar storage format.