I am using the Excel Reader Node to read a file. Taking one step back, when this particular report is generated one of the column headers by default is blank and as a result when I execute the Excel Reader Node a warning message appears Column name “” is invalid, placing by “<empty_XX>” e.g. <empty_17> the problem here is that the XX changes each time I execute the node and therefore has a flow on impact to the next node which is “Column Rename”, rename blank column name to Country, because I have to reconfigure this node to pick up the new name for the “[blank]” Column Name.
Other than filling in the invalid/missing column name in the underlying excel file first before reading it in KNIME is there any way to solve the invalid column name in KNIME itself? Excel Reader Warning invalid column name.docx (37.4 KB)
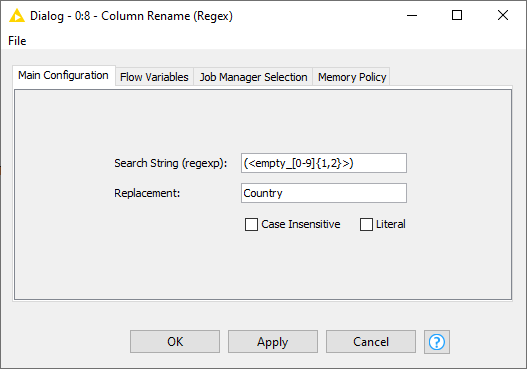
My suggestion would be to try using the Column Rename (Regex) node with the following settings:
It tells KNIME to look for column headers that contain the string <empty_ followed by a 1 or 2 digit number and the closed caret. You can modify this as you see fit.
While you were responding I did happen to play around with Column Rename (Regex) so good to know I’m on the right track.
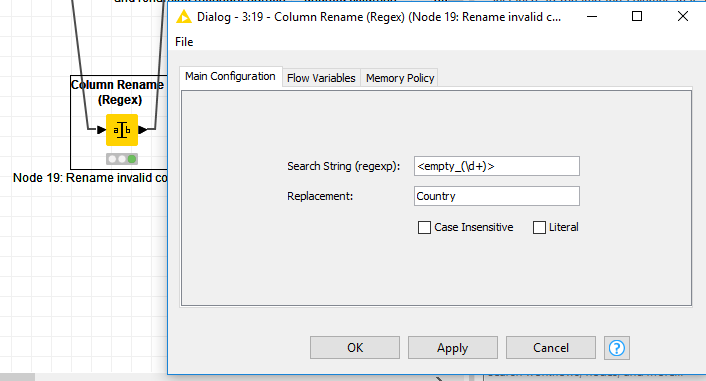
I however placed a different expression against “Search String (regexp)” where I used “<empty_(\d+)>”
which works. Would you perhaps be able to help me understand why this works too? This aside, I will use your suggestion because I can logically follow what you’re saying.
That definitely works, and is a more general Regex than my suggestion. It matches the string <empty_ followed by 1 or more digits and ending with the closed caret.
we are currently revising this node and we are always happy to get feedback. Is this way how blank column headers are handled (replacing by <empty_xy>) actually a good way to do it for you?
Note that there is a difference of “empty” and “blank” column headers. Blank means that there is only spaces in the cell. That’s your case, right? So you’re having something like " " (note the space in between). Those headers are replaced by <empty_XY>. If a cell is empty, i.e. "", the header is replaced by ColumnXY.
The solution we are thinking of right now is a bit different. The user should be able to set a prefix that is used to create blank headers, i.e. a blank header is then replaced by prefixXY. This prefix could be, e.g., “empty” by default. Also, instead of replacing empty headers with ColumnXY, we use the column headers that Excel uses which are “A”, “B”, “C”, etc. This also means that if you are not using column headers at all, this will result in column names that are the same one as in Excel.
Based on your explanation it suggests to me that the cell in the column headers row is “blank” and therefore it is replaced by <empty_XY> but to me when I look at the underlying data it suggests to me that it’s empty.
If one cell within a column headers row is empty (i.e. “”) would it still be replaced by ColumnXY and does the XY change each time the node is executed similar to what happens in the instance of blank cells? If yes then I would say this is also unhelpful especially when you need to later point to this cell in the workflow but the workaround I guess is using the Column Rename (regex).
For me it would have been helpful to either leave it as is or where a cell in column header row is blank or empty then replace with the column header per excel e.g. in the File Content tab the blank cell appeared in column E so perhaps it could have been renamed to column E but the remaining column names were per my underlying data. Based on your expertise how would this work in KNIME?
As an aside would you please advise if there is an opportunity to meet with KNIME (perhaps a Team Member with expertise) one on one to receive feedback on my workflow? As a new user and I believe the only active user in my organisation it would be good to get some feedback however as the information is confidential I would not be able to send therefore thought a meeting would be good.
Yes it should have some empty spaces in there. If you e.g. read it in as a normal row, so not as column header, it should not be a missing cell but just empty.
Your case is a bit tricky as the column with empty header is changing it’s order. If it stays at the same place, it would always have the same name. However, Column Rename (Regex) sounds like a good way solving such issue.
Empty column names are not possible in KNIME. If we are adding a configurable prefix, you should be able to set this to empty and the column would be named E.
In general, the forum is the best place in this case to ask for help/feedback. You could anonymize your data or create some toy data that represents the structure of your data.
I will have to look into this further because in my scenario the blank column is staying in the same place so I’m not sure why the default <empty_XY> is changing. Having said that Column Rename (Regex) is working for now but what if there’s a situation where I have more than one “blank” column header cell to rename (see example below), how would I best solve for this in KNIME?
the changing name might be a bug of the current node. If you’re having en empty column name in column E, this column will be named “empty_E” with the new node. So in your case, then you could simply use a Column Rename node that renames “empty_E” to “Country” and “empty_H” to “Product level 3”. No need for the regex node anymore.
Blank ("") column names will be handled the same way as empty ones (" ") to avoid confusion there.