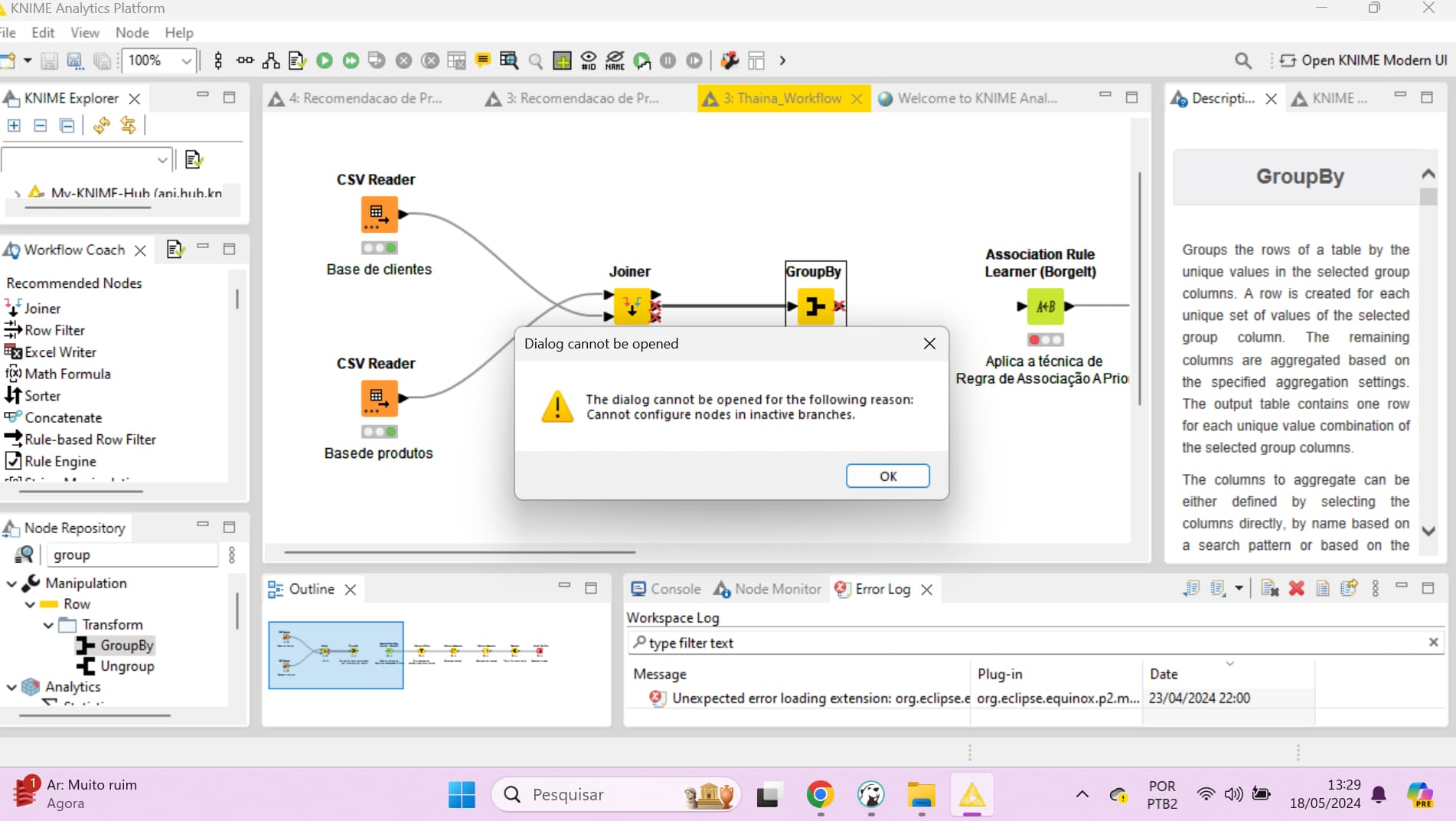
I need to resolve an issue with the GroupBy node. My workflow apparently seems correct, I read two databases and used the JOINER node which was well executed (everything is green). But when I try to configure the GROUPBY node, the error “The dialog cannot be opened for the following reason: Cannot configure nodes in inactive branches” appears. I tried to solve it using ChatGPT and Gemini. My Knime version is up to date.
Version of my Knime: 5.2.3;
I configured the CSV Reader node on both databases and ran it. I did the same in the JOINER node. Then I went to the GroupBy node, tried to configure it and couldn’t ;
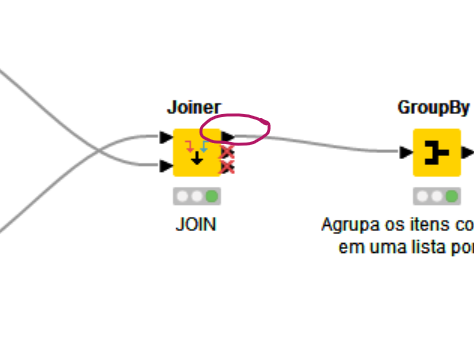
I am glad to see you were able to solve the issue. The first output of the joiner node contains the join results whereas the other 2 outputs have the left and right unmatched rows.
Hi @thaioliv, yes this is correct, but more specifically, in the default configuration for the Joiner node, only the top port is active.
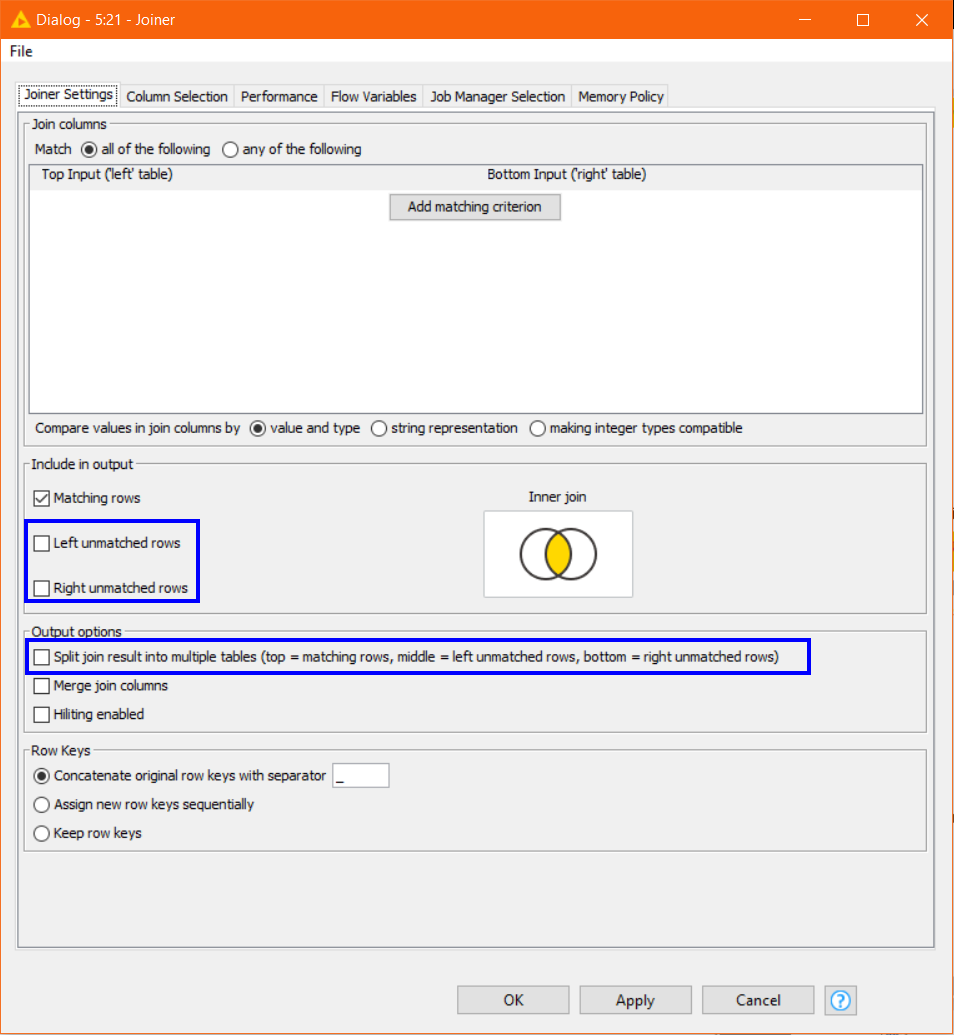
Additionally, as @k10shetty1 mentions, if you have not chosen to return Left unmatched rows or Right unmatched rows, then the only results on the upper port will be the matching join.
However, it should also be noted that in the default configuration ONLY the upper port is active regardless, of what you have selected to be included in the output, and all results (matching rows, left-unmatched and right-unmatched) will go to the upper port.
Only if the configuration is set to “split join result” does the the data get split between ports and then the lower two ports will be active, regardless of whether they contain data or not.