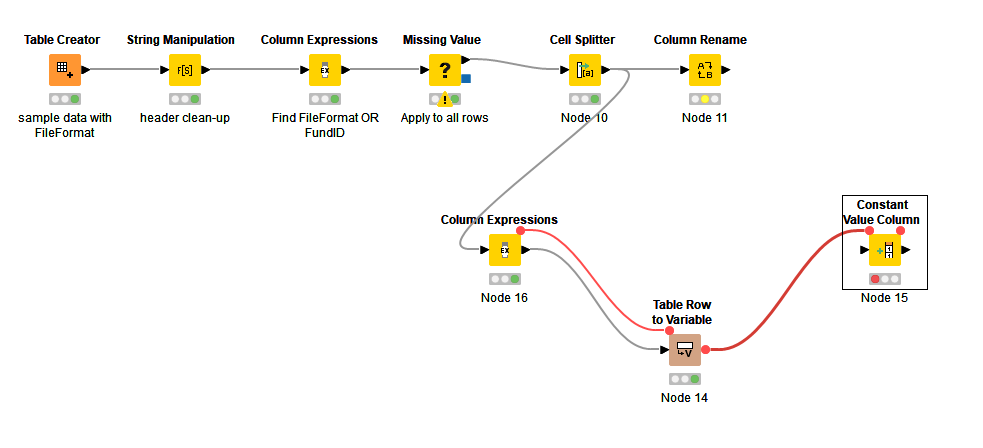
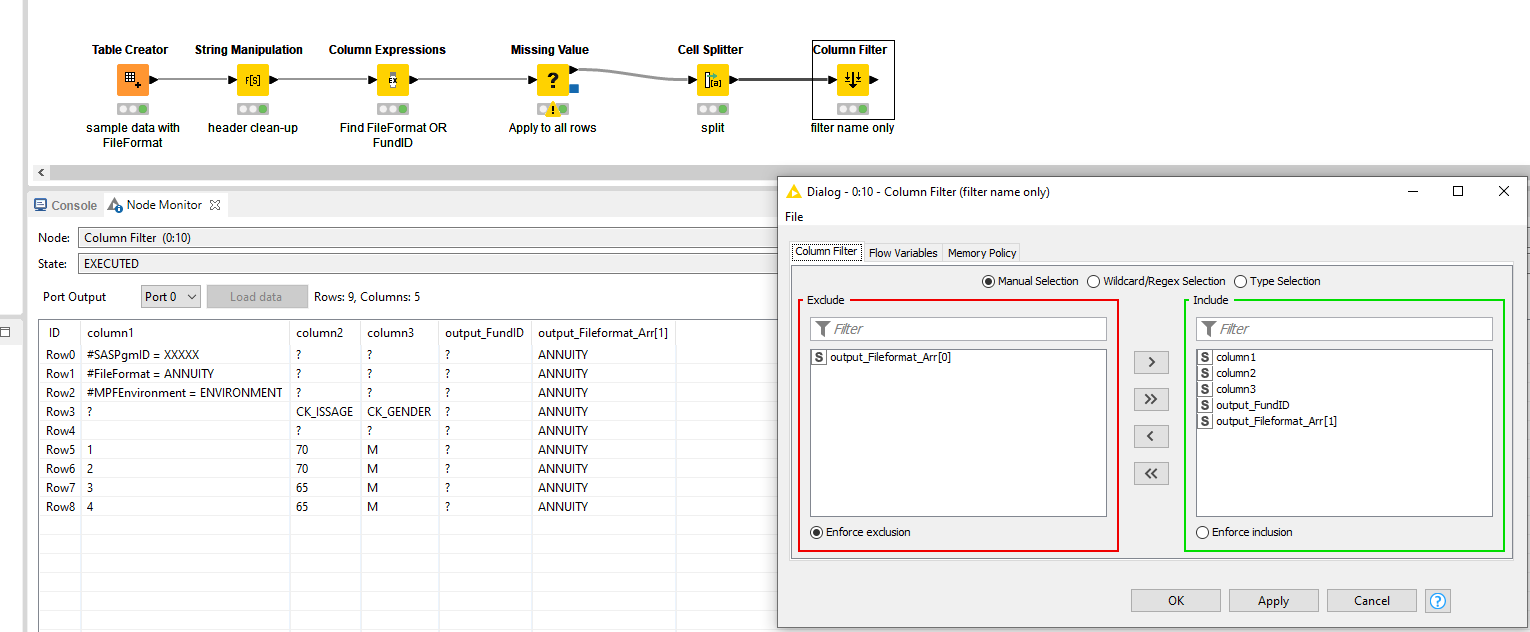
Hi @Pawel40Adi
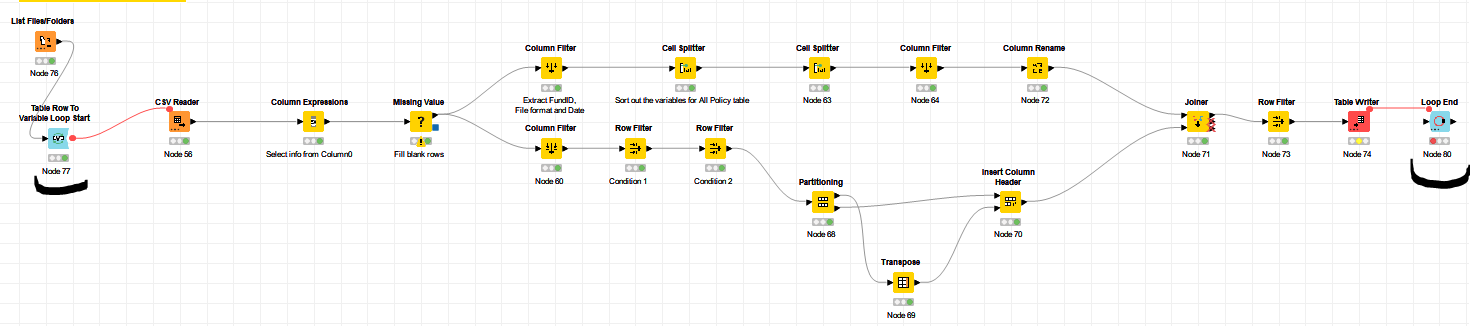
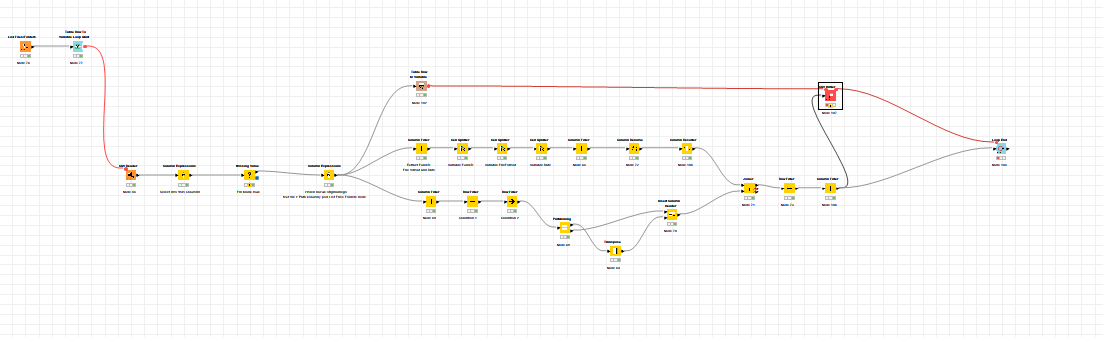
Creating files in a loop is a pretty commonly used topic in here  I created a reference workflow that gives you a few options to approach this.
I created a reference workflow that gives you a few options to approach this.
Starting point:
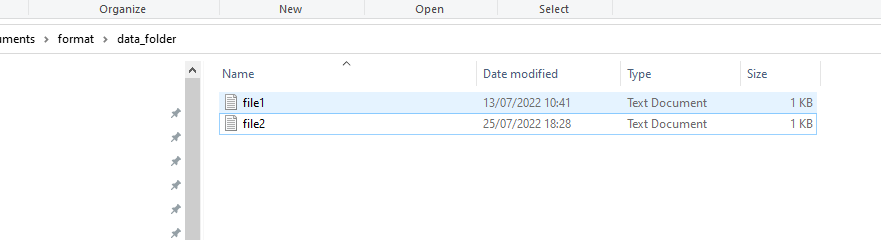
I have a folder with two files:
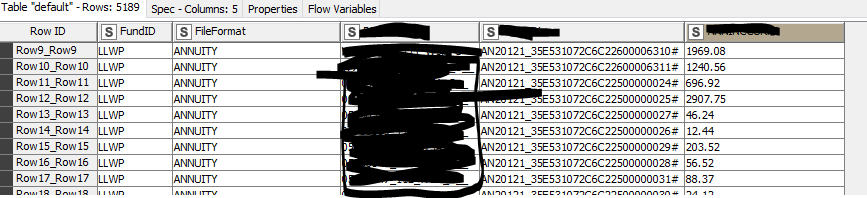
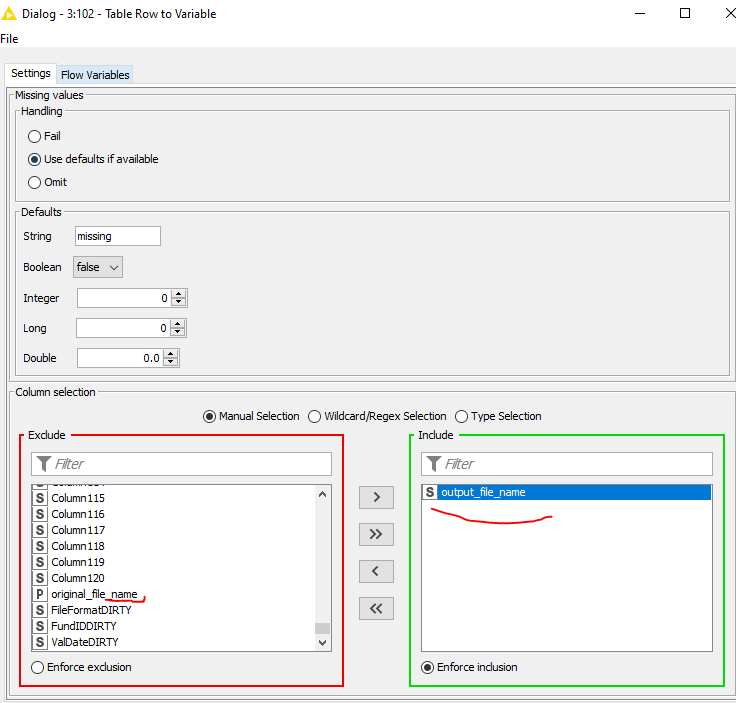
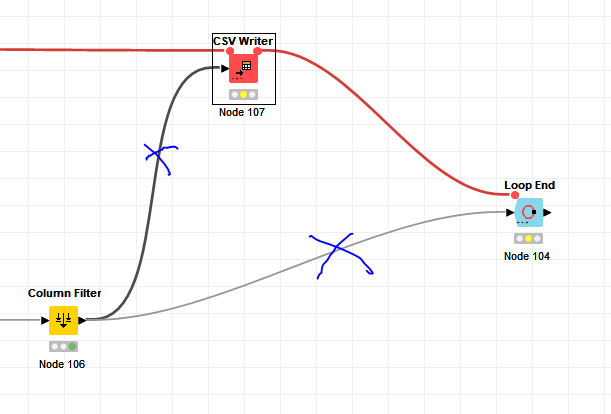
With the List Files/Folders node I get those into the workflow and initiate the Table Row To Variable Loop Start.
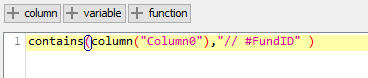
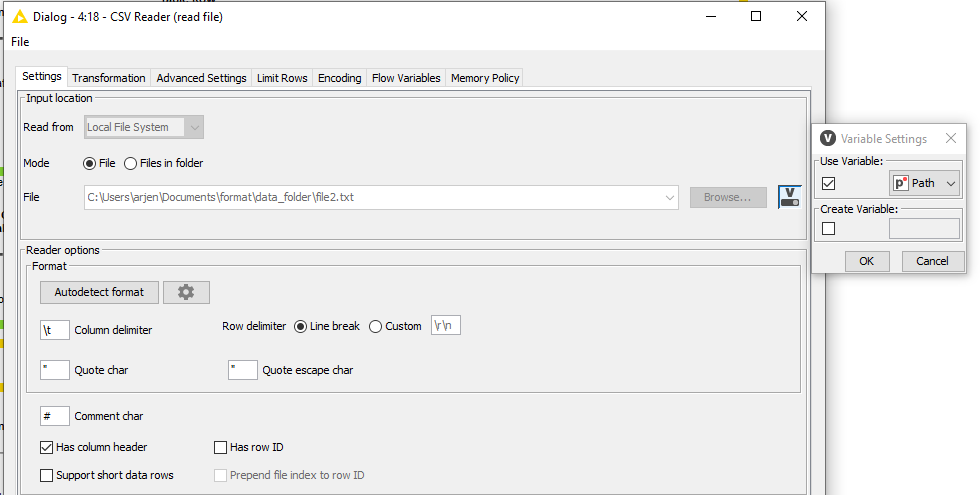
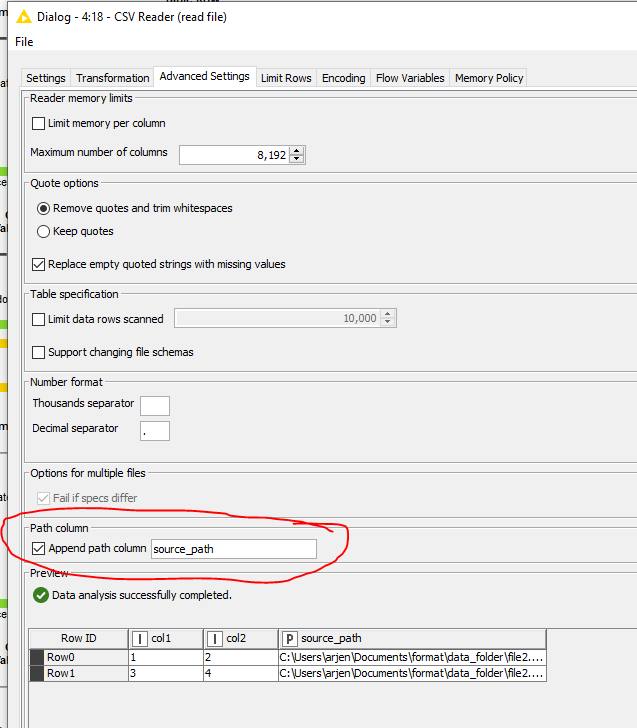
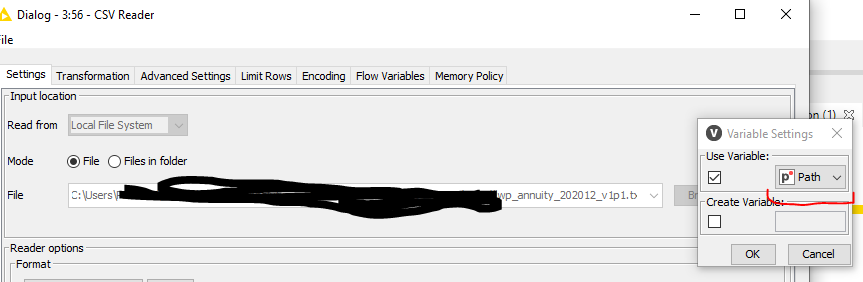
Next step is the CSV reader whereby the file is associated to the flow variable Path created earlier.
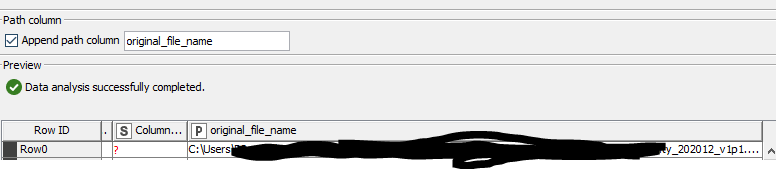
For convenience, I opt to include the path location also here so I can work with it later on as well.
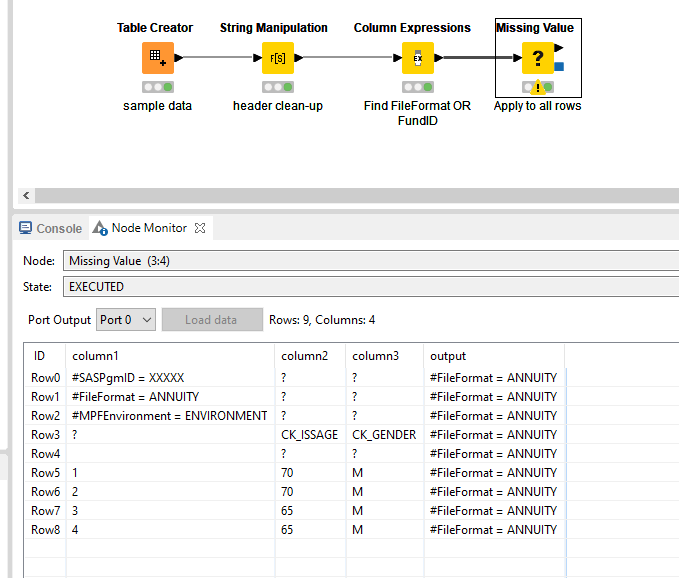
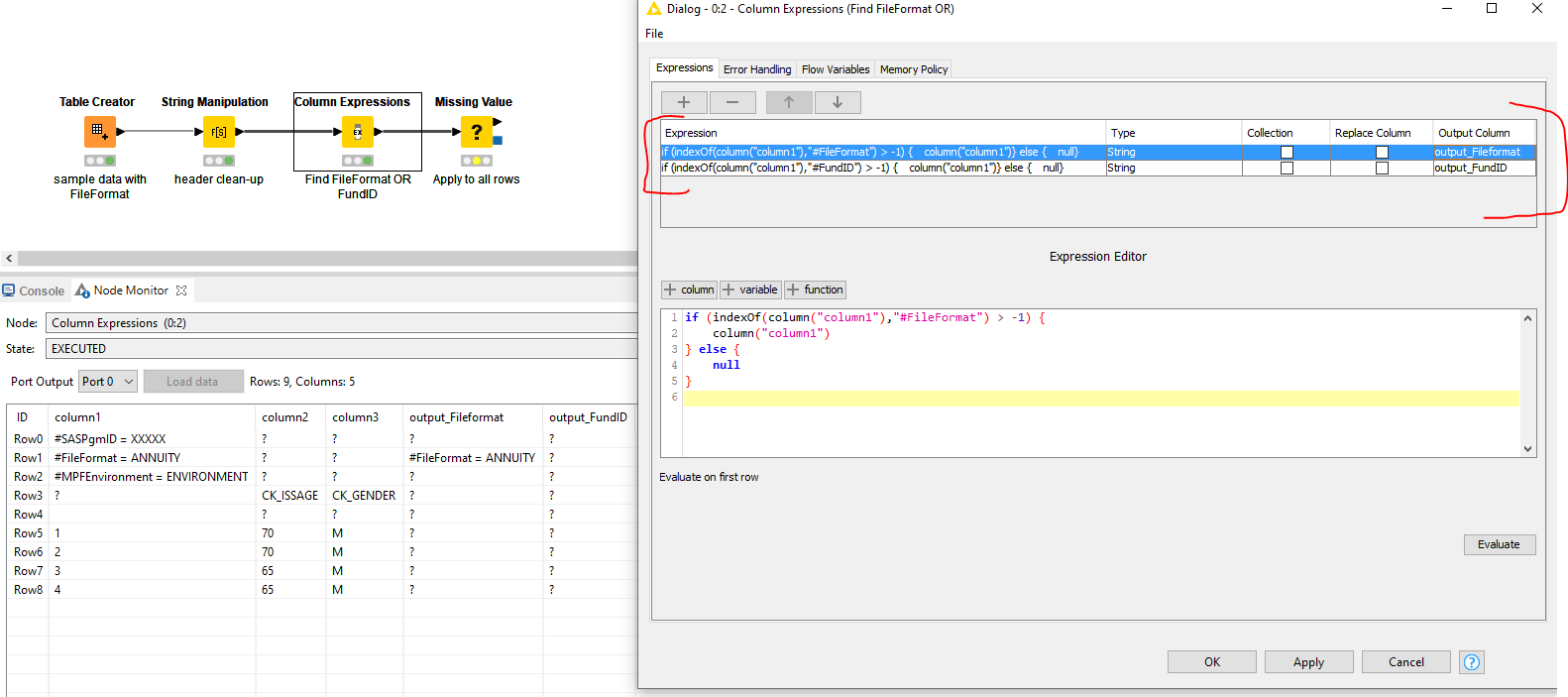
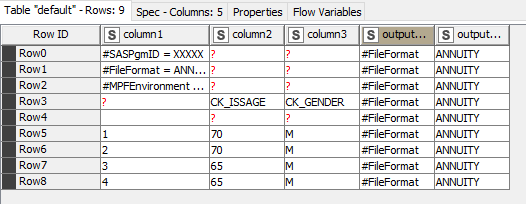
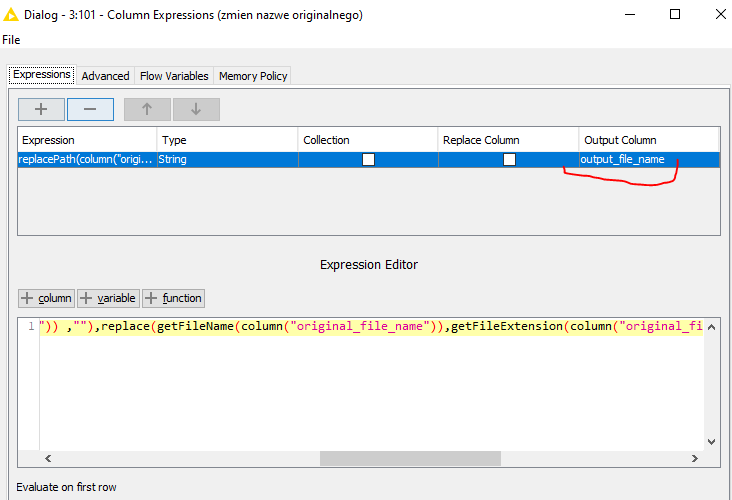
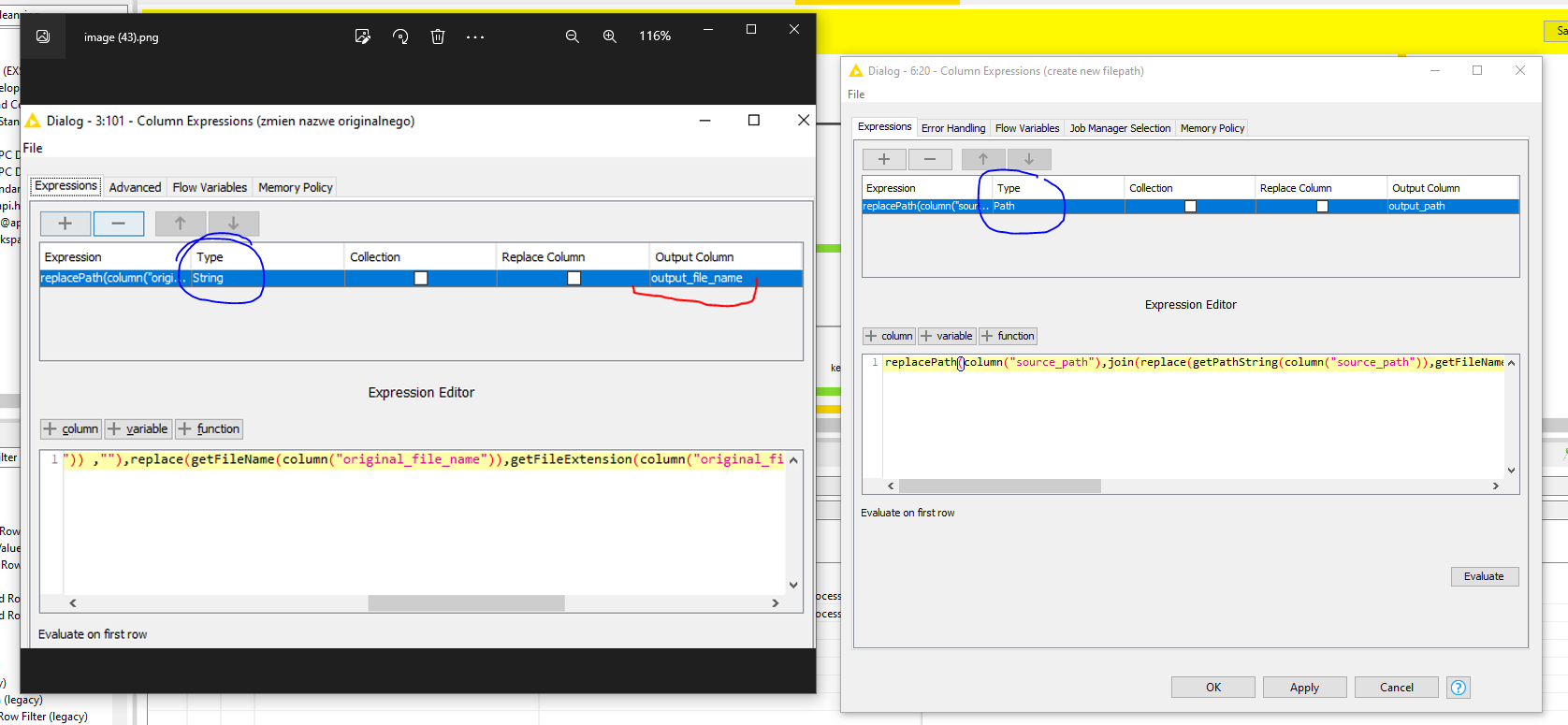
From here, you can take multiple directions. Option 1 could be to directly reconstruct the entire file and add a suffix to designate that it has been processed. In this example, I used _processed_option1. Using a Column Expression node, the new file path now includes the mentioned suffix.
Using the source_path created earlier:
replacePath(column("source_path"),join(replace(getPathString(column("source_path")),getFileName(column("source_path")) ,""),replace(getFileName(column("source_path")),getFileExtension(column("source_path")),""),"_processed_option1",getFileExtension(column("source_path"))) )
See the difference:
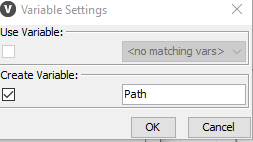
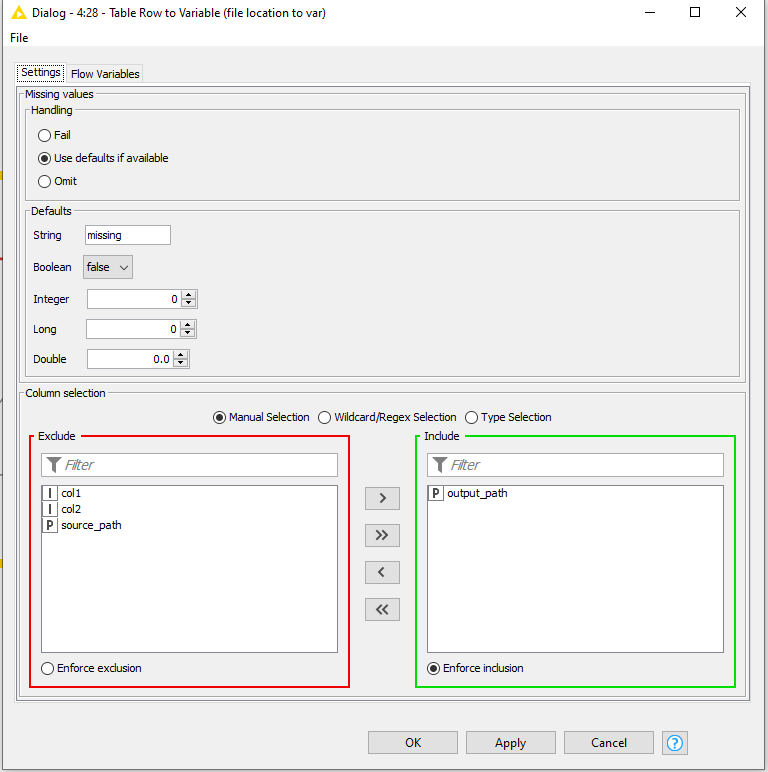
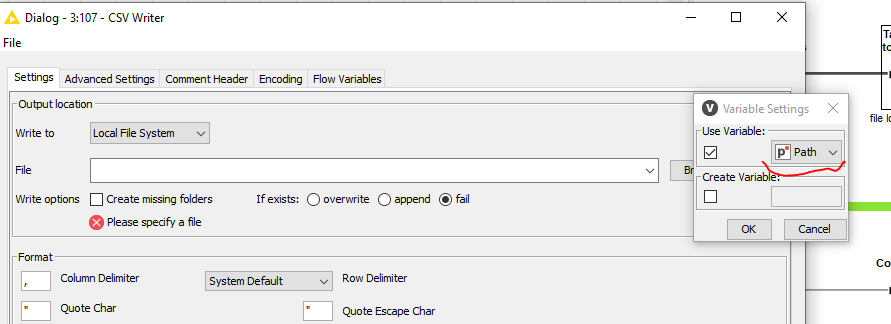
Convert the new output filepath to variable with Table Row to Variable
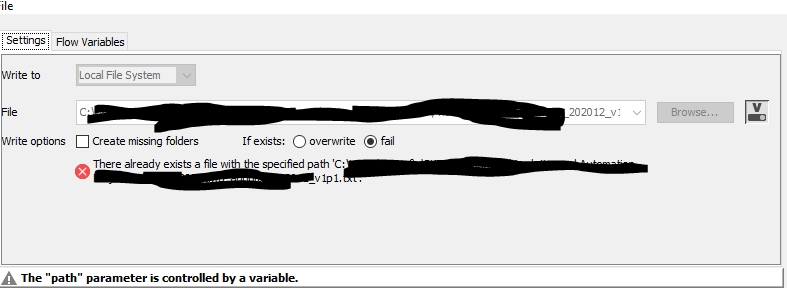
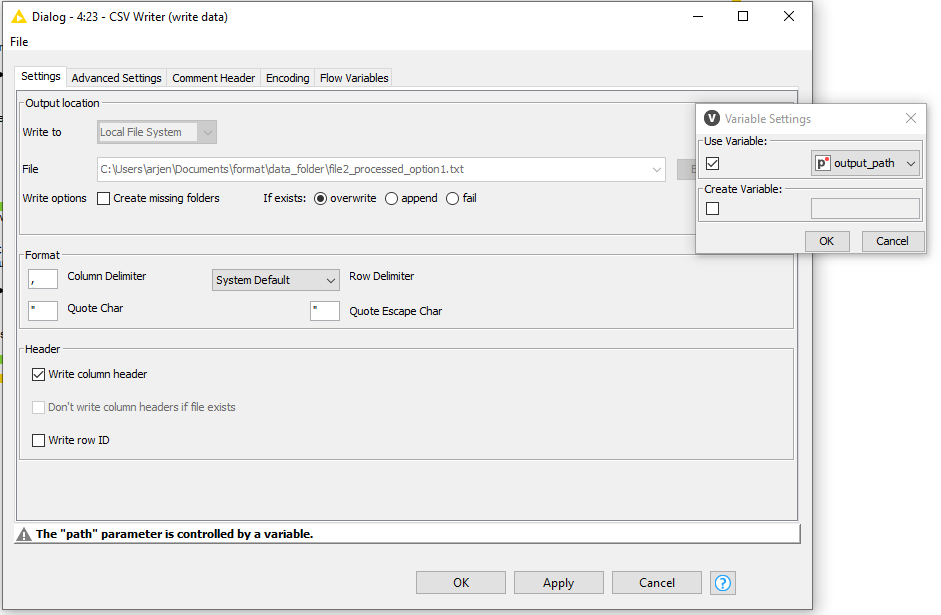
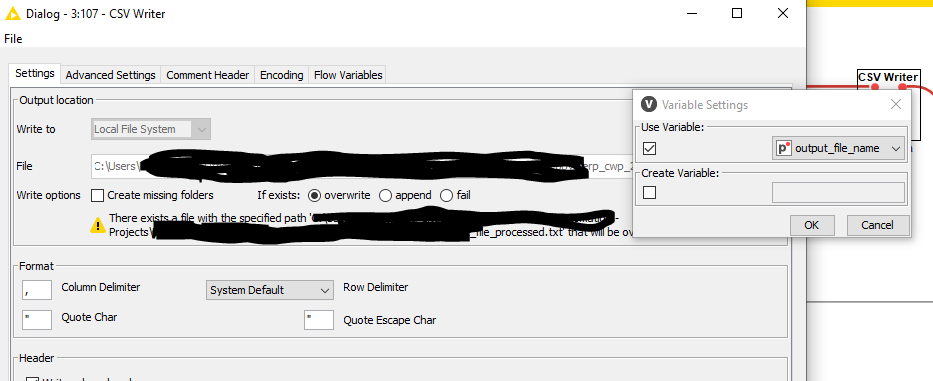
Pass this variable to the CSV writer subsequently:
// // // // //
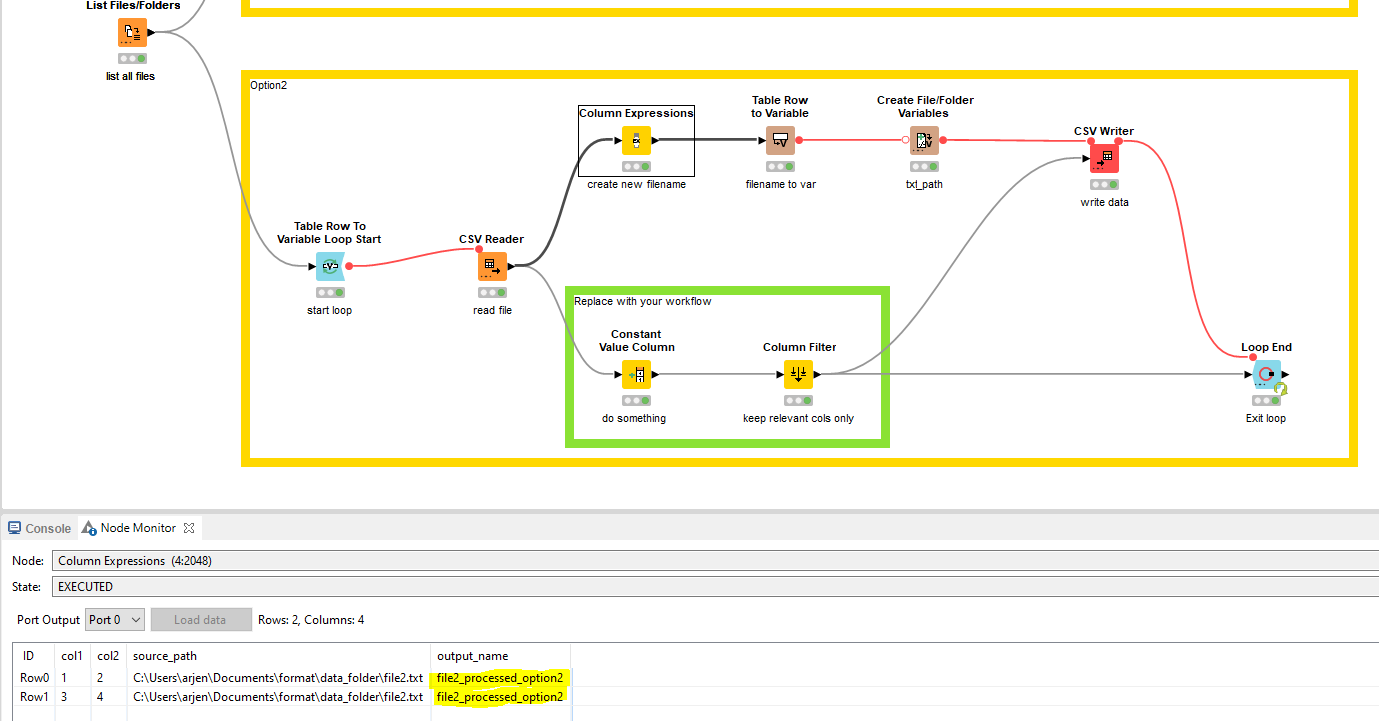
Option2
If Path operations are not really your thing, you can simplify it slightly by just creating the new filename first with: join(replace(getFileName(column("source_path")),getFileExtension(column("source_path")),""),"_processed_option2")
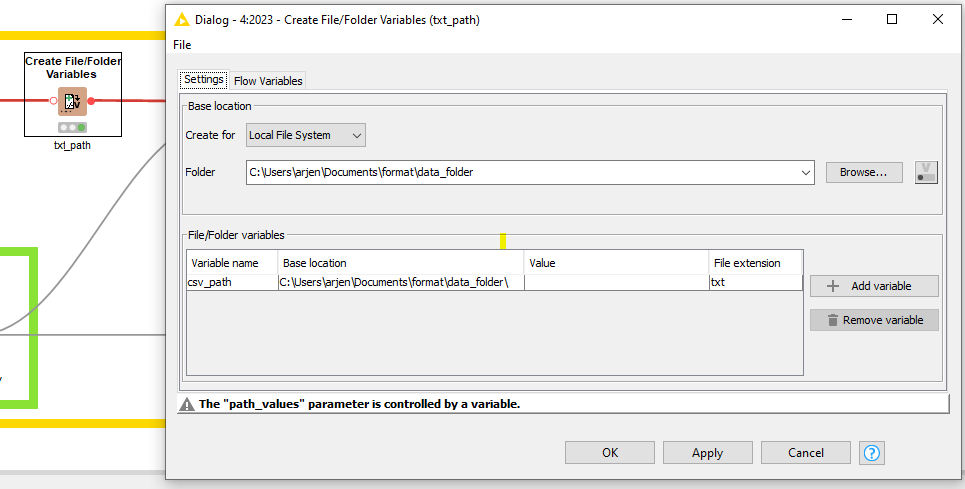
Repeat the step of converting it to a flow variable. The next step is the Create File/Folder Variables node which allows to create path flow variables. Fill in your base folder location, the desired new variable name, value and file extension.
The value is the new actual filename that I created before. As such, replace this Value field with the flow variable created in the previous step.
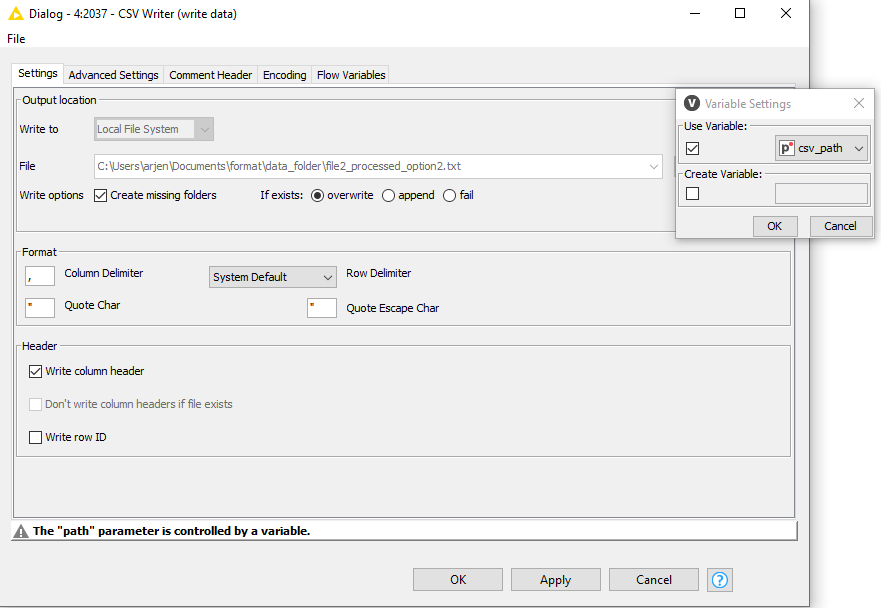
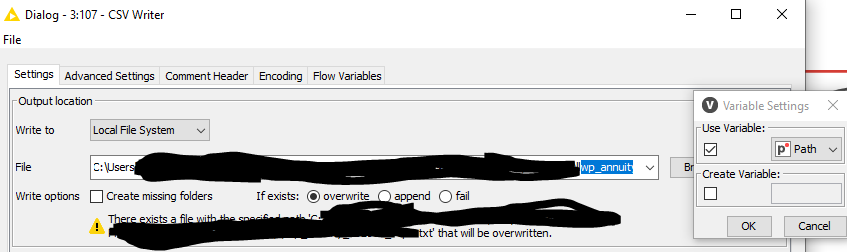
Finally, pass the csv_path variable to the CSV writer.
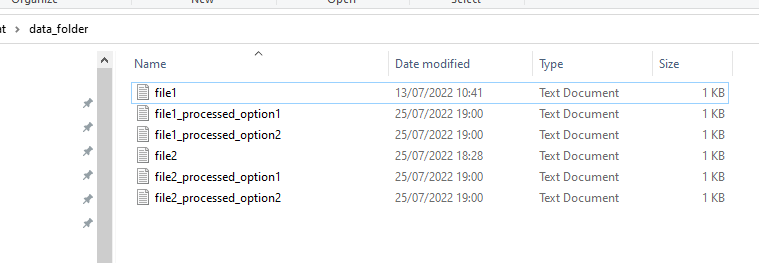
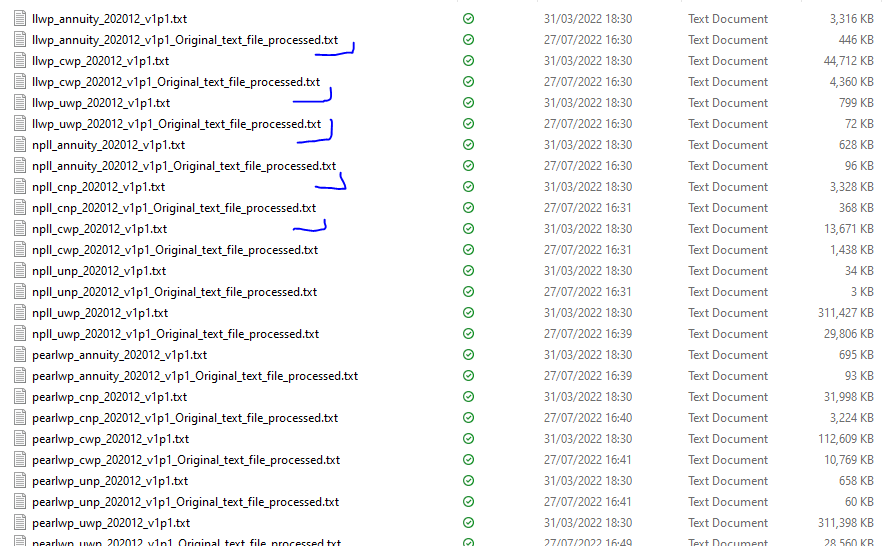
Run the entire workflow. Result:
See WF:
Text file iteration.knwf (80.5 KB)
Note1: as mentioned, there are many ways to do this more which others can most likely highlight. Test for yourself which is the most efficient with your data set! Have look around in the forum and the hub for more inspiration.
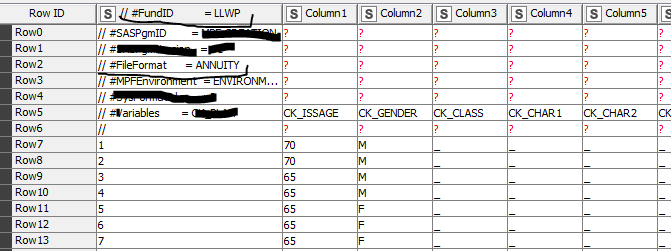
Note2: If your workflow still does not work after applying something like this: replace your actual input with a Table Creator with dummy data like I have done in the beginning and upload your workflow here to proper troubleshooting can be done.
Hope this helps!