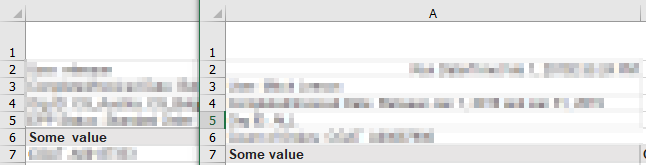
I have a couple loops which are appending various excel sheets together. I have ~50 files in a folder. Some of these files have multiple sheets. Some of these sheets have data that start on row 6, some on row 7. The headers all match.
How can I add a step to the below flow that will search within the first few rows of data and find the column headers where the value ‘some_value’ is found in column A? i.e. some on row 6, some on row 7.
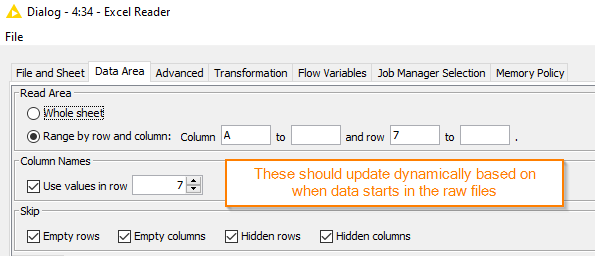
Settings in the excel reader node:
these settings are what I expect to be able to change dynamically based on the data in the raw file
I also use the flow variables for sheet_name
This flow works well only for the files which have the data starting in row 7 (which I can set directly in the ‘Data Area’ settings of the Excel Reader node. I am looking to change the flow so that the data will be appended regardless of what line the data starts, based on the value in column A.
As an example, here’s a sample screenshot of 2 raw data files where the data starts on different rows:
I suggest importing the Excel files without headers. You can then process each file to have an header on the first line and promote the first line to a header.
Hi @mleeson , as @hmfa has mentioned, configuring the Excel Reader to read in all rows, and not to attempt to find the column headings in any row is probably the best way forward. What you do after that though can greatly depend on your version of KNIME.
I think you are in luck because from your screenshots I believe you are using KNIME 5.x (albeit in the classic UI)
With KNIME 5.1 and later, a new node was introduced which helps with exactly the situation you describe:
If all of your sheets will contain the same “header” names, but located at different row positions, configure the Excel Reader to read all rows, without attempting to read a header from any given row, and then pass the output to the Table Splitter.
The Table Splitter is configured to split the table where it finds a known column name in a specific column. You then feed the lower output from that node to the Row to Column Names.
Although not in a loop, an example of this technique is demonstrated in the following webinar.
Skip to (approx timings): 10:40 Describing the problem of differences between two Excel files 11:20 Configuring Excel Reader 12:30 For using Table Splitter 14:20 Using Row to Column Names
One problem with this though is that you won’t benefit from Excel Reader having inferred the data types for the columns. Since every column will have contained at least one String entry (in the row containing column names), all of your rows will now be String data types.
If that is a problem, you will either need to use such nodes as String to Number and String to Date&Time to correctly convert individual columns, or you can try the Column Auto Type Cast to attempt to automatically resolve the data types.