What you can do is adjust the settings. You could tell KNIME to start reading data from line 4 and that the header is in line 3.

This would give you this:
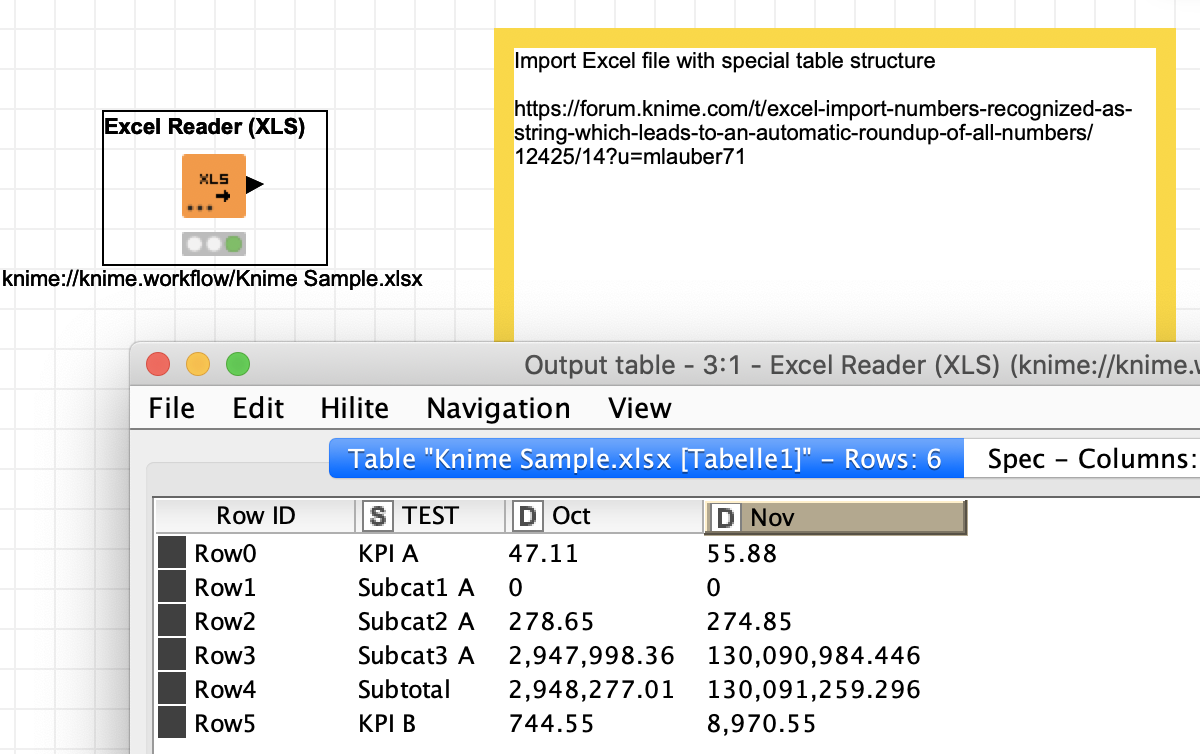
If the structure of your tables does change you might have to be creative. You could first import the sheet ‘as is’ then identify the header line. Turn that information into a Flow Variable and use this line in informing the real import node where to start looking for header and data.