thanks for your answer, but why convert we first have to convert the documents to “bag of words” to then use the “term to string” not?
And is the whole process of term filtering the same like the keygraph keyword extraction? what is the difference between them?
Another question: do you think that is is better to use the lemmatizer before using the other preprocessing steps?
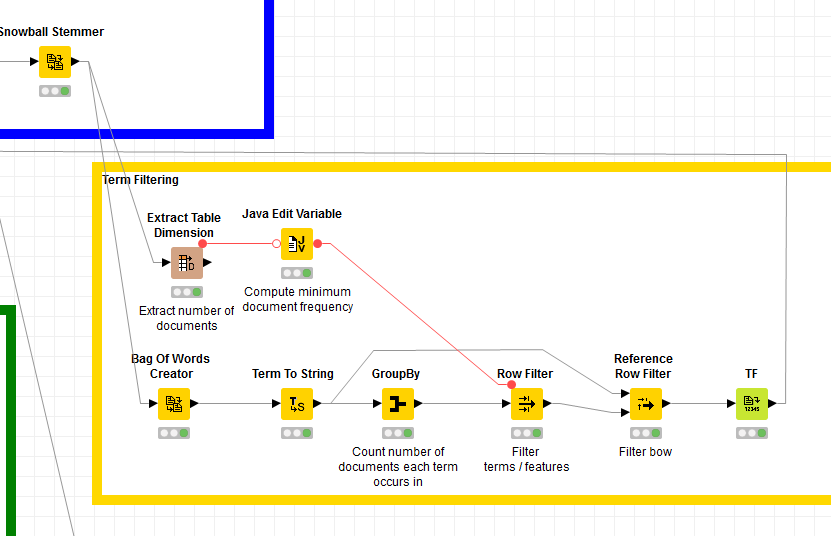
on a bow you can perform a group by to group by terms and count the docs. Grouping on terms directly is also possible but this will take the assigned tags into account as well. Maybe you have equal words but different tags resulting in different groups. This is why we converted terms to strings to get rid of the tags. However, of course you can also group directly on terms.
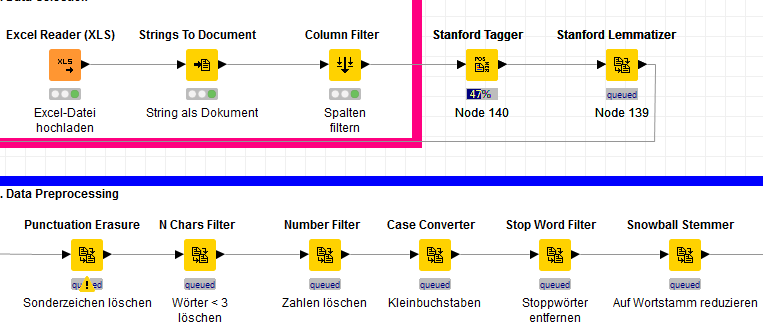
Using the lemmatizer directly after POS tagging makes sense since it relies on tagged documents.
thanks, but do you think it makes also sense to use the lemmatizer before using the stemmer or the other preprocessing steps like puntuation erasure etc.?
Is term filtering a part of preprocessing or transformation?
Using the Lemmatizer and the Stemmer make not much sense. But using the Lemmatizer before the Filtering etc. is useful. Filtering is part of preprocessing.
Thank you so much Kilian Then i will try it with both and compare the results with each other…maybe the results will change when i use lemmatizer instead of stemming.
 Canan
Canan