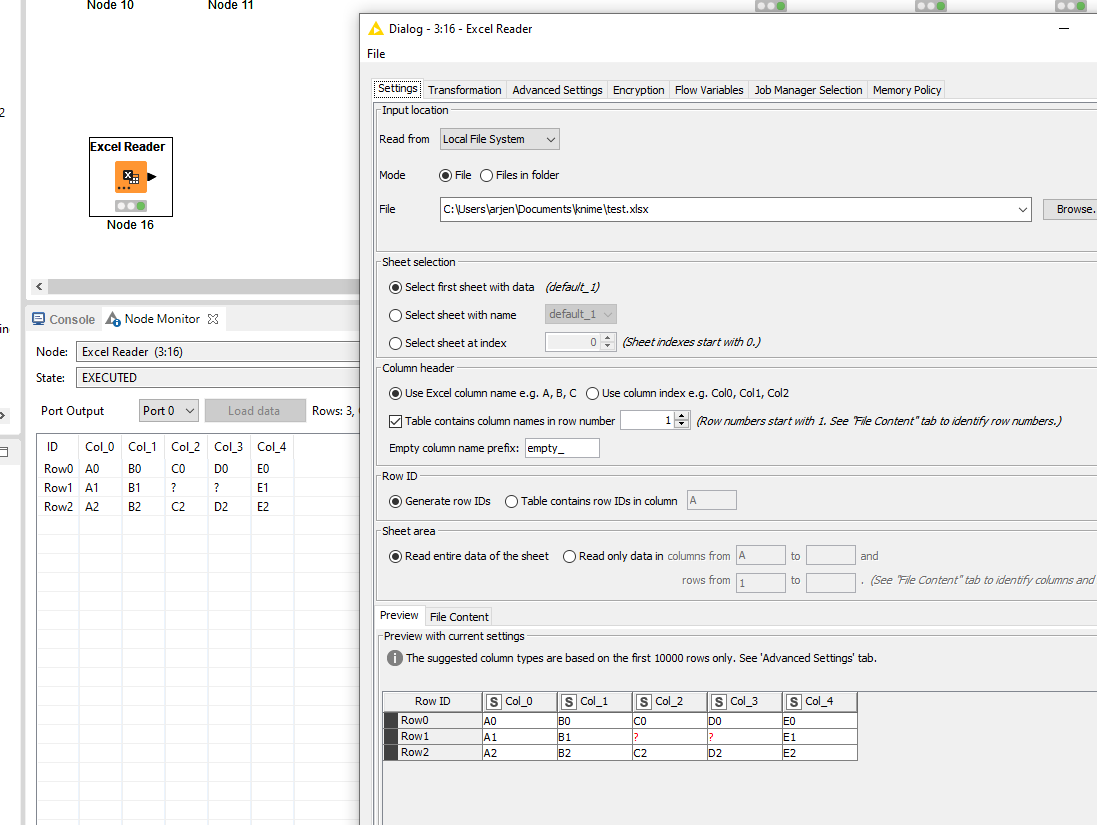
I want to retain the original structure with the blank cells in Col_2 & Col_3.
According to the node documentation, there are two setting that might be involved:
Skip empty columns says:
“If checked, empty columns of the sheet will be skipped and not displayed in the output. Whether a column is considered empty depends on the Table specification settings. This means that if the cells of a column for all scanned rows were empty, the column is considered empty,”
I added emphasis on “all scanned rows”. My data definitely does not have missing data in the whole column or even all the scanned rows.
Replace empty strings with missing values
“If checked, empty strings (i.e. strings with only whitespaces) are replaced with missing values.”
I have checked the "Replace empty strings… " option.
How do I get Knime to stop shifting the right-most cell value to the left when there is an empty cell?
Can you show a little bit more of your configuration of the Excel Reader or even better an example workflow? If I create an Excel with your example data set, drag and drop it into a workflow it all shows fine. Meaning this is executed with default settings only.
Then I personally don’t see any other option then to share an anonymized version of your Excel file, or have KNIME staff look into this. The error message is quite rate.
I don’t see any issues using all default settings on my end… See if it reads correctly if you open my workflow, then point it to your local source file.
Thanks for the feedback.
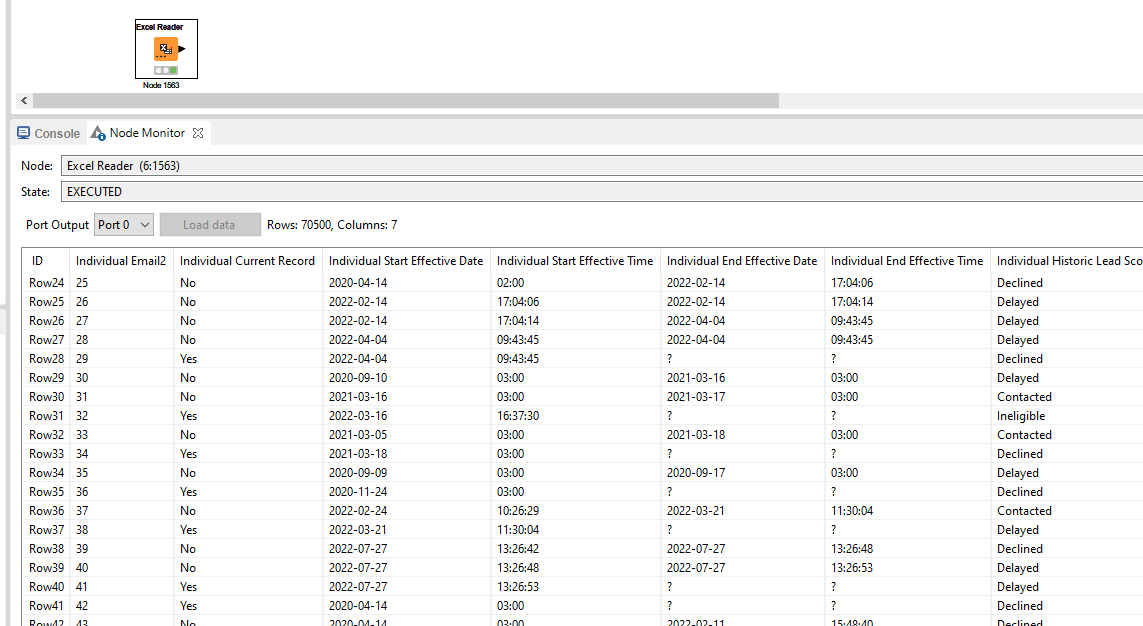
It seems it works fine with the test file I sent, but not with the original file.
The original file is an xlsx created by our Enquire software reporting tool.
To get the sample file, I opened the original in Excel, changed the data in the first column and then used ‘Save As’. I suppose something changed there.
Maybe there is a delimiter issue? The Enquire software only allows export as xlsx. It isn’t even a csv here.
It sounds like a conversion problem on the Enquire side. Can you remove proprietary fields and then do an export from your Enquire software? That way we can see if there is a way to work around the issue in KNIME.
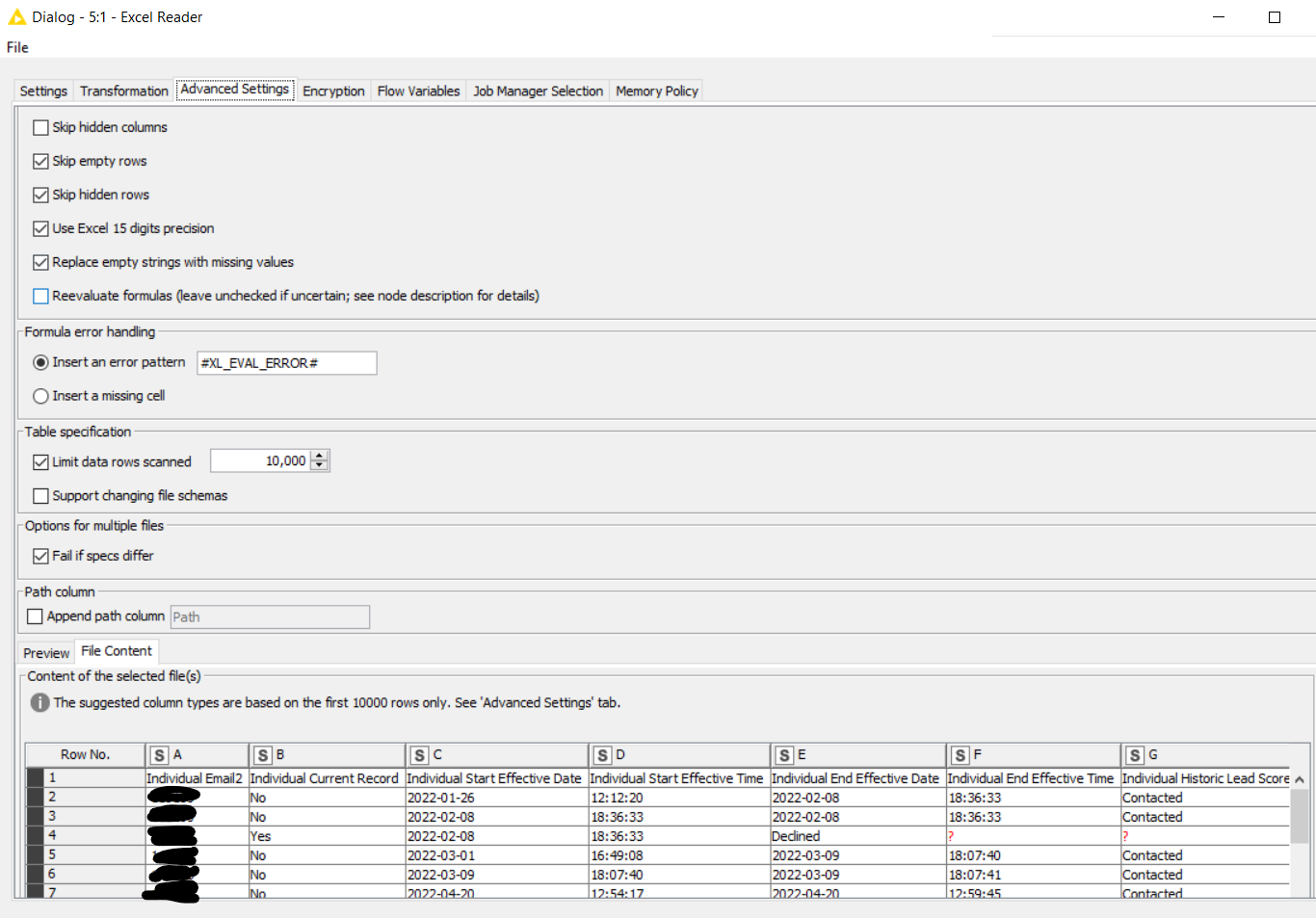
This is the first time that I have encountered an issue like this, so I don’t have a detailed answer as to the exact cause. However, when I scrolled to the bottom row it showed that filters were applied even though they were not visible on the top row (as they were in the other export). I am guessing that these filters (or an export error in the attempt of creating a filter) may have caused the issue that required formula reevaluation. Yes, I would probably check this setting in the future for exports from this system to be safe.
Thanks again to everyone for helping with this.
I did notice the garbage text at the bottom, but didn’t think to check both reports for differences.
I think it’s terrible practice for applications to append text like that to an export. The software can’t even handle exporting the whole report at once, which is why it’s broken into two pieces. I’ll double check that they are built identically.