I am doing sentiment analysis and my goal is after the analysis to conduct regression analysis using sentiment score as a predictor based on the number of retweets and likes. When I uploaded the excel file at the beginning of the analysis, it includes all columns : text, number of likes, number of retweets etc. However, after the sentiment analysis, when I export the results as an excel file, I am missing the columns for number of likes and retweets and after the analysis the number of rows are not the same so I cannot match the rows from the two different files. I attached my workflow and it would be great if you can help me with that. I want to have all columns after the sentiment analysis in order to proceed with my regression analysis.
Can you upload a sample of your tweet data, so I can try to see where things might be going wrong? As it is, I can’t tell solely by looking at the workflow.
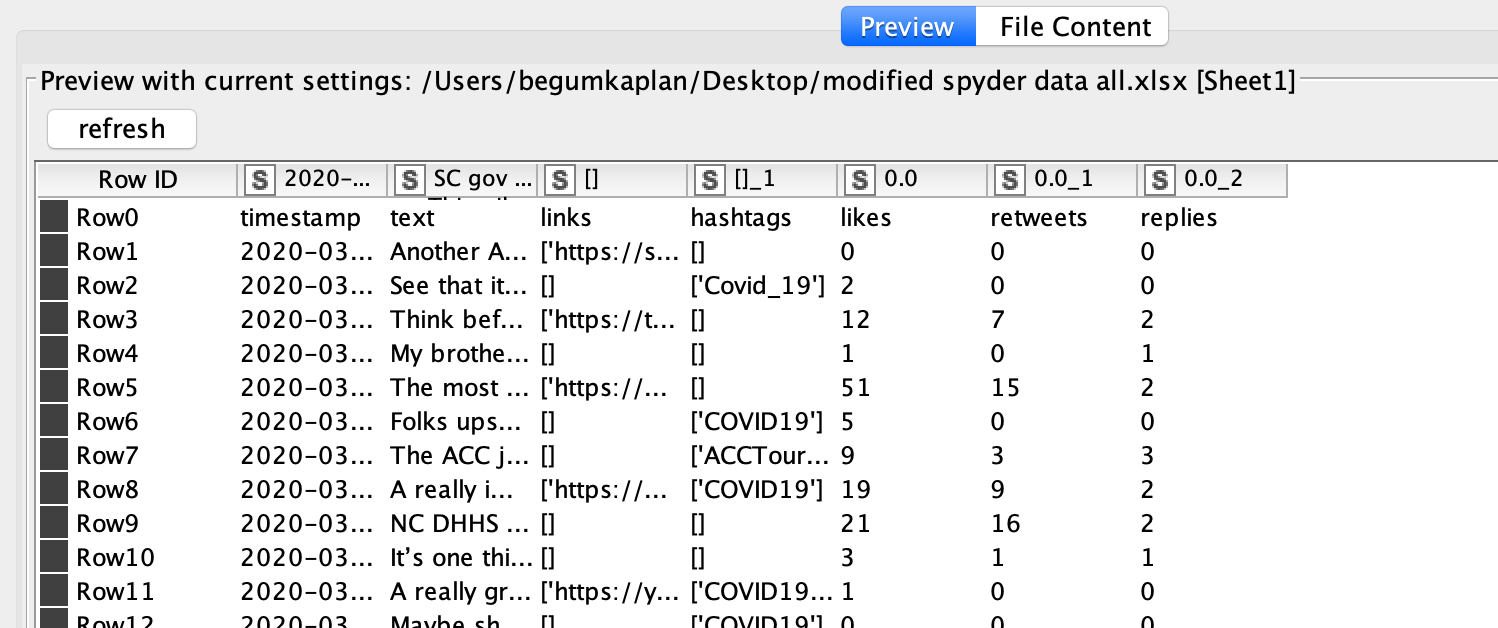
It wasn’t clear to me why the number of rows was coming back differently - this was happening in the Pivoting node inside the Aggregation metanode - but I decided to sidestep that altogether. I did this by encoding the other tweet information into the Source field of the document, then extracting that information later - so you don’t have to worry about joining back with the original data at all.
Here’s a tweaked version of your workflow, with my new bits highighted in red annotation boxes. What I did:
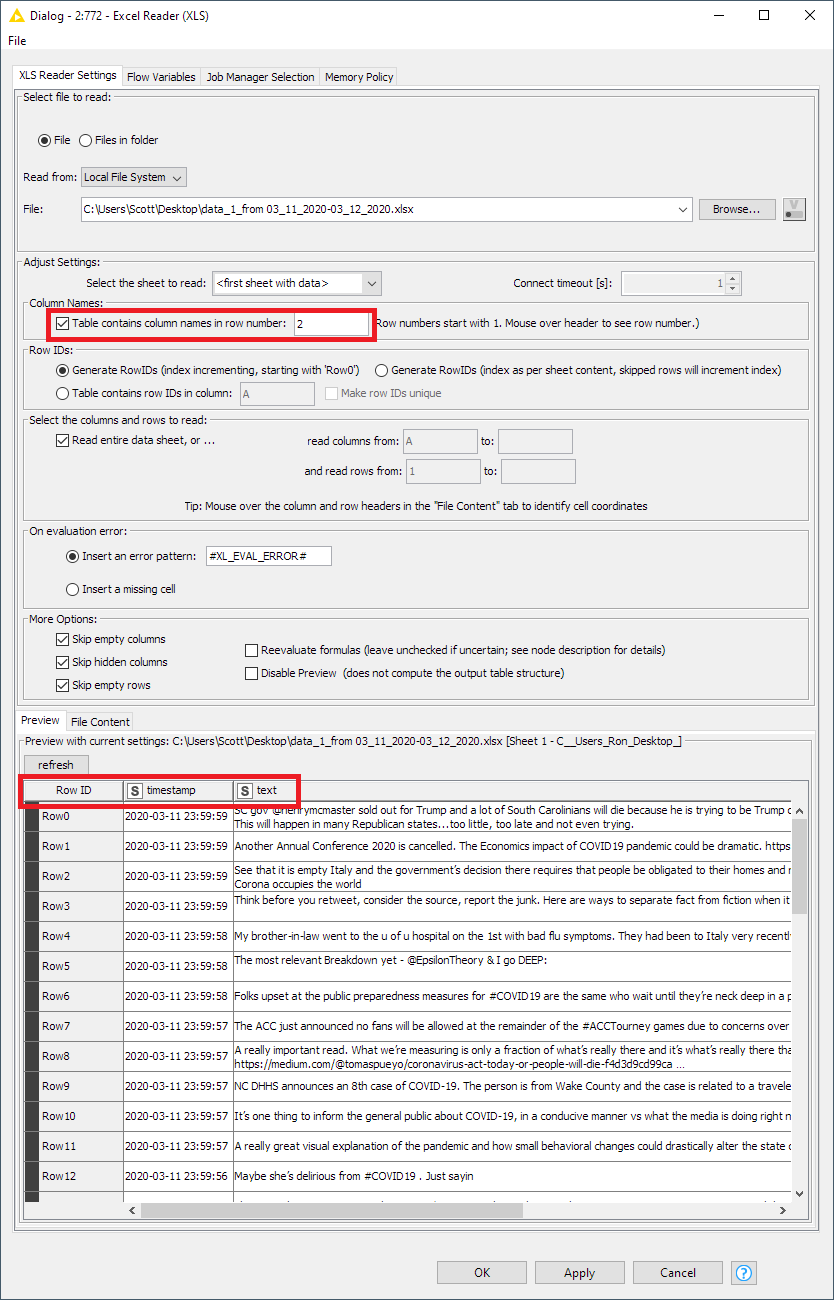
Fixed the Excel reader to read in the actual column names (instead of Col0, Col1, etc).
In a String Manipulation node, joined several different fields into a single field called EncodedMeta, separated by double pipes (||)
In the Strings to Document node, changed the title of each document to empty string, to avoid including content twice. Also set the Source of each document to the new EncodedMeta.
Later on, used a Document Data Extractor node to pull the EncodedMeta info back out again.
Then, used a Cell Splitter and Column Rename nodes (based on the || character) to reconstruct the twitter date, likes, etc.
This is a bit hacky, but I prefer to do it this way rather than rejoining using uncertain index fields. On larger datasets, joining is a resource intensive operation anyway. And maybe it helps educate you on some new nodes too
Hope this helps - let me know if you have any questions.
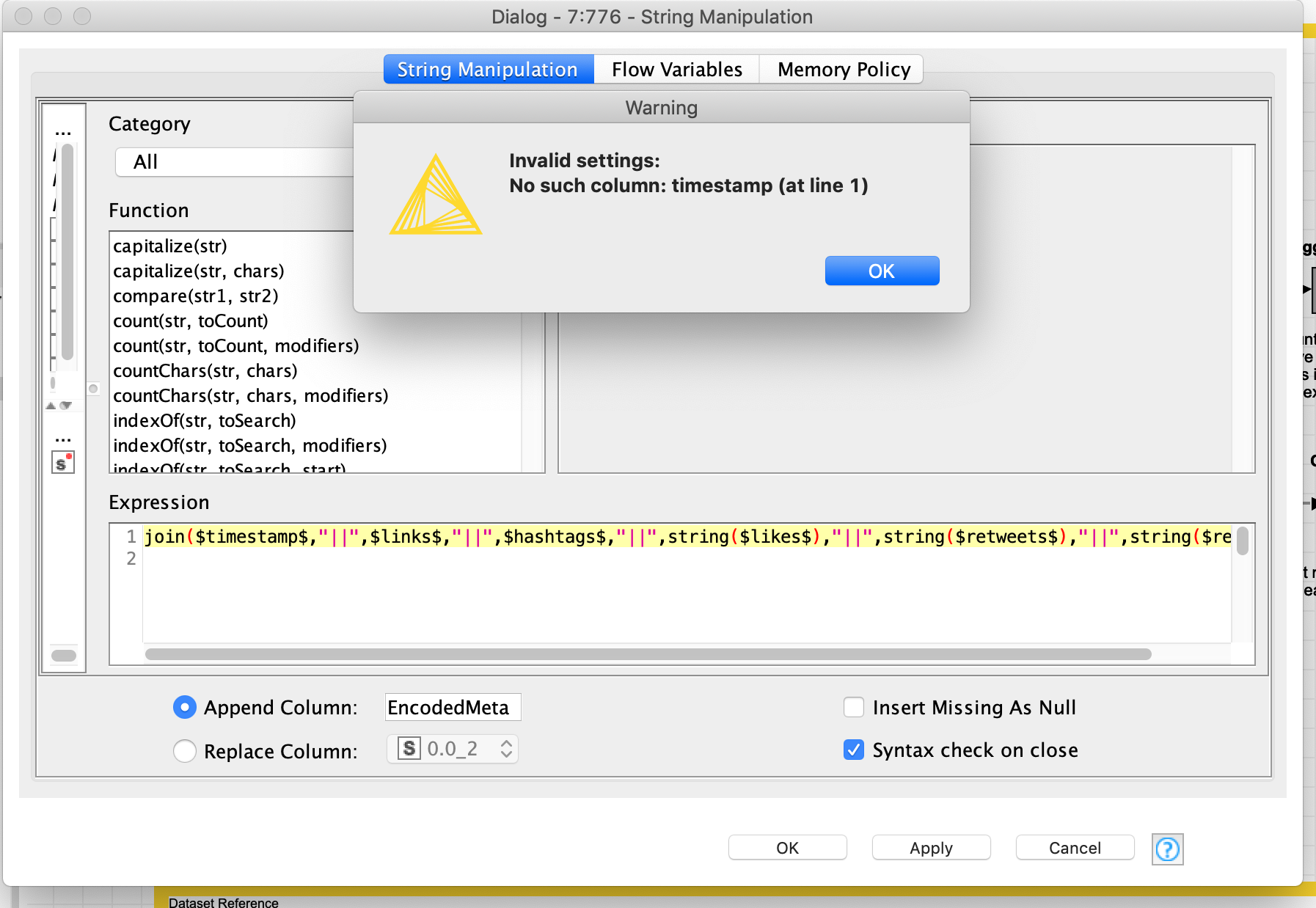
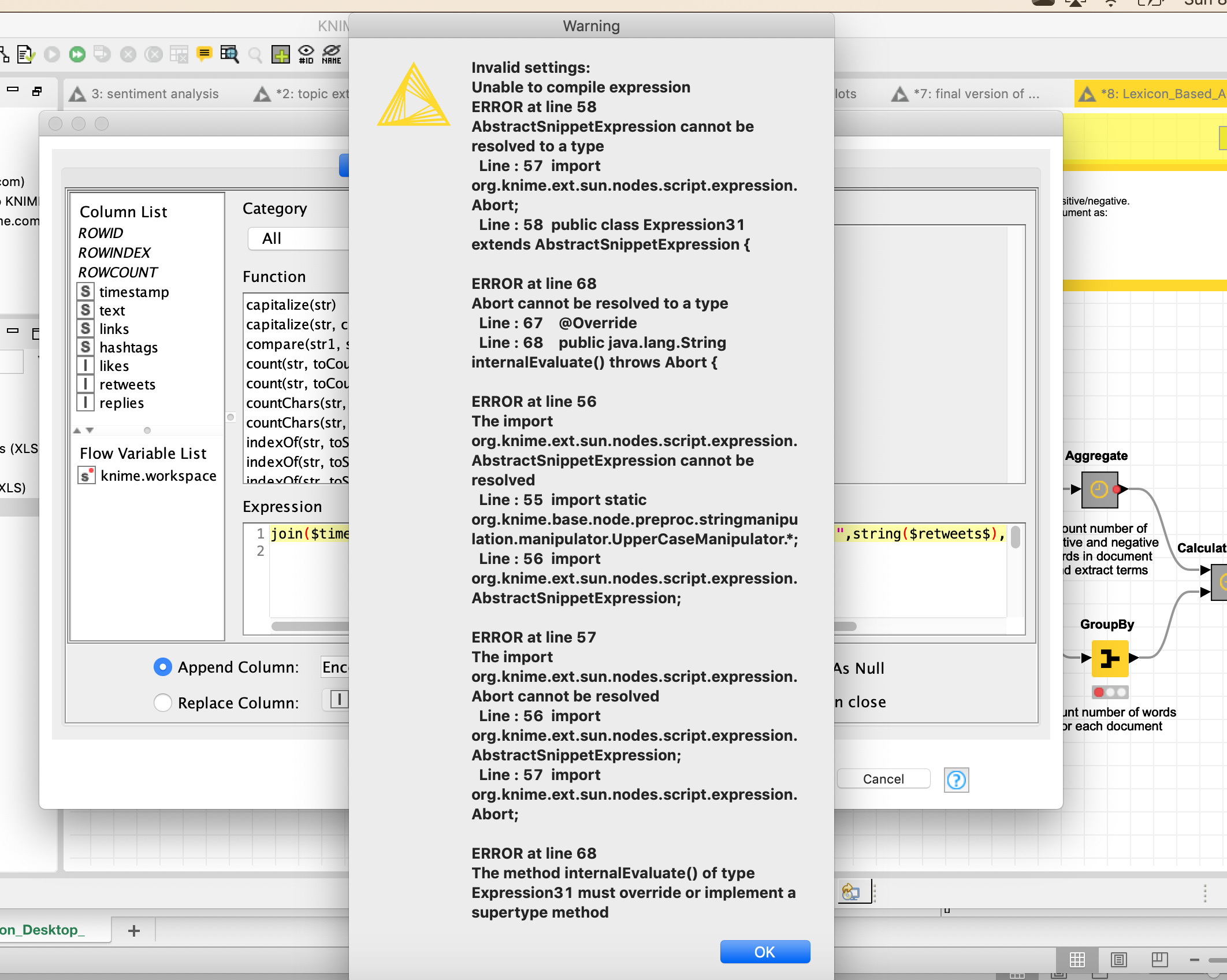
I just changed the file to conduct this analysis for the whole dataset, but I got an error at the string manipulation node. I attached the screenshot of the error. Not sure if I need to do any adjustments to the excel file before uploading it to knime?
The workflow I uploaded should work with the sample file you provided. If your “real” file is formatted differently, you’ll want to take that into the account in the Excel Reader node.
Probably the headers between the real and sample files are different in some way.
The columns’ headers are the same but somehow when I previewed it reads the first column as the headers and includes the headers’ names as the first row. I attached the screenshot of it and also tried to attach the whole dataset but it is a huge file so I took a sample and attached it again.
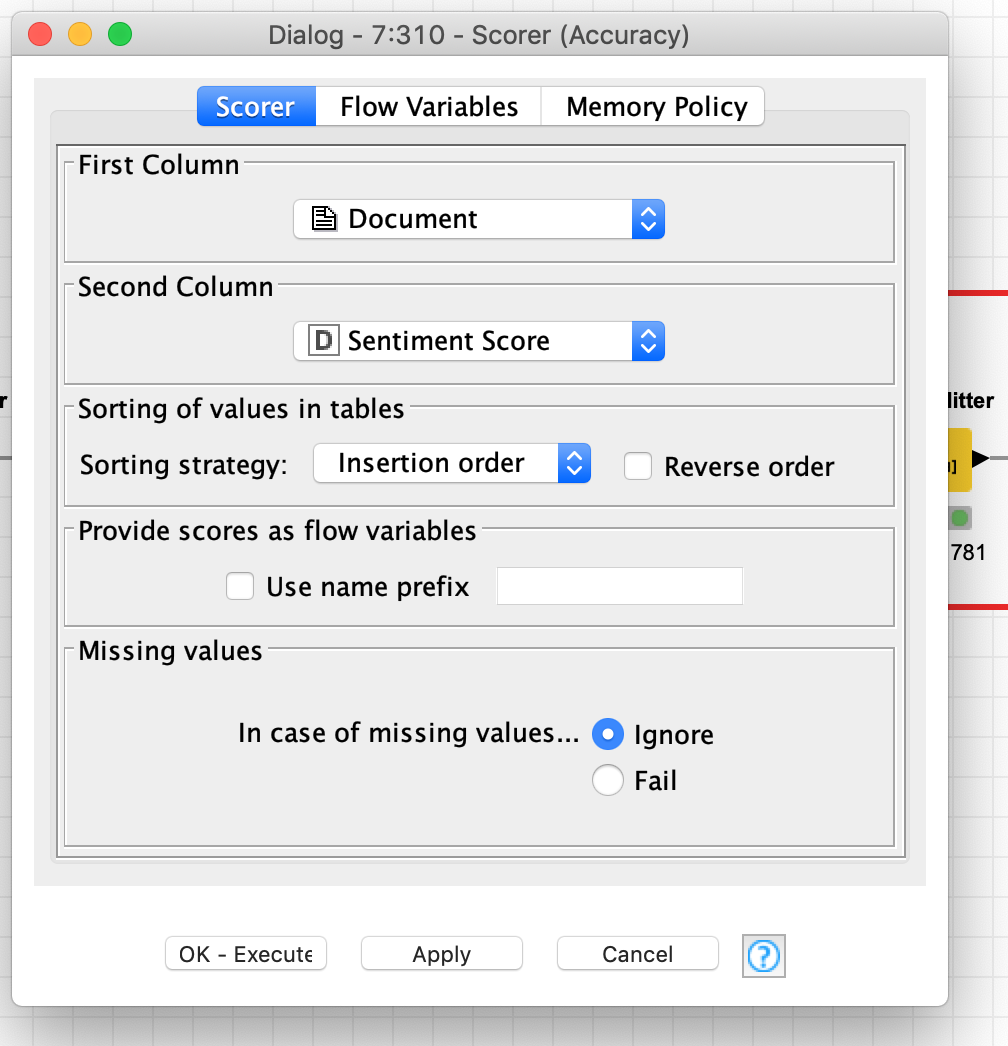
OMG! Thank you…I ran the analysis perfectly. Thank you! The only problem I am having now is with the last node, scorer. It keeps on giving error even with the workflow you sent me earlier. I attached the screenshot of it. Not sure if I need to select different documents for the first and second column. I tried to change it but still getting questionmarks for accuracy and cohen’s kappa.
I think in this case the Scorer isn’t going to do anything for you. In the original workflow sentiment scores were calculated and then compared to the true classfication - that is, we already knew the answer to whether a particular review was positive or negative. In your case, you don’t have that information about your tweets. So it doesn’t apply to your case (unless I’m missing something).
Sorry for another question but I was just trying to re-analyze the data but now I am getting an error each time I tried for string manipulation node. I am using the exact sama dataset with same headings. I also tried this and got the same error message with the sample data I sent you earlier. I attached the screenshot of the error message. Am I missing something?
Before you helped me with this workflow to set up the string manipulation. Later on, when I tried a different dataset, I got the message above and you also helped me to realize the problem. My second dataset started from ROW2 and that caused the error. Now, I am working on a different dataset but still getting the same error even though the column names are the same and this dataset also starts from ROW2. I would be really glad if you can help me again. I uploaded my workflow along with a sample data.