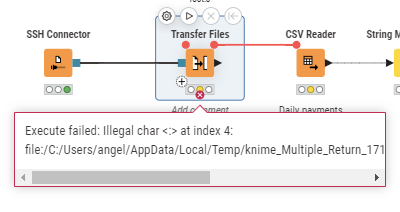
After updating KNIME to 5.3.3 I’m getting the following error for a Transfer Files node and also for some CSV Reader nodes.
Execute failed: Illegal char <:> at index 4: file:/C:/Users/angel/AppData/Local/Temp/knime_Multiple_Return_17182/knime_container_20241204_12886502894504530348.parquet
This mention a .parquet file but this workflow does not use any parquet (reader or writer).
If I try the same configuration but in a new workflow it works, but if I move the nodes from the new workflow to the original it breaks again. It’s like if the workflow is corrupted or something like that.
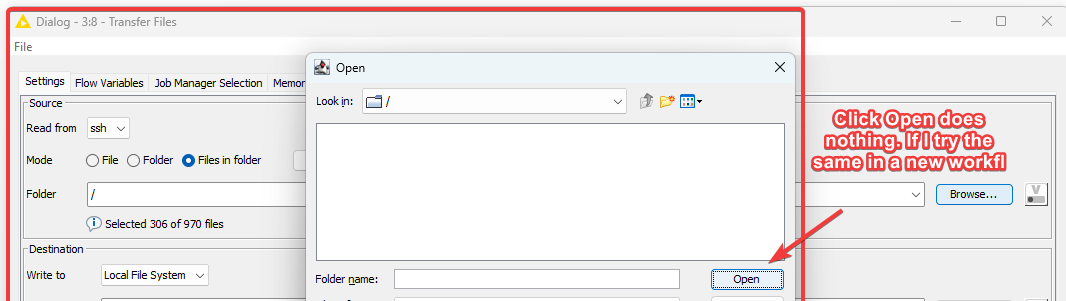
If I try to update the Transfer Files node, it won’t let me choose a folder. If I try the same in a new workflow, then it works.
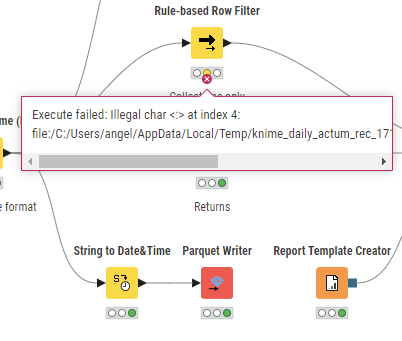
Same error for a rule-based row filter node in another workflow:
Execute failed: Illegal char <:> at index 4: file:/C:/Users/angel/AppData/Local/Temp/knime_daily_actum_rec_17184/knime_container_20241204_862886561881133400.parquet
are you using “KNIME Column Storage (based on Apache Parquet)” as your Row-based Table Backend implementation? It’s not actively maintained anymore and should not be used. The default Row-based Backend or Columnar Backend (which does not use Parquet), should be used.
Does using the default Row-based Backend implementation or uninstalling the extension outright solve the problem? In both cases, I think you have to reset the full workflow, though .
Don’t worry, the Parquet Reader and Writer are part of a separate extension “KNIME Extension for Big Data File Formats” and are unrelated to your error.
Also, can you check the KNIME Log for some more info around the error message you are seeing here? This could help to pinpoint the problem quicker.
You can find it via “Menu” → “Show KNIME Log in File Explorer”.
OK interesting. Mabye there should be some sort of warning if there are workflows that still use it. From my recollection there always have been problems with the parquet based data containers. Parquet itself is a fine format but maybe not all KNIME types and functions are well suited to be stored with that.
To be clear, there’s nothing wrong with the extension in terms of correctness. At least we’re not aware of any data integrity/correctness bugs resulting from using it. It’s just that it has no material benefit that I know of over the default KNIME table storage (custom + snappy compressed) for the Row-based backend, so I advised against using it. My intention was to isolate the cause for the error message and to see if the mention of .parquet is coincidental and would also occur with .bin.snappy or .knable (if other Table backends are used).
I think your particular workflow still used the Row-Backend with Parquet storage. It’s accessible via the gear icon when you view the workflow metadata.
The setting you can change via the preferences is only the default backend setting, but not the storage used in the row backend.
That’s why it worked for new workflows but not as soon as you pasted the node into the affected workflow, because that one was still using the parquet storage.
I’m glad it’s resolved, but I’ll still try to figure out what the root cause is. Thank you for responding that it was the problem
To be honest, it’s a bit confusing that the one thing is named „Columnar backend“ and the other is „Column Storage based on Parquet“, where the latter is just the on disk format for the Row-based backend. The on-disk format for the Columnar Backend is actually Arrow (another excellent data format).