I am reading list of excel files in knime using excel reader how ever there is one corrupted excel file in the path which can’t be read is there way to ignore that file using knime
Also I want to know the corrupted file name
I have almost 567893 excel files I can’t remove each corrupted file manualy
Hi @Ashok121 , that’s certainly a lot of Excel files to be processing!
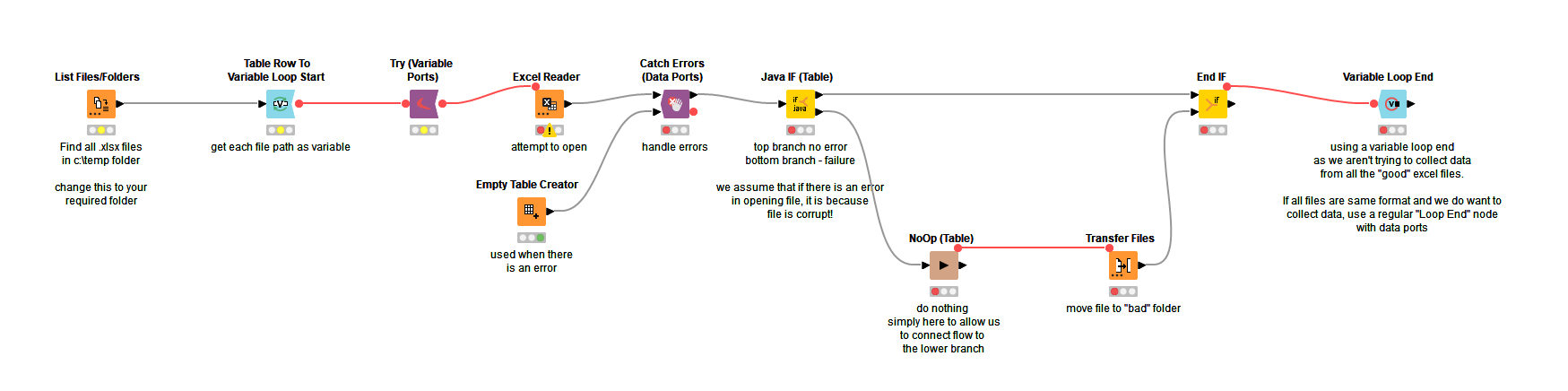
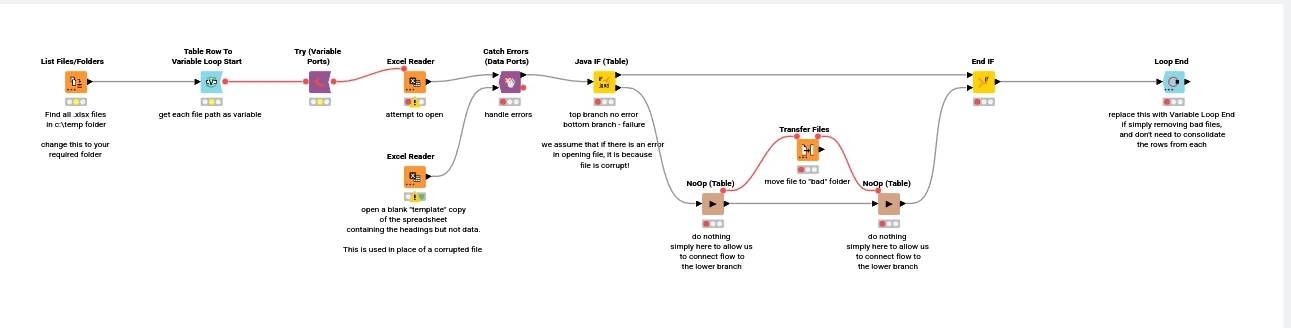
You could perform this by wrapping the Excel Reader with try-catch nodes and then handling any errors by then transferring files that wouldn’t open to a separate folder.
This workflow was written using KNIME 5.1, but should work equally with KNIME 4.7.
The NoOp node is available from NodePit, and does nothing except provide a means of doing what the branch needs to do!
If you can’t/don’t want to install that, replace it with an Add Empty Rows node, with the config “Additional” set to 0, or you can use my “pass through component” which I wrote before discovering “NoOp”
Assuming that all of your Excel files to be consolidated are of the same format…
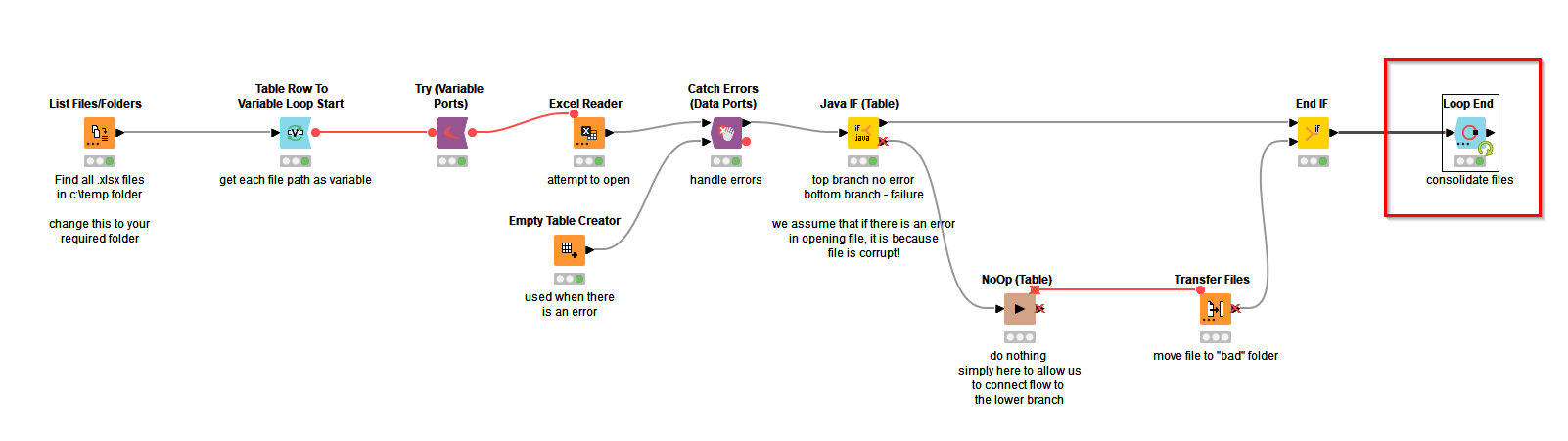
If you want to include the error handling as in the demo workflow, then you can consolidate the files by replacing the variable loop end node with a Loop End node:
The output from that would be the consolidation (concatenation of rows) from all the excel files that have been read.
Alternatively, if you are able to first remove all “problem” files using the demo workflow, then you can simply read all files from a folder (and potentially subfolders) , without all the additional nodes/loops in the demo workflow by configuring a single Excel Reader, and the output would be concatenation of all of them.
Hi @Ashok121 , I’m not at my pc now, but it was the workflow that I shared on the hub before; only you should just need to change the last node from this
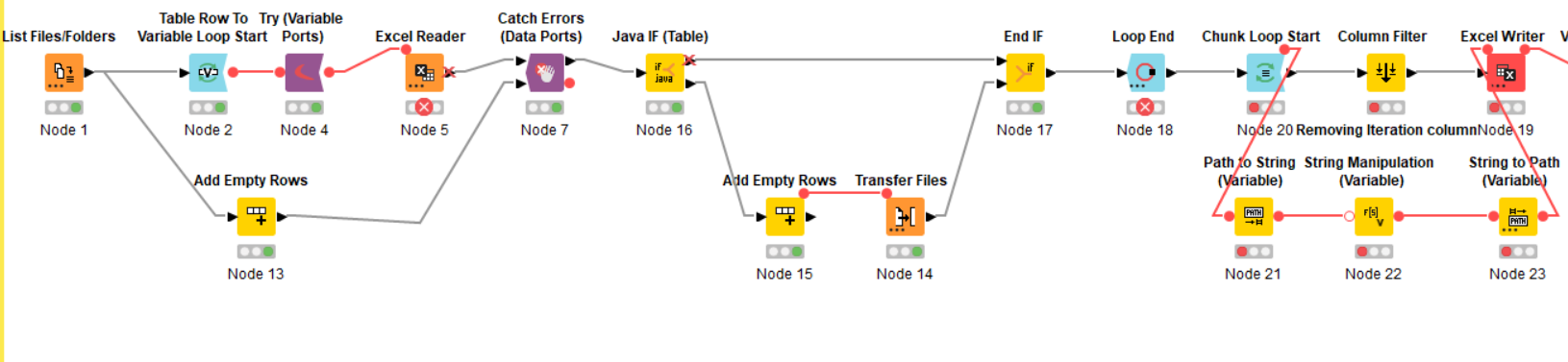
i Tried the Workflow i mean the second one with LOOP END
getting Error as Execute failed: Input table’s structure differs from reference (first iteration) table: different column counts 5 vs. 16
i tested this on small folder in which there is 10 corrupted files however it moved all corrupted files but loop end i am getting error
Hi @Ashok121 , it does sound like at least one of your Excel files has a different structure to the others. It could be as simple as a column being in a different case, or additional spaces included in a column name. It isn’t necessarily “corrupt” in the sense that it cannot be opened, simply that it differs from the others. This can often happen if the files have been created manually.
You can try configuring the Loop End node and tick “Allow changing table specifications” which will then cause it to adapt the columns to include all different table formats received from the various excel files.
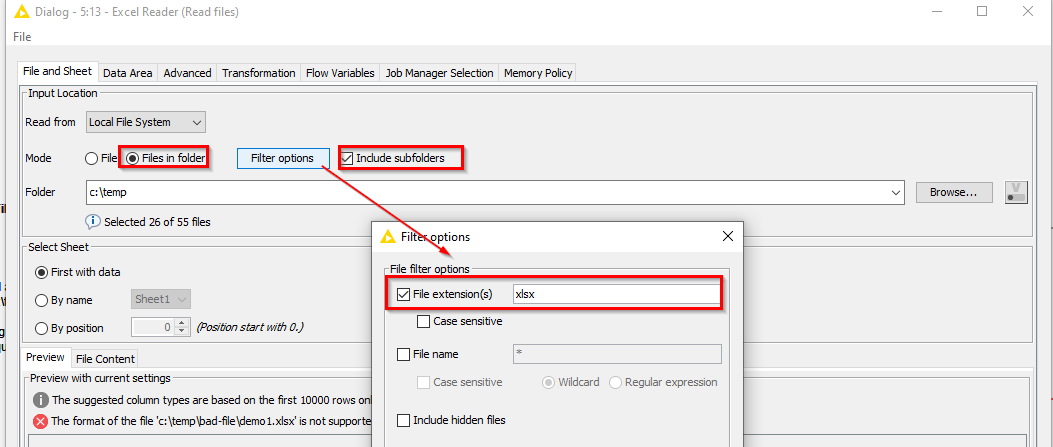
In the “advanced” tab of the Excel Reader, you could also tick the “Append file path column” so that the file path is included. This will give you clues about which file has a different table specification to the others.
Ah ok, thanks for the additional information. I think I can see what the issue would be, that I had overlooked for the Loop End node. When it finds a corrupt file, it doesn’t read it but will use the output from the Empty Table Creator node. This will probably be the cause of the problem, because that Empty Table is not the correct format!
The simplest thing to fix that (I hope!) would be to create an Excel file which is the correct format, in terms of column names but which has no data rows, then replace the Empty Table Creator with an Excel Reader node that reads that file and passes the empty table to the lower port of the Catch Errors (Data Ports) node.
As an addendum to this, which I thought I should correct here for future reference, I updated the original workflow on the hub to remove a further mistake. The output from Files should not have been passed back to the loop. This was the additional cause of the changing table specification problem when a corrupted files was moved.