I was searching already the whole forum and could find some helpful pieces that I included in my workflow, but I am still struggling with other parts.
The Situation
For my company I need to create a JSON format (for a POST request). This JSON file will be created out of an Excel file. The structure in JSON needs to look like this:
Yellow area is a simple format where every column from excel is one object in JSON.
Orange area “DIs” will be a nested array that consists of different nested objects (green boxes).
So i basically have a main level, and then different DI categories (DI2, DI3, DI4, DI5) which are like a sublevel within the “DIs” category.
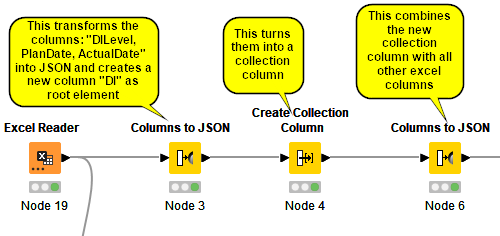
I already learned from some topics in this forum, how to create a nested array.
I did it like this:
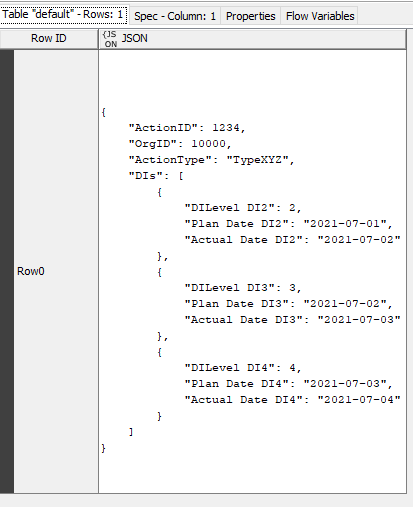
Result is:
That is perfect.
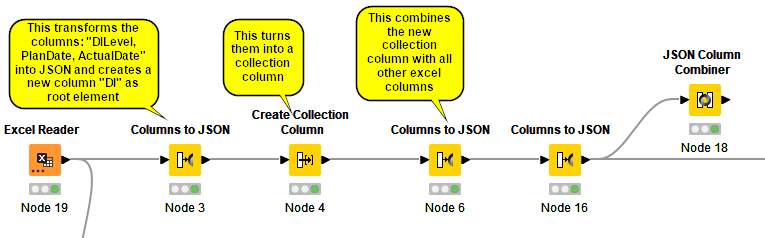
But now I need to add the second (and 3rd, and 4th) green box within the array “DIs”.
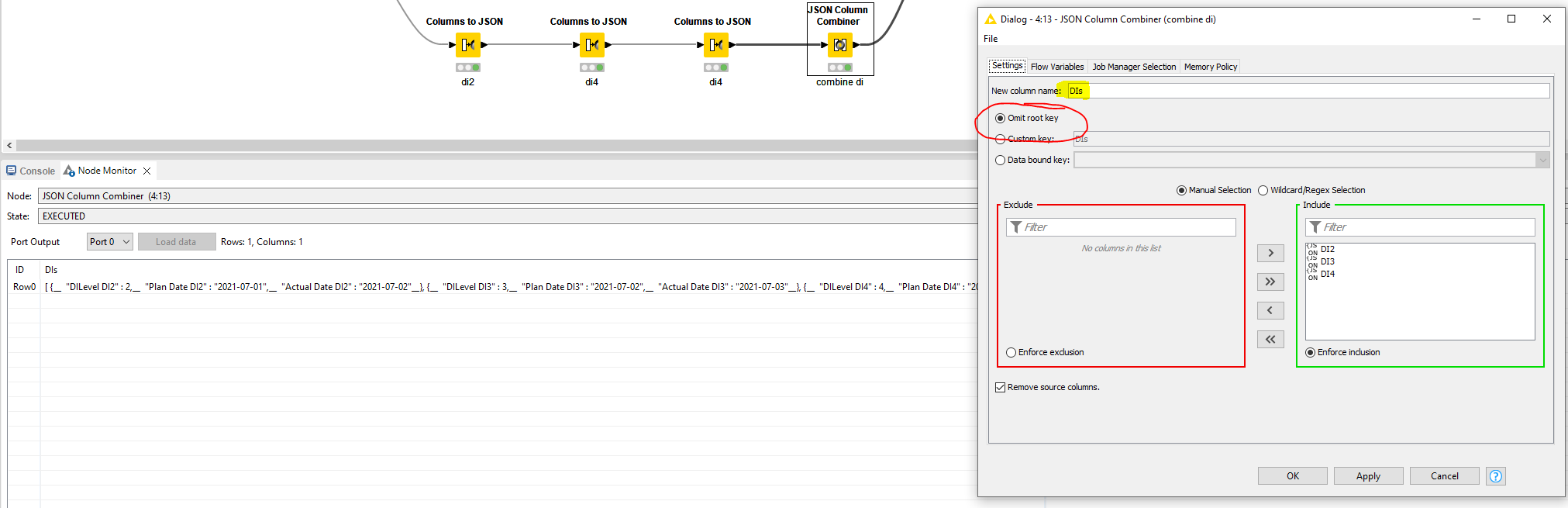
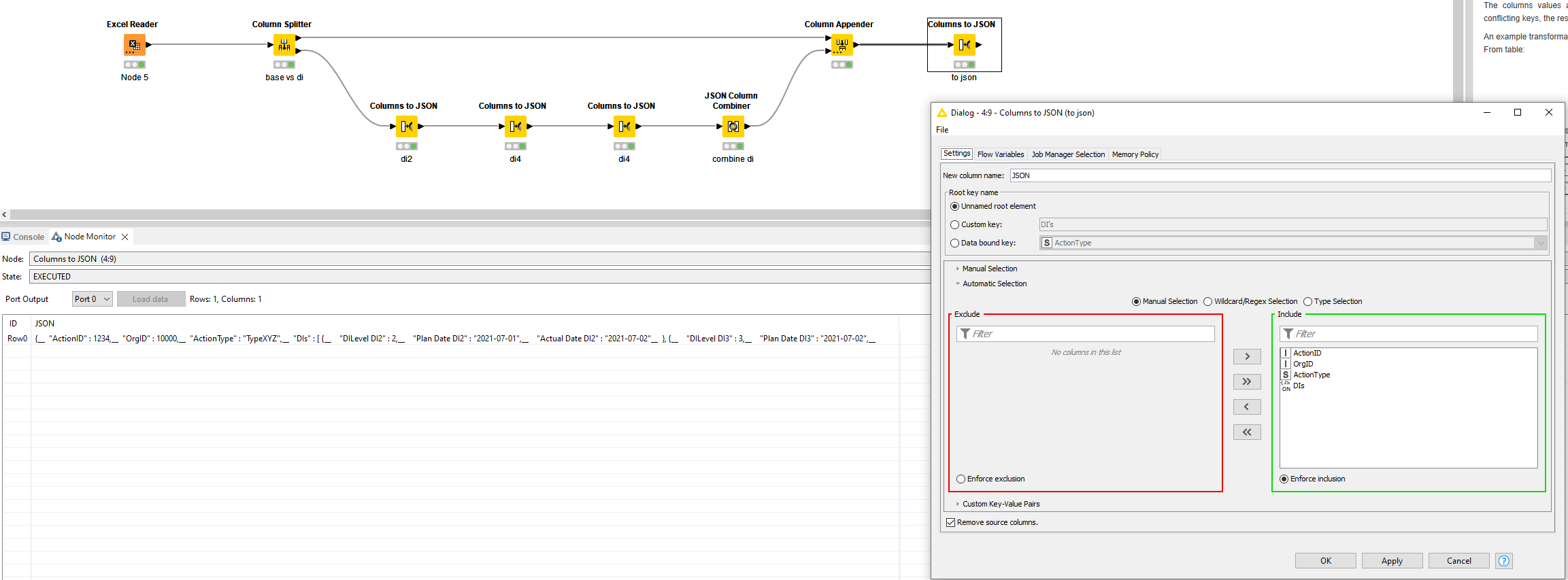
So I tried to repeat the first steps for the next nested object and then try to combine them:
But result is not as expected. Second green box with DILevel 3 will be created as a seperate object on the main level. But how can I move this object to the sublevel within the “DIs” category, below the DIlevel 2?:
For Json, you have some other options to use… as table to Json that you can bring you table rows into a Json sequence and Json combiner (rows/columns).
Just a tip, you have the Containers options too that will convert all into a json scheme and you can use it after with other workflows and requests as you need.
For the last tip, you can use Json reader to build the structure and then make changes/replaces to manipulate the information, so you can make a mask and replace with string manipulation to change the content as you wish and then, you convert again into json type.
I hope that some of them can help you now as a shortcut for you…
As a general tip, it’s always useful to include the Excel file that you are using with the same dummy info as in your screenshots so people can understand the structure of your source file This avoids assumptions and could make a big difference in the approach that you can take.
In general, in situations like this it is best to start at the lowest array level and gradually work your way up. This is one approach assuming this is the structure you have :
Hi @denisfi I tried the container method, but I just couldn’t find out how they work and how to combine them all unfortunately. But I like the idea of creating a template/mask. If you can show it a bit more detailed, I would be happy to learn.
@ArjenEX That was amazing. I re-built it according to your guidance and it worked! Thanks a lot!
Now PART 2:
Second question. I just didn’t want to overload my fist question. I like to tackle problems one by one.
So here is the next thing:
As you can see, in my Excel I have the columns named like this:
o DILevel DI2
o DILevel DI3
o DILevel DI4
o DILevel DI5
This is important so that users know where to enter the dates for the different DI levels (btw: DI = Degree of Implementation).
But the JSON format requires this:
That means, all DILevel columns have the same name.
How can I rename now these objects during the workflow?
I realized when I use some kind of JSON/Table transformation or Column Rename Nodes to give all columns the name “DILevel”, that it won’t work as KNIME automatically makes it “DILevel (#2)”, “DILevel (#3)” and so on.
Since we’re dealing with rows and columns that need to stay separated, I initiated a chuck loop, making the WF process each record individually.
Make a split between DI and non DI information (similar to the first version). For the DI, I initiate an Interval Loop between 2 and 5. This corresponds to your DI numbers.
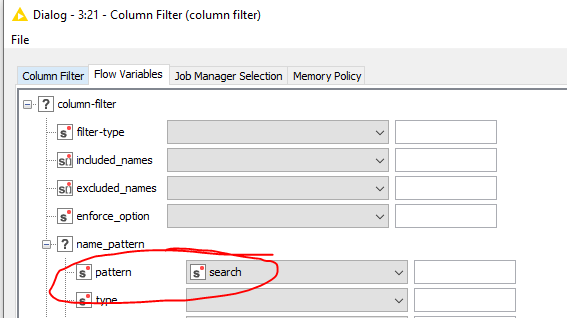
Due to the common column name issue, I process each DI individually. As such, I need to dynamically filter for the DI that is being processed to later on create the JSON. This can be done with join("*DI") + string($${Iloop_value}$$). Convert it to a flow variable and pass that to a Column Filter node. Make sure the variable is applied properly.
It’s then possible to remove the DI from the column name when using [ ](DI)[0-9]+ in a Column Rename (Regex) node.
Append that again to the non DI information and create the final JSON (use unnamed root element again).
Exit the outer Chunk loop. If you eventually need to do the POST request, you can technically already put that after the last JSON creation before the exit the outer loop.
Note that I didn’t cater for the possibility that a DI between 2 and 5 is not present. If could be that the workflow crashes or outputs unwanted results like an empty JSON, but I will leave that up to you to catch
Wow, thanks. This solution was different than I expected
Never worked with loops etc.
As I never want to just copy solutions, but really understand them, I tried to also find an own way.
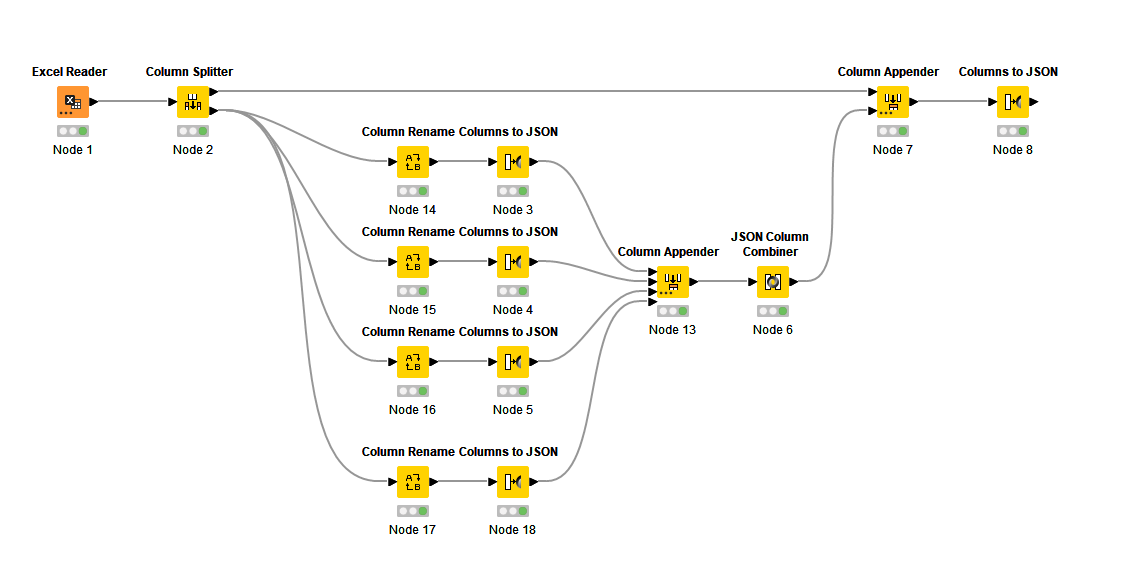
Inspired by your loop, I thought what if I just split the task in 4 different sequences, rename the columns and then append them again. Some kind of a “manual” loop.
This is what I did:
I am really happy with that.
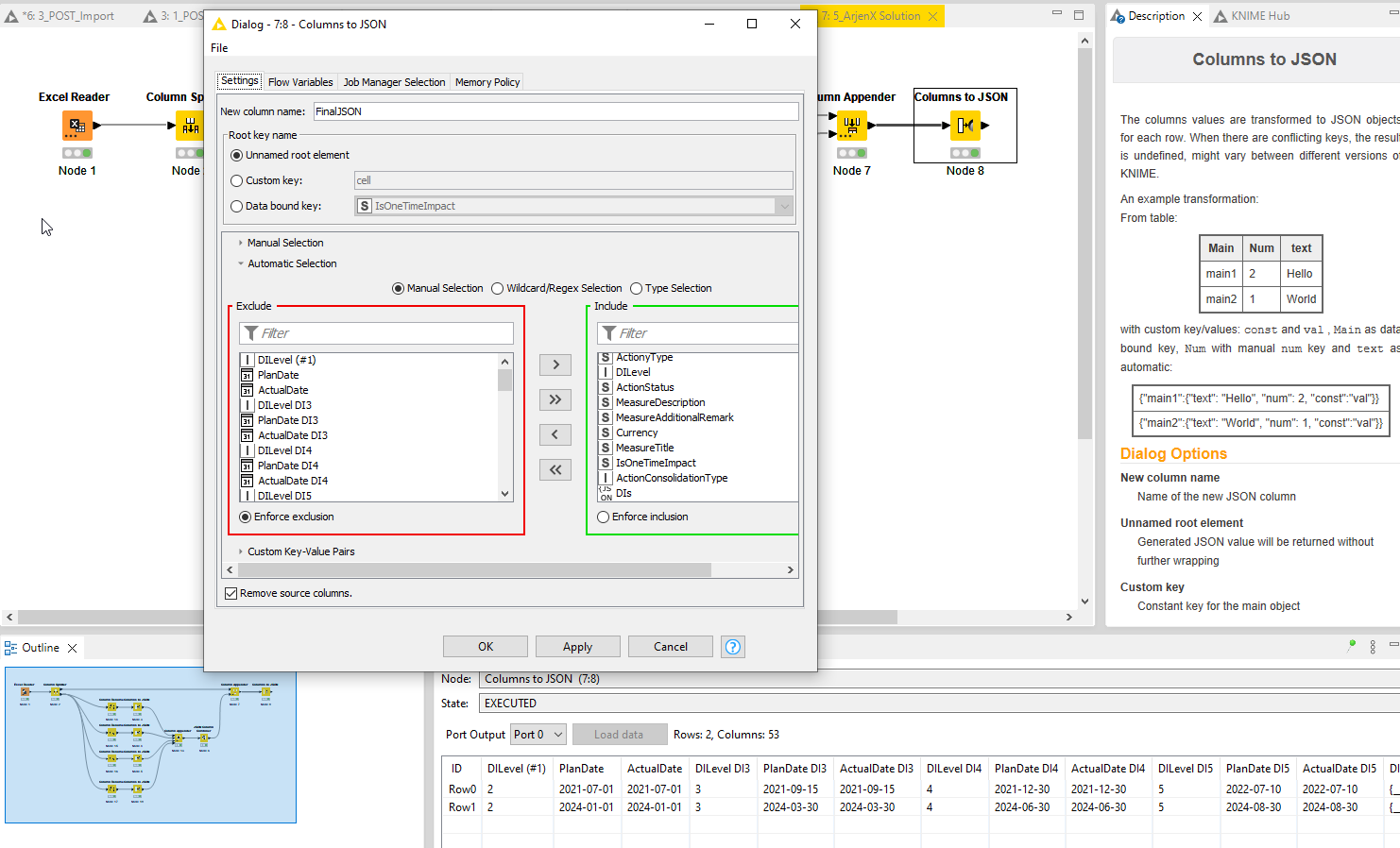
Question here is: How do I get rid of all the other columns? Or is that not important if they all appear there, because in the POST Request node I can for example select a specific column for my body, and thus I would just select this last column called “FinalJSON”…?
This is the full picture from the last node (Node 8, Columns to JSON):
But you’re right, in the POST node you just select the finaljson column as source for the request body. Otherwise just use a Column Filter with enforced inclusion/exclusion.
Sorry by the later message… many projects takes a lot time from me from these days…
When I suggest a template/model, you can just create a simple/silly json scheme and map some parts to be used as “flags” to be overwritten when you need.
Don’t forget to convert it into Json format again to use as body for your request, but you can see that a simple solution to manipulate the data as you need.
I made it for a project that I needed to change some body requests using the same “template”, avoiding me to expand a lot of time and process for each case.
Ah great, that worked. Also a very interessting solution.
Trying to work with both solutions really helps me to improve my KNIME skills and discover different nodes and workarounds
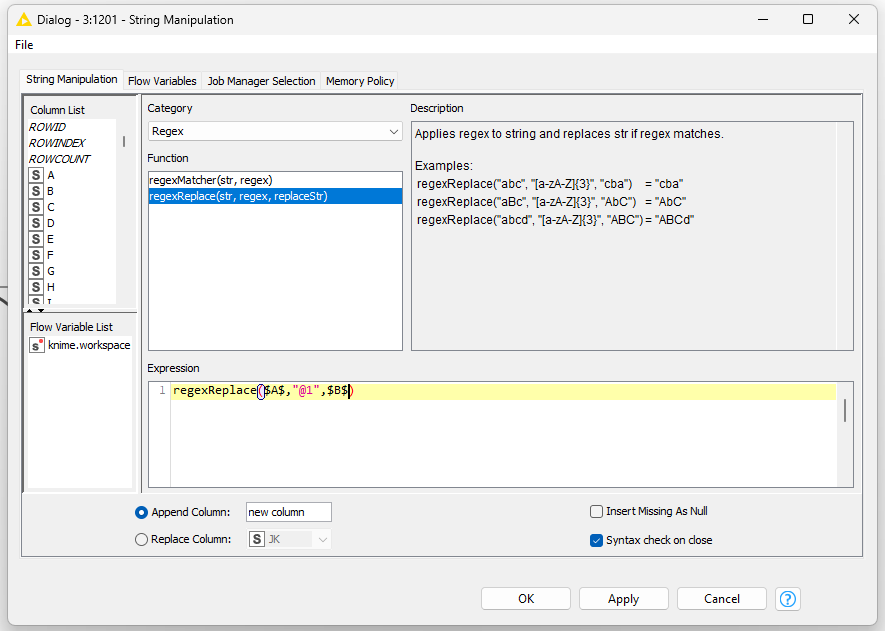
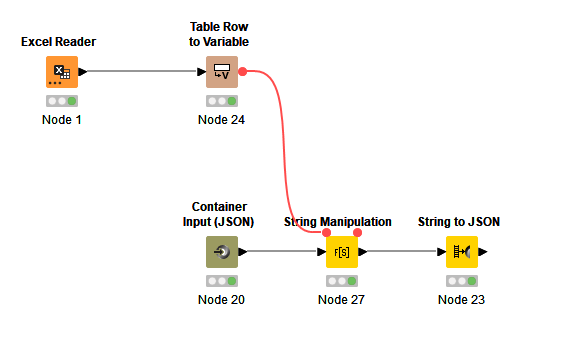
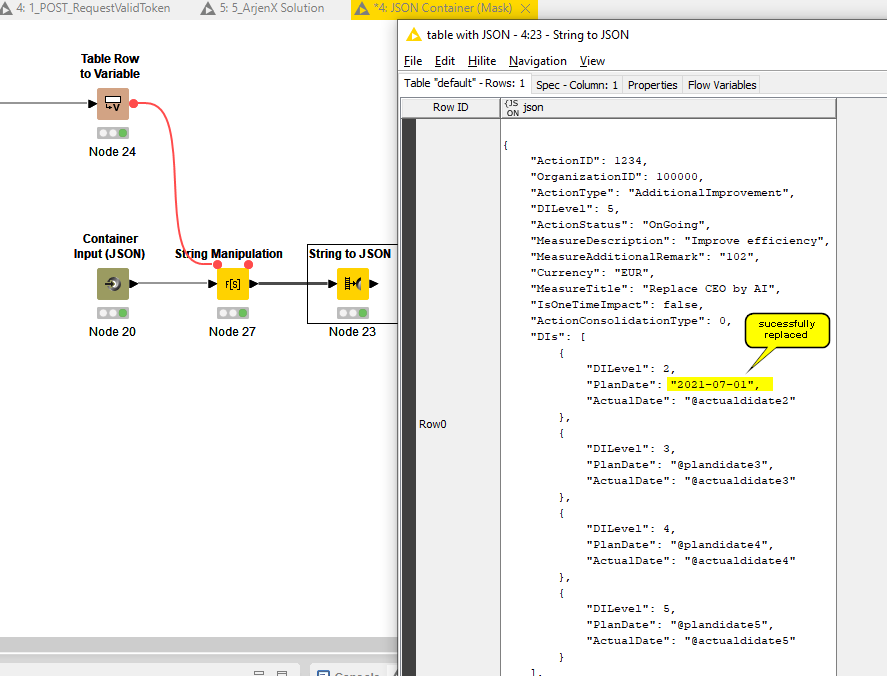
This is how I did it:
The columns from the excel are transformed to variables so that I can use the excel values for the string manipulation later on.
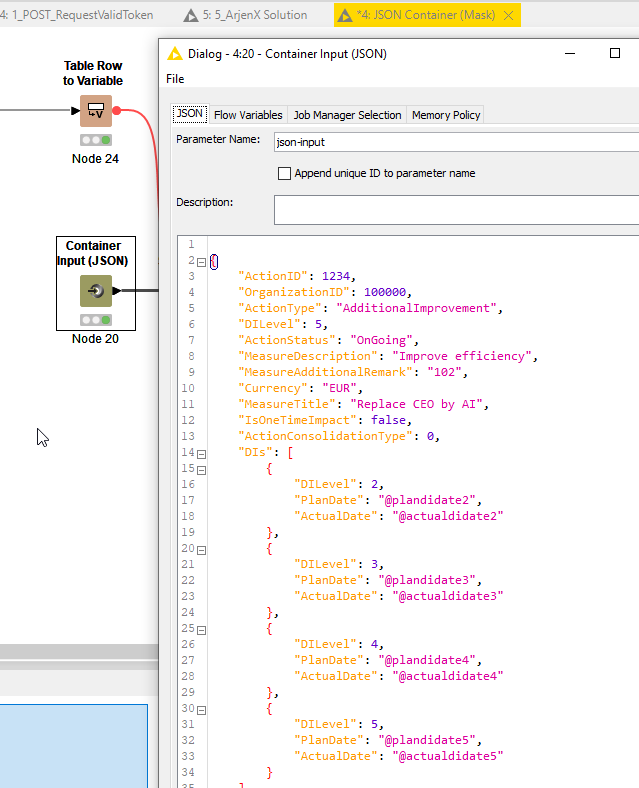
My JSON Mask from the Container Node looks like this:
How can I manipulate many many more items? String manipulation only allows one expression. I would need maybe 50 replacements in the end
All this was only replacing the first row from the excel file. But how can this be done for all rows?
So I have one JSON mask, but as my final Excel file would have up to 300 rows, I would need this mask to be created hundred times and replaced also respectively.
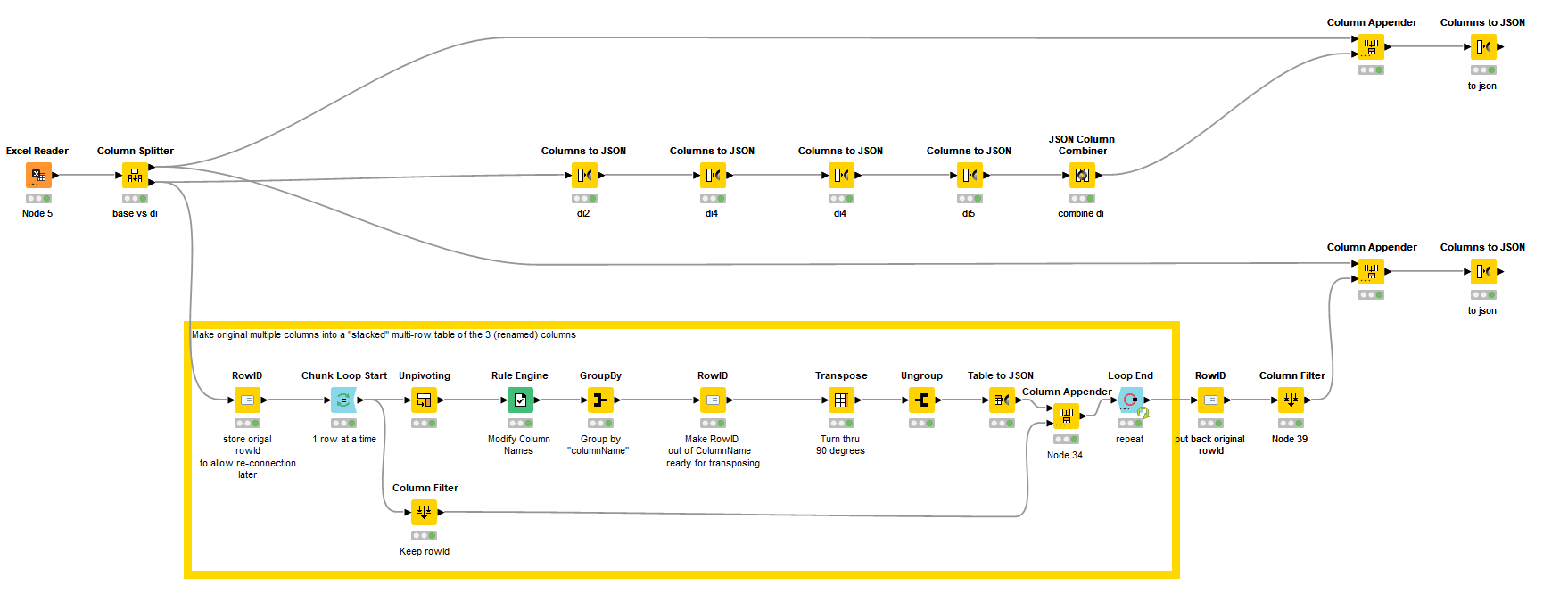
I was watching this topic a week ago, and was having a play with the original solution with a view to making it more scalable (using a loop instead of a sequence of “Columns to JSON” nodes). The loop adds a little complexity and as you already appeared to have a solution, I didn’t upload it.
Now I haven’t followed closely since to see whether this will assist you (nor indeed if it simply covers the same ground that has already been discussed) but given you are now talking about problems with performing the operations on a much larger set of columns, I wonder whether some of the ideas in here can assist.
The top branch is one of the earlier solutions offered. I’ve left it in so you can see where my workflow fitted in with the timeline of this thread. As you can see, the “loop” version increases the nodes and complexity, (but does not have to be modified to handle increasing iterations of the same columns) in order to return, hopefully, the same result. I hope it offers some ideas
Hi @ArjenEX, Yes I just looked back up the posts and saw that the thread had continued on without me
I don’t know that my solution offers anything other than an alternative, but sometimes the final answer turns out as a “take the best of both”. I often find looking at other people’s workflows such as yours and seeing how other people approach it allows me to have sudden bursts of (“stolen”) inspiration on an unrelated task a few weeks or months later
Wow, great thanks a lot guys!
Okay, so now I have a few solutions from you with more or less the same idea but different built.
Really interessting.
Today I will receive the full JSON format from a colleague so that I can fully start working on the whole solution. I will work myself through your solutions and try to understand and rebuild the workflows.
Latest end of this week, I will give you my feedback on this
But hopefully I am quicker