I have noticed that recently the Excel Writer and Excel Sheet Appender nodes write extremely slowly compared with nodes like the CSV writer. For example, writing 30k rows x 15 columns takes a few seconds using CSV writer, but over 15 minutes using either Excel node.
I tried using the CSV node to write to a file with an .XLSX extension, which goes very fast, but doesn’t open as it says the file is corrupted.
I think the Excel Writer node is not capable of streaming writing (practically write row-by-row), so it needs to create the whole xls(x) file model in-memory. If the memory assigned to KNIME is close to the memory used during xls(x) writing, the process will be very slow. You can try assigning more memory.
(csv and xlsx are very different file formats, no surprises that renaming is not enough.)
And just one other thing. It is important that the Excel file you are opening is not big, otherwise it will take some time to load as well as Apache POI, the underlying library that KNIME uses, opens the whole file in memory each time you use the node.
Reviving this topic with a specific query regarding writing over a VPN to a network.
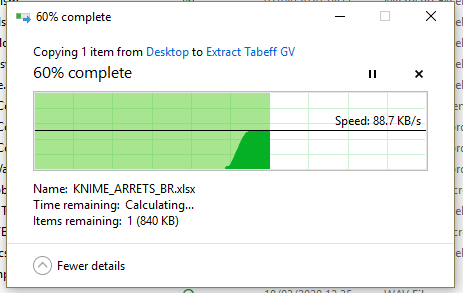
Due to the current situation and having to work from home, this workflow is now causing considerable difficulties as it tries to write over a VPN to my work network.
For comparison writing the Excel file locally takes ~7seconds.
Now the execution is more like 45-60 minutes!
I have noticed that often the Excel Writer ‘pauses’ at 80% for a long time, I see the same 80% pause when writing locally but obviously it’s for a split-second.
Our network can be painfully slow at a distance but not so bad as to take 60 mins to save a 5mb file.
A Knimer (Ana) asked me to check whether our network is mounted via samba. I’ve had this response so far (translated from French). He said he has forwarded the question to the server admin.
We are pure Windows, unix / linux only use on esx via VMware ESX
Samba is a set of protocols to run unix / linux and windows together.
And what I don’t know is the proprietary communication of ESX (physical server that runs all of the brecey / granville servers)
OK I tried with Copy/Move Files - it was a little faster but not dramatically. And this is with one of the smaller files I need to create too (only 1mb)
I did a manual copy in Explorer and you can see how painfully slow the transfer speed is…so I guess it does come down to a slow network.
Any other suggestions how to overcome this bottleneck?
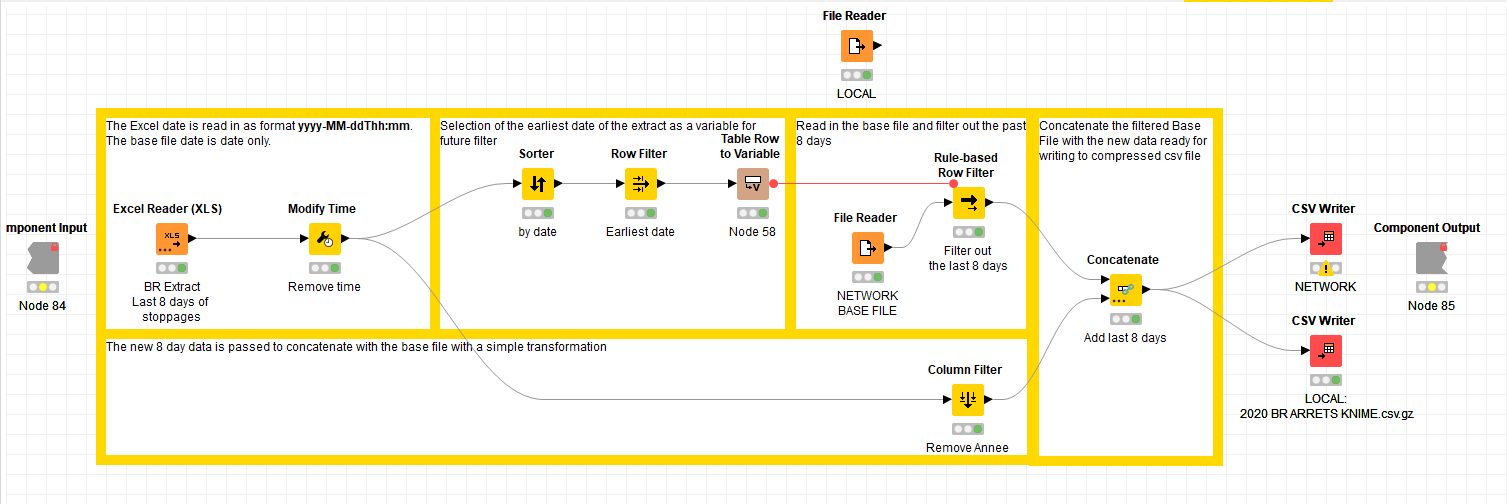
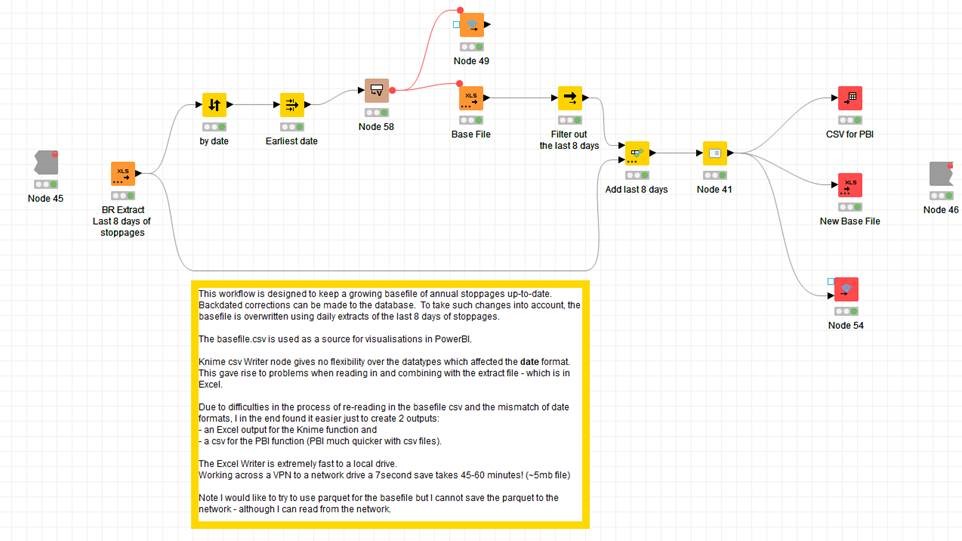
Perhaps the way I’m attempting to do the workflow is faulty…my aim is to replace the last 8 days of production in a base csv file (this is done on a daily basis with an new extract of the last 8 days - this way we catch changes to the production database that have been backdated within the last week).
The problem is that the daily 8-day extract is in Excel and I had no end of fun with the format of dates between the two file formats…
Could it be an idea to ZIP the files upload them an unzip them? The unzipping would have to take place on the remote system.
Next idea could be too use parquet format which already can be stored compressed and can be reused which is also true of knime tables themselves.
Next idea could be to work with chunks or partitions. Here also parquet could play a role along with the local big data nodes of knime. Maybe not the most straightforward solution but maybe you can think about that.
Then you might have to think about the whole setup again and get an idea when to do what with which chunk of data. If you elaborate more on your setup we could try to brainstorm some.
Hi @mlauber71 thanks so much for taking the time to reply.
I tried zipping a file today (in another workflow that needed attention - with a very large csv and ticking the compression option). Unfortunately, trying to unzip it over my VPN has been running for over an hour and reportedly still has 1.5 hours to go! So, though the writing of the compressed csv was much quicker - it doesn’t solve the outstanding problem. In other words even if I zip the outputs I’ve got the network issue.
I have used the parquet format, and used the copy/move node to achieve writing the parquet file to my network (which is not directly possible in the parquet writer). This indeed may be an option.
I agree that I need to revisit the whole setup as the reason I’m trying to save in Excel is because of the difficulties I had with date formats being incompatibly read back in from a saved csv. Maybe parquet will work better as a base file with new Excel read data.
My network limitations at the moment make development extremely challenging as testing anything takes so long I’ve nearly forgotten what I was testing by the time the outputs are ready! I may just have to abandon until I off the VPN and back in the office…
I will keep the thread updated with developments.
Thanks again for your interest and suggestions!
@zedleb, the slow network may be a result of antivirus. As for .xls file zipping is not suppose to work as .xls file is a zipped .xml file. Possibly you can fix date format in KNIME and create new CSV to be used without problem. Anyway all these are not a KNIME issues.
If writing a csv file is faster in our network, I agree with @izaychik63 that fixing the date formats in a way compatible to your csv should be a good solution. Can you describe a bit more how is your date format and why it is not compatible?
I’ve had a chance to work properly on the workflow and yes - I’ve got it working well at last. Compressing the csv is a great help too.
The date formats were an incredible headache but more because I had to read and write and each time I would get very confused. I resolved this by having a permanent clean import and then a local and network read and write (during the development)
I would like to keep the options to read and write both locally and to/from the network and thought I could put the CSV writer outside the component but don’t know how to put the File Readers (which read the compressed CSVs) outside the component or someway of allowing a selection outside of the component.
I’ll keep researching this - but if anyone has a quick solution it’s most appreciated!
Thanks for the all the support.
I have a separate question about File Reader but I will put that as a new issue
 with the format of dates between the two file formats…
with the format of dates between the two file formats…