Hi all
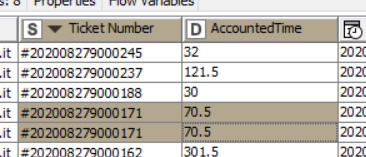
My table looks as follows.
I have to operate with the values in “AccountedTime” if there are duplicate values in TicketNumber.
Case 1: values are equal (as in picture) then delete one of the rows
Case 2: values are different then subtract values and return result. Result could be reaplaced in AccountedTime or written in new column.
Any suggestions?
Thanks in advance
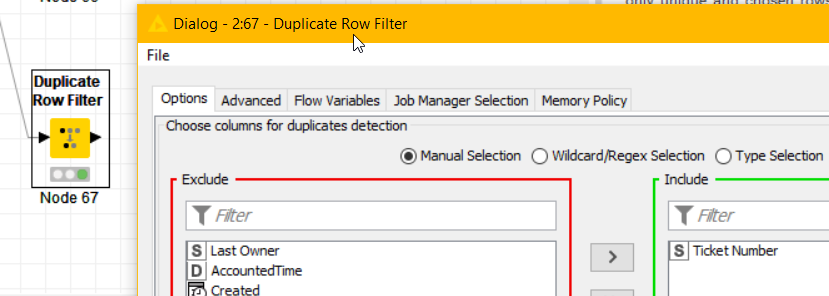
Don’t forget to choose “Keep duplicate rows” in the advanced tab.
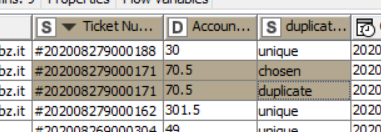
The result set is the original table with a separate column that tells you whether the row is unique or duplicate.
When applying it to ticket# and time you can identify duplicates on both fields (result 1)
Applying it only to ticket# and substracting result 1 will give you identical ticket#
Calculating the difference of two rows without any details about the sequence might be difficult as this operation is not commutative: V1 - v2 <> v2 - v1
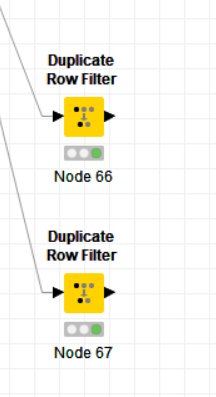
The first filter should be run run on both columns (ticket# and time). That will deliver you duplicate in ticket# and time. one line is the choosen one (first entry) the others are duplicates from this.
As you want to delete these entries you may apply the row filter on “duplicate” and exclude these rows.
The second filter should only be run on timestamp (select in tab options only the ticket# column). This will give all duplicates (including the ones you got with the first check).
Thanks for your kind reply. What you say is exactly what I had already done. From Node 66 and Node 67 I get two tables which essentially have the same data. The only difference is the rows with duplicate values if I exclude them as you say in Node 66 but I still don’t understand how to handle the comparison.